Azure AI Search 솔루션의 성능 최적화
검색 솔루션 성능은 인덱스의 크기와 복잡성에 영향을 받을 수 있습니다. 또한 효율적인 쿼리를 작성하여 검색하고 올바른 서비스 계층을 선택하는 방법도 알아야 합니다.
여기서는 이러한 모든 차원을 살펴보고 검색 솔루션의 성능을 개선하기 위해 수행할 수 있는 단계를 살펴봅니다.
현재 검색 성능 측정
검색 서비스가 얼마나 잘 수행되는지 모를 때는 최적화할 수 없습니다. 개선 사항의 유효성을 검사할 수 있도록 기준 성능 벤치마크를 만들지만 시간이 지남에 따라 성능 저하를 확인할 수도 있습니다.
먼저 Log Analytics를 사용하여 진단 로깅을 사용하도록 설정합니다.
- Azure Portal에서 진단 설정을 선택합니다.
- + 진단 설정 추가를 선택합니다.

- 진단 설정에 이름을 지정합니다.
- allLogs 및 AllMetrics를 선택합니다.
- Log Analytics 작업 영역에 보내기를 선택합니다.
- Log Analytics 작업 영역을 선택하거나 만듭니다.
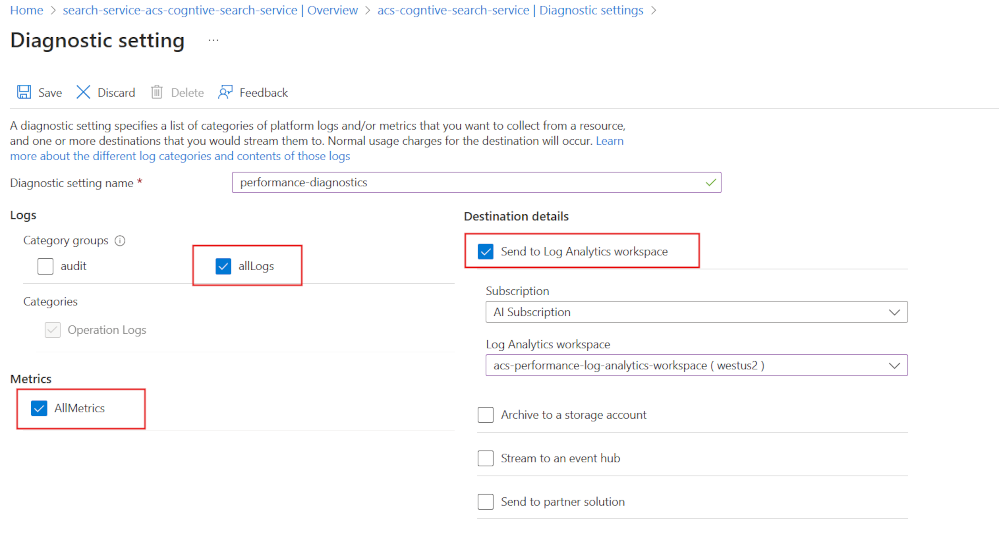
검색 서비스 수준에서 이 진단 정보를 캡처하는 것이 중요합니다. 최종 사용자 또는 앱이 성능 문제를 볼 수 있는 여러 위치가 있기 때문입니다.

검색 서비스가 잘 수행되고 있음을 증명할 수 있는 경우 성능 문제가 있다면 가능한 요인에서 검색 서비스를 제거할 수 있습니다.
검색 서비스가 제한되었는지 확인
Azure AI Search 검색 및 인덱스를 제한할 수 있습니다. 사용자 또는 앱의 검색이 제한된 경우 503 HTTP 응답을 사용하여 Log Analytics에서 캡처됩니다. 인덱스가 제한되는 경우 207 HTTP 응답으로 표시됩니다.
검색 서비스 로그에 대해 실행할 수 있는 이 쿼리는 검색 서비스가 제한되고 있는지를 보여 줍니다.

Azure Portal의 모니터링에서 로그를 선택합니다. 새 쿼리 1 탭에서는 다음 쿼리를 사용합니다.
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
명령을 실행하여 검색 서비스 HTTP 응답의 막대형 차트를 확인합니다. 위에서는 503 응답이 여러 개 있음을 알 수 있습니다.
개별 쿼리의 성능 확인
개별 쿼리 성능을 테스트하는 가장 좋은 방법은 Postman과 같은 클라이언트 도구를 사용하는 것입니다. 쿼리에 대한 응답에서 헤더를 표시하는 도구를 사용할 수 있습니다. Azure AI Search는 서비스가 쿼리를 완료하는 데 걸린 시간에 대해 항상 '경과된 시간' 값을 반환합니다.

클라이언트에서 응답을 보내고 받는 데 걸리는 시간을 알고 싶다면 총 왕복에서 경과된 시간을 뺍니다. 위에서는 125ms - 21ms로, 104ms입니다.
인덱스 크기 및 스키마 최적화
검색 쿼리의 수행 방식은 인덱스의 크기와 복잡성에 직접 연결됩니다. 인덱스가 더 작고 최적화될수록 빠른 Azure AI Search가 쿼리에 응답할 수 있습니다. 개별 쿼리에 성능 문제가 있는 경우 도움이 될 수 있는 몇 가지 팁은 다음과 같습니다.
주의를 기울이지 않으면 시간이 지남에 따라 인덱스가 증가할 수 있습니다. 인덱스 내의 모든 문서가 여전히 관련이 있으며 검색할 수 있어야 한다는 점을 검토해야 합니다.
문서를 제거할 수 없는 경우 스키마의 복잡성을 줄일 수 있나요? 검색할 수 있으려면 여전히 동일한 필드가 필요한가요? 인덱스로 시작한 모든 기술 세트가 여전히 필요한가요?

각 필드에서 사용하도록 설정한 모든 특성을 검토하는 것이 좋습니다. 예를 들어 필터, 패싯, 정렬에 대한 지원을 추가하면 인덱스를 지원하는 데 필요한 스토리지가 4배로 늘어나게 됩니다.
참고
필드에 특성이 너무 많으면 해당 기능이 제한됩니다. 예를 들어 패싯 가능하고 필터링 가능하며 검색 가능한 필드에서는 16KB만 저장할 수 있습니다. 검색 가능한 필드는 최대 16MB의 텍스트를 보유할 수 있습니다.
인덱스가 최적화되었지만 성능이 필요한 위치가 아닌 경우 검색 서비스를 스케일 업하거나 스케일 아웃하도록 선택할 수 있습니다.
쿼리 성능 개선
검색 서비스의 작동 방식을 알고 있는 경우 쿼리를 조정하여 성능을 크게 향상시킬 수 있습니다. 더 나은 쿼리를 작성하려면 다음 검사 목록을 사용합니다.
- searchFields 매개 변수를 사용하여 검색해야 하는 필드만 지정합니다. 필드가 많을수록 추가 처리가 필요합니다.
- 검색 결과 페이지에서 렌더링해야 하는 가장 적은 수의 필드를 반환합니다. 더 많은 데이터를 반환하는 데 더 많은 시간이 걸립니다.
- 접두사 검색 또는 정규식과 같은 부분 검색 용어를 사용하지 않도록 합니다. 이러한 종류의 검색은 계산 비용이 더 많이 듭니다.
- 높은 건너뛰기 값을 사용하지 마세요. 이렇게 하면 검색 엔진이 더 많은 양의 데이터를 검색하고 순위를 지정합니다.
- 패싯 가능 및 필터링 가능한 필드 사용을 낮은 카디널리티 데이터로 제한합니다.
- 필터 조건의 개별 값 대신 검색 함수를 사용합니다. 예를 들어
$filter=userid eq 123 or userid eq 143 or userid eq 563 or userid eq 121대신search.in(userid, '123,143,563,121',',')을 사용할 수 있습니다.
위의 모든 항목을 적용했고 수행되지 않는 개별 쿼리가 여전히 있는 경우 인덱스를 스케일 아웃할 수 있습니다. 검색 솔루션을 만드는 데 사용한 서비스 계층에 따라 최대 12개의 파티션을 추가할 수 있습니다. 파티션은 인덱스가 있는 실제 스토리지입니다. 기본적으로 모든 새 검색 인덱스는 단일 파티션으로 만들어집니다. 파티션을 더 추가하면 인덱스가 파티션 전체에 저장됩니다. 예를 들어 인덱스가 200GB이고 파티션이 4개인 경우 각 파티션에는 50GB의 인덱스가 포함됩니다.
추가 파티션을 추가하면 검색 엔진이 각 파티션에서 병렬로 실행할 수 있으므로 성능에 도움이 될 수 있습니다. 많은 수의 문서에 대한 개수를 제공하는 패싯을 사용하는 많은 수의 문서 및 쿼리를 반환하는 쿼리에 대해 가장 향상된 사항을 확인할 수 있습니다. 이는 문서의 관련성 점수를 매기는 데 계산 비용이 많이 드는 요소입니다.
검색 요구 사항에 가장 적합한 서비스 계층 사용
파티션을 더 추가하여 서비스 계층을 스케일 아웃할 수 있습니다. 부하가 증가하여 스케일링해야 하는 경우 복제본을 사용하여 스케일 아웃할 수 있습니다. 더 높은 계층을 사용하여 검색 서비스를 스케일 업할 수도 있습니다.

위의 두 검색 인덱스의 크기는 200GB입니다. S1 계층은 8개의 파티션을 사용하고 S2 계층에는 2개만 있습니다. 둘 다 두 개의 복제본을 가지고 있으며 둘 다 거의 동일한 비용이 듭니다. 검색 솔루션에 가장 적합한 계층을 선택하려면 필요한 대략적인 총 스토리지 크기를 알아야 합니다. 현재 지원되는 가장 큰 인덱스는 총 24TB를 제공하는 L2 계층의 12개 파티션입니다.
| 계층 | Type | 스토리지 | 복제본 | 파티션 |
|---|---|---|---|---|
| F | Free | 50MB | 1 | 1 |
| b | Basic | 2GB | 3 | 1 |
| S1 | Standard | 25GB/파티션 | 12 | 12 |
| S2 | Standard | 100GB/파티션 | 12 | 12 |
| S3 | Standard | 200GB/파티션 | 12 | 12 |
| S3HD | 고밀도 | 200GB/파티션 | 12 | 3 |
| L1 | 스토리지 최적화 | 1TB/파티션 | 12 | 12 |
| L2 | 스토리지 최적화 | 2TB/파티션 | 12 | 12 |
위의 예제에서 위의 두 계층 중 가장 잘 수행한다고 생각하는 계층은 무엇입니까? 스케일 아웃은 병렬 처리로 인해 성능상의 이점을 제공한다는 것을 살펴보았습니다. 그러나 상위 계층에는 프리미엄 스토리지, 더 강력한 컴퓨팅 리소스, 추가 메모리도 함께 제공됩니다. 두 번째 옵션을 선택하면 더 강력한 인프라를 제공하고 향후 인덱스 증가를 허용합니다. 아쉽게도 가장 잘 수행하는 계층은 인덱스의 크기와 복잡성 및 검색을 위해 작성하는 쿼리에 따라 달라집니다. 그래서 어느 쪽도 최고가 될 수 있습니다.
검색 솔루션 사용의 향후 성장을 계획하는 것은 검색 단위를 고려해야 한다는 것을 의미합니다. SU(검색 단위)는 복제본 및 파티션의 제품입니다. 즉, 위의 S1 계층은 16SU를 사용하고 S2 계층은 4SU에 불과합니다. 비용은 더 높은 계층이 SU당 더 많은 요금을 청구하는 것과 유사합니다.
부하가 증가하여 검색 솔루션을 스케일링해야 하는 경우를 생각해 보세요. 두 계층에 다른 복제본을 추가하면 S1 계층이 24SU 로 증가하지만 S2 계층은 6SU로만 증가합니다.