Azure HDInsight 작동 방식
여기서는 Azure HDInsight의 작동 방식에 대해 알아봅니다. 다음 구성 요소에 대해, 그리고 이 구성 요소를 함께 사용하여 데이터 컨트롤 및 관리를 제공하는 방법을 알아봅니다.
- Apache Hadoop
- HDInsight 스토리지
- HDInsight 처리
Apache Hadoop이란?
Apache Hadoop은 HDInsight의 중심에 있는 클라우드 분산형 데이터 처리 시스템입니다. 다음 표에서 설명하는 세 가지 구성 요소가 있습니다.
| Apache Hadoop 구성 요소 | Description |
|---|---|
| HDFS | Apache HDFS(Hadoop 분산 파일 시스템)는 Hadoop 시스템용 스토리지를 제공합니다. |
| YARN | Apache Hadoop YARN(Yet Another Resource Negotiator) 구성 요소는 시스템에 대한 처리를 제공합니다. |
| MapReduce | MapReduce는 데이터를 처리하고 분석하는 데 사용할 수 있는 프로그래밍 모델입니다. |
구성 요소의 상호 작용 방식
다음 다이어그램은 일반적인 HDInsight Hadoop 클러스터에서 상호 작용하는 스토리지 및 처리 구성 요소를 보여 줍니다. 다음 구성 요소를 보여 줍니다.
- 처리를 수행하는 헤드 노드 및 작업자 노드.
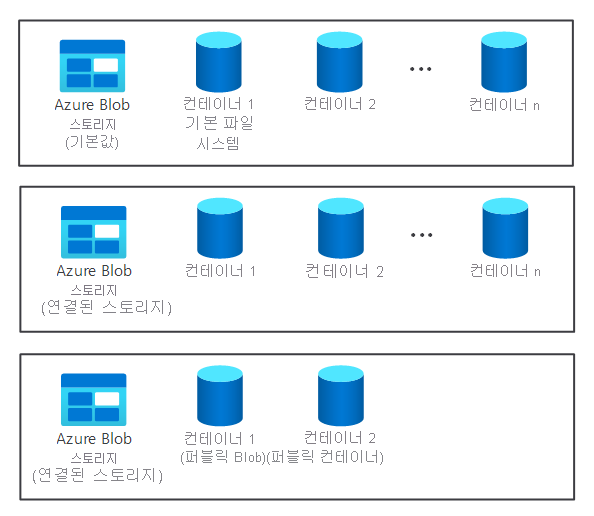
- 노드 내의 여러 WASB(Azure Storage Blob) 스토리지 센터. HDFS는 다음 컨테이너와 상호 작용합니다.
- 여러 기본, 연결/연결되지 않은 스토리지 컨테이너. 두 노드에서 사용할 수 있습니다.
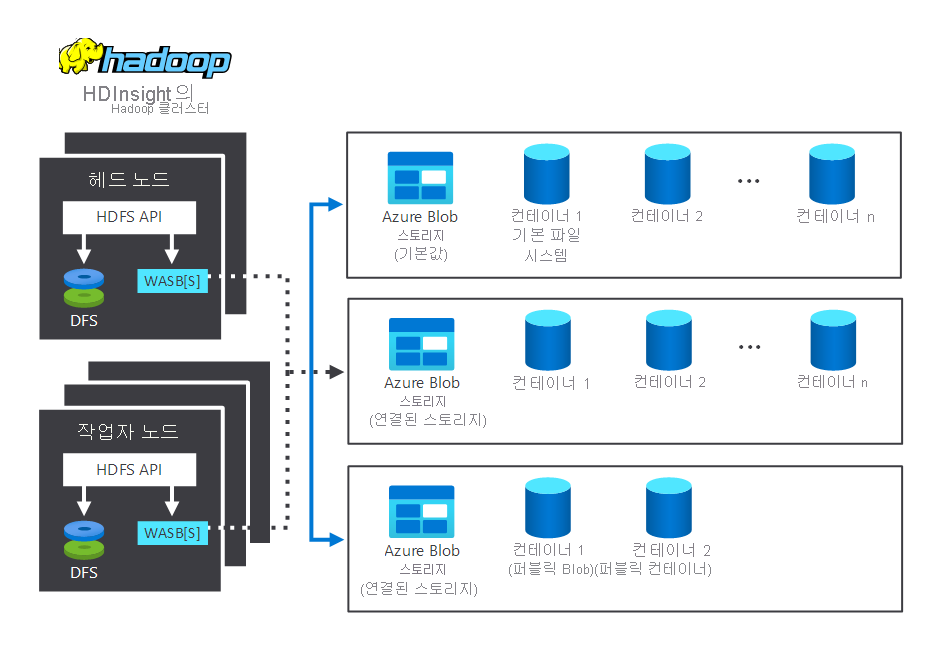
이제 스토리지 및 처리가 작동하는 방식을 살펴보겠습니다.
스토리지 작동 방식
클러스터의 스토리지 구성 요소는 HDInsight 클러스터를 프로비저닝할 때 자동으로 생성되지 않습니다. 대신, Azure Storage 또는 Azure Data Lake와 같은 HDFS 규격 시스템에서 제공됩니다.
클러스터의 스토리지 구성 요소를 처리 구성 요소와 분리하면 이점이 있습니다. 예를 들어 데이터 손실을 걱정하지 않고 계산에만 사용되는 HDInsight 클러스터를 안전하게 삭제할 수 있습니다. HDInsight 클러스터를 추가하는 경우 기본 파일 시스템을 정의해야 합니다.
중요
Azure Storage의 경우 Blob 컨테이너를 기본 파일 시스템으로 지정해야 합니다.
기본 파일 시스템을 제공하면 파일을 검색할 때 HDInsight가 상대 파일 참조를 확인할 수 있습니다.
팁
사용 가능한 용량을 늘리려는 경우 필요에 따라 추가 파일 시스템을 연결하고 연결을 해제할 수 있습니다.
처리 작동 방식
데이터를 처리할 때 HDInsight의 Hadoop 클러스터 컴퓨팅 구성 요소는 두 개의 논리 영역으로 나뉩니다. 다음 표에서는 이 두 영역에 관해 설명합니다.
| 구성 요소 | Description |
|---|---|
| 헤드 노드 | 헤드 노드는 클라이언트 요청을 수락 및 관리하고 요청을 작업자 노드에 전달합니다. |
| 작업자 노드 | 작업자 노드는 데이터를 처리합니다. |
참고
헤드 노드는 경우에 따라 마스터 노드라고도 합니다.
대부분의 클러스터에는 다음을 포함한 두 개의 헤드 노드가 있습니다.
- 활성 헤드 노드 - 클라이언트 연결을 관리합니다.
- 수동 헤드 노드 - 활성 노드가 오프라인 상태가 되는 경우 복원력을 제공합니다.
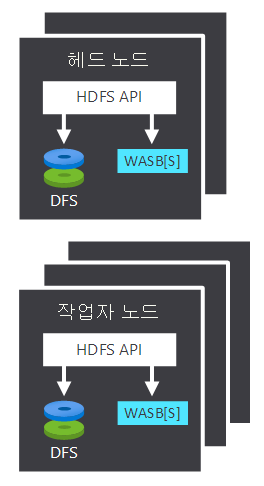
헤드 노드와 작업자 노드는 모두 로컬로 연결된 HDFS에 직접 연결되거나, Azure Blob 또는 Azure Data Lake에 저장된 데이터에 액세스할 수 있습니다. 관리되는 데이터는 다음 두 요인에 따라 다릅니다.
- MapReduce 프로그래밍 모델이 데이터를 작업하는 방법의 정의.
- 헤드 노드가 작업을 할당하는 방법.
YARN의 기능
YARN은 HDInsight 클러스터 내에서 리소스 관리를 수행합니다. 데이터 처리 시 이 서비스는 리소스 및 작업 예약을 관리합니다.
YARN은 HDFS와 HDInsight 클러스터의 계산 시스템 사이에 배치됩니다. 헤드 노드와 연동하여 클러스터의 작업자 노드에 작업을 분산할 수 있습니다. 이렇게 하면 데이터 처리 작업이 병렬로 발생할 수 있습니다.