연습 - Jupyter Notebook에 Kafka 데이터를 스트리밍하고 데이터 시간 범위 지정
이제 Kafka 클러스터는 Spark 구조적 스트리밍을 통해 처리할 수 있는 로그에 데이터를 기록하고 있습니다.
복제한 샘플에 Spark Notebook이 포함되어 있으므로 이를 사용하려면 해당 Notebook을 Spark 클러스터에 업로드해야 합니다.
Spark 클러스터에 Python Notebook 업로드
Azure Portal에서 홈 > HDInsight 클러스터를 클릭하고 방금 만든 Spark 클러스터를 선택합니다(Kafka 클러스터 아님).
클러스터 대시보드 창에서 Jupyter Notebook을 클릭합니다.

로그인 정보를 입력하라는 메시지가 표시되면 관리자의 사용자 이름을 입력하고 클러스터를 만들 때 만든 암호를 입력합니다. Jupyter 웹 사이트가 표시됩니다.
PySpark를 클릭한 다음 PySpark 페이지에서 업로드를 클릭합니다.
GitHub에서 샘플을 다운로드한 위치로 이동하여 RealTimeStocks.ipynb 파일을 선택한 다음 열기를 클릭하고 업로드를 클릭한 다음 인터넷 브라우저에서 새로 고침을 클릭합니다.
PySpark 폴더에 Notebook을 업로드한 후 RealTimeStocks.ipynb를 클릭하여 브라우저에서 Notebook을 엽니다.
첫 번째 셀에 커서를 놓고 Shift + Enter를 클릭하여 셀을 실행합니다.
다음 화면 캡션에 보이는 것처럼 시작 Spark 애플리케이션 메시지와 추가 정보를 표시하면 라이브러리 및 패키지 구성 셀이 성공적으로 완료됩니다.
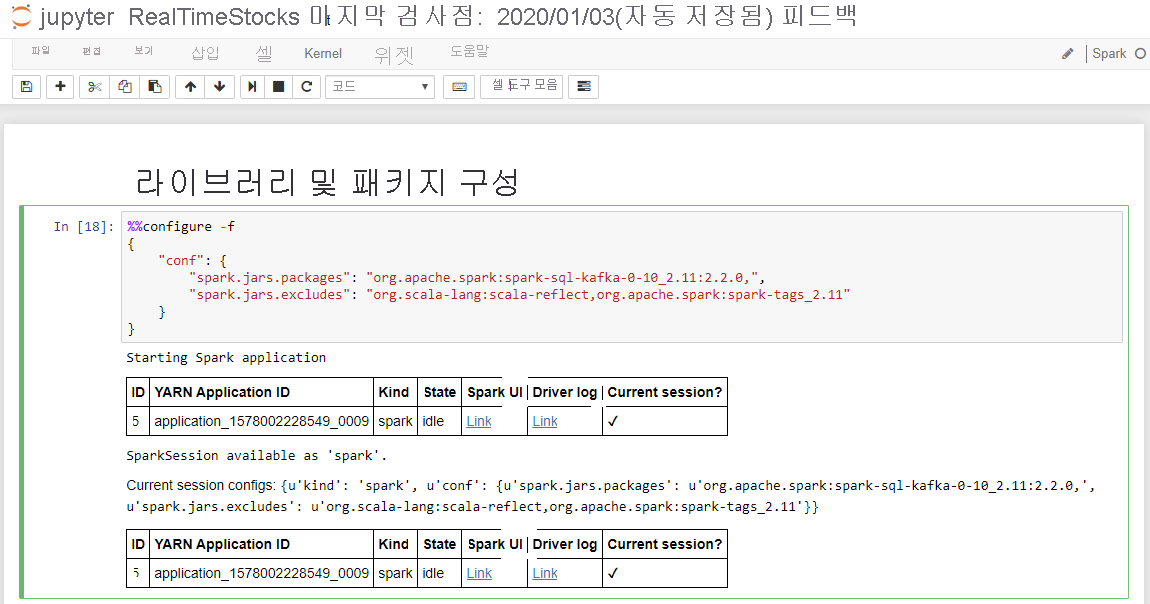
Kafka와 연결 설정셀의 .option("kafka.bootstrap.servers", "") 줄에서 두 번째 따옴표 세트 사이에 Kafka broker를 입력합니다. 예를 들어 모바일 서비스는 스크립트 실행 간에 상태를 유지하지 않으므로 스크립트 실행 간에 지속되어야 하는 모든 데이터를 테이블에 저장해야 합니다. .option("kafka.bootstrap.servers", "wn0-kafka.mdlamldganads.gx.internal.cloudapp.net:9092")를 입력하고 Shift + Enter를 클릭하여 셀을 실행합니다.
Kafka와의 연결 설정은 다음 메시지가 표시되면 성공적으로 완료됩니다. inputDf: org.apache.spark.sql.DataFrame = [key: binary, value: binary ... 5 more fields]. Spark는 readStream API를 사용하여 데이터를 읽습니다.
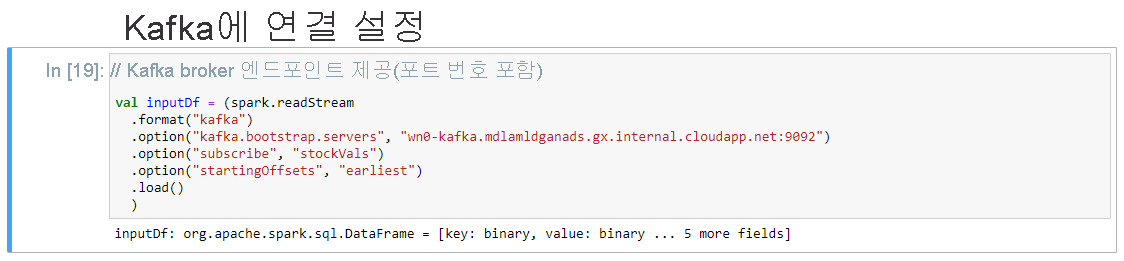
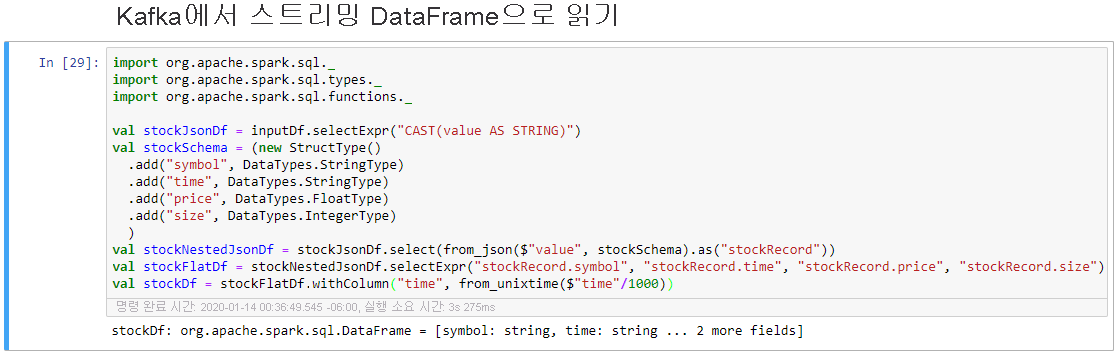
Kafka에서 Streaming Dataframe으로 읽기셀을 선택한 다음 Shift + Enter를 클릭하여 셀을 실행합니다.
셀이 성공적으로 완료되면 다음과 같은 메시지가 표시됩니다. stockDf: org.apache.spark.sql.DataFrame = [symbol: string, time: string ... 2 more fields]
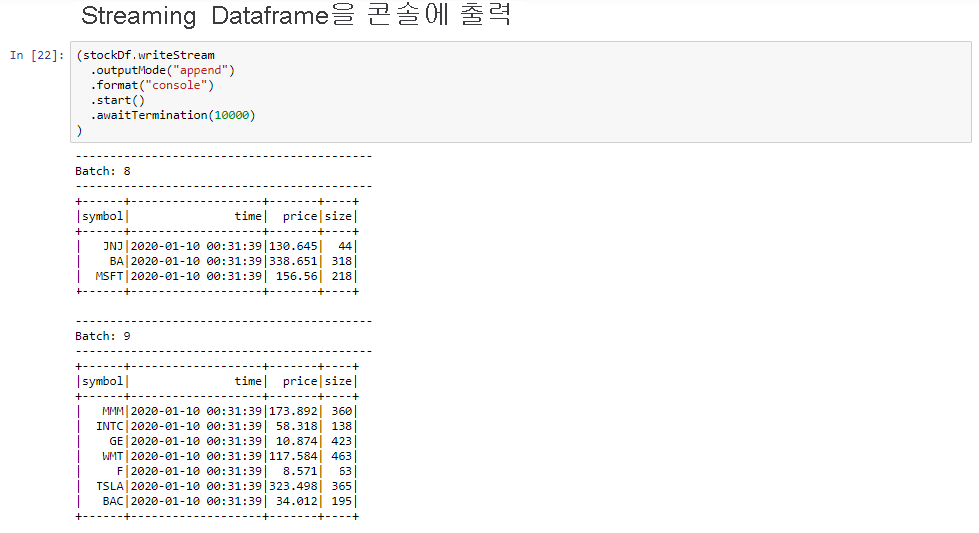
Streaming Dataframe을 콘솔로 출력하기 셀을 선택한 다음 Shift + Enter를 클릭하여 셀을 실행합니다.
셀이 다음과 유사한 정보를 표시하면 성공적으로 완료됩니다. 출력에는 마이크로 일괄 처리로 전달된 각 셀의 값이 표시되고, 초당 하나의 일괄 처리가 있습니다.
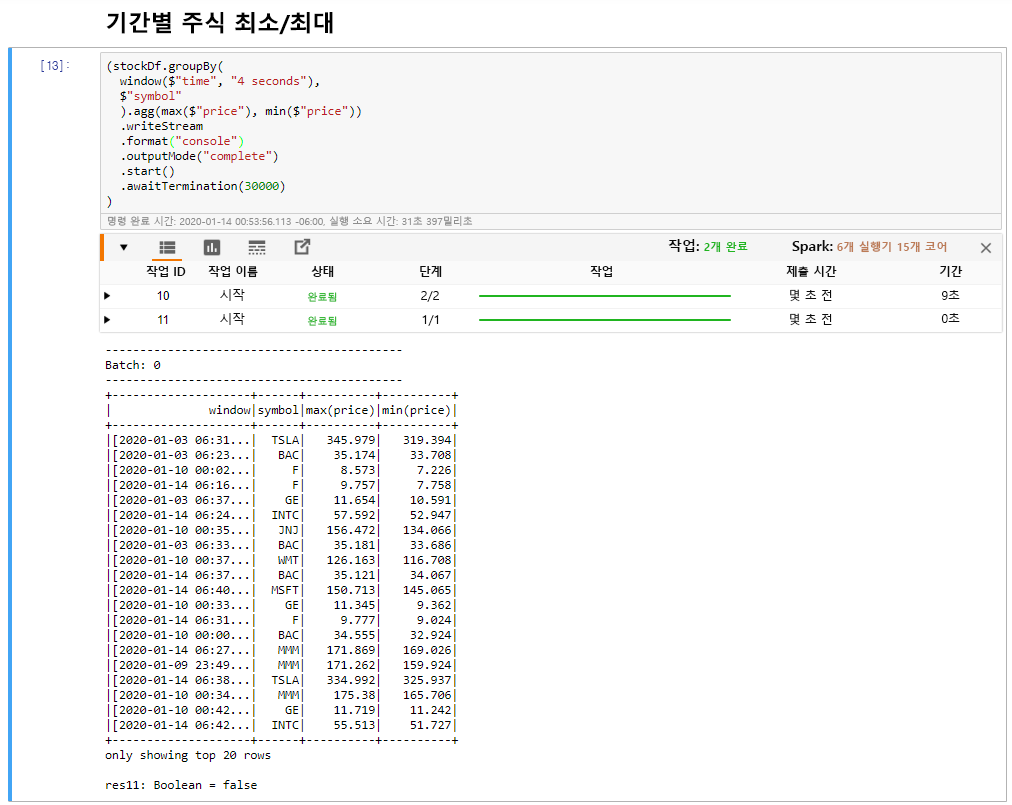
Windowed Stock Min/Max 셀을 선택한 다음 Shift + Enter를 클릭하여 셀을 실행합니다.
셀에 정의된 4초 범위에서 각 주식의 최대 및 최소 가격을 제공하면 셀은 성공적으로 완료됩니다. 이전 단원에서 설명한 대로 특정 시간 범위에 대한 정보를 제공하는 것은 Spark 구조적 스트리밍을 사용하여 얻을 수 있는 이점 중 하나입니다.
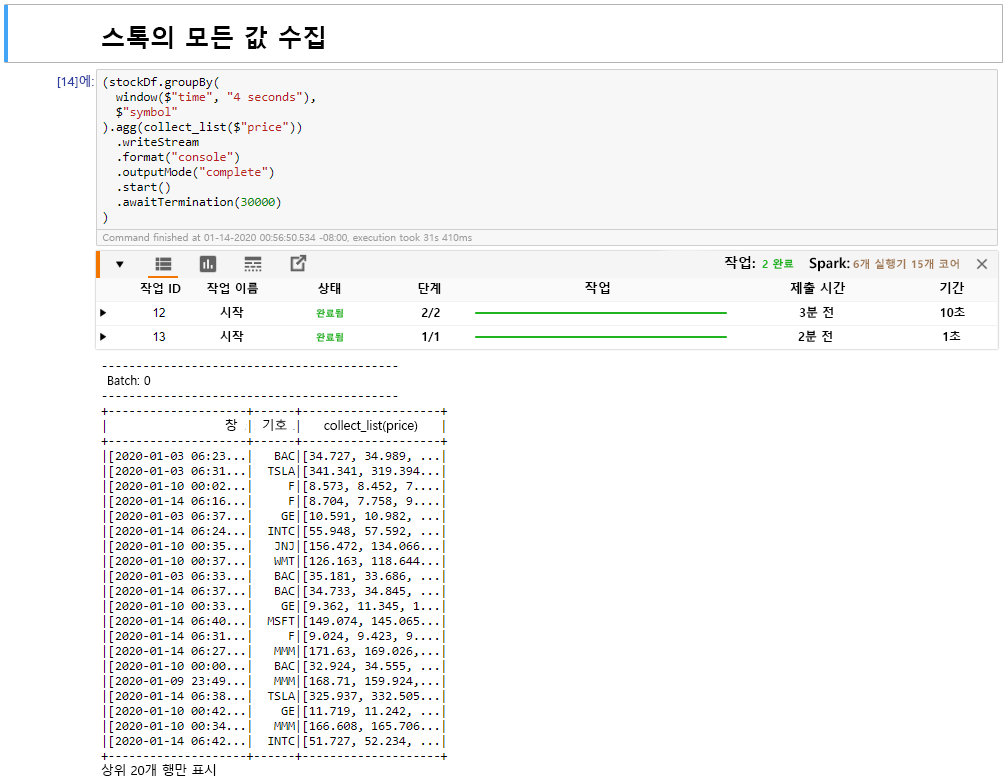
범위 셀에서 주식의 모든 값 수집을 선택한 다음 Shift + Enter를 클릭하여 셀을 실행합니다.
테이블에 주식에 대한 값 테이블을 제공하면 셀이 성공적으로 완료됩니다. OutputMode가 완료되어 모든 데이터가 표시됩니다.
이 단원에서는 Jupyter Notebook을 Spark 클러스터에 업로드하고, 이를 Kafka 클러스터에 연결하였습니다. Python 생산자 파일이 생성하는 스트리밍 데이터를 Spark Notebook에 출력하고, 스트리밍 데이터에 대한 시간 범위를 정의하였으며, 해당 범위에 최고 및 최저 주가를 표시하고, 테이블에 주식의 모든 값을 표시해 보았습니다. 축하합니다. Spark 및 Kafka를 사용하여 구조적 스트리밍을 성공적으로 수행했습니다!