Azure HDInsight란?
HDInsight의 기능 및 사용을 검토해 보겠습니다. 이 개요는 HDInsight가 조직의 요구 사항을 해결하는지를 평가하는 데 도움이 됩니다.
빅 데이터란?
‘빅 데이터’라는 용어는 조직이 수집하는 방대한 양의 정형 데이터와 비정형 데이터를 ‘모두’ 설명합니다. 이 데이터는 조직에 매우 유용할 수 있습니다. 특히, 조직에서 인사이트에 대한 데이터를 분석할 수 있는 경우 더 잘 결정할 수 있습니다. 따라서 이러한 결정을 통해 조직은 더 성공을 거둘 수 있습니다. 예를 들어 상용 조직은 빅 데이터 분석을 사용하여 고객 습관을 인식할 수 있으며 이에 따라 판매량이 증가할 수 있습니다.
Azure HDInsight 정의
Azure HDInsight는 엔터프라이즈용 완전 관리형 클라우드 기반 오픈 소스 분석 서비스입니다. HDInsight를 사용하여 빅 데이터를 제어하고 관리할 수 있습니다. HDInsight:
Hadoop 구성 요소의 클라우드 배포 버전입니다.
더 쉽고 빠르며 비용 효율적으로 대량의 데이터를 처리할 수 있습니다.
다음과 같은 오픈 소스 프레임워크를 사용하도록 지원합니다.
- Hadoop은
- Apache Spark
- Apache Hive
- Apache Kafka
참고
이러한 프레임워크를 사용하면 추출, 변환 및 로드(ETL), 데이터 웨어하우징, Machine Learning, IoT와 같은 광범위한 시나리오를 사용할 수 있습니다.
HDInsight는 빅 데이터로 작업하는 조직에게 몇 가지 이점을 제공합니다. 먼저,
오픈 소스: 따라서 다양한 오픈 소스 프레임워크에 대해 최적화된 클러스터를 만들 수 있습니다.
안정성:모든 프로덕션 워크로드에 대한 엔드투엔드 SLA를 제공합니다.
확장성: 수요 변화에 대응하여 워크로드를 스케일링할 수 있습니다.
팁
요구에 따라 클러스터를 만들어 비용을 줄일 수 있습니다. 사용한 만큼만 요금을 지불합니다.
안전성: 다음을 통합하여 엔터프라이즈 데이터 자산을 보호할 수 있습니다.
- Azure Virtual Network
- Azure 암호화 기술
- Microsoft Entra ID
규정 준수: 널리 사용되는 업계 및 정부 규정 준수 표준을 충족합니다.
모니터링됨: Azure Monitor 로그와 통합되어 단일 인터페이스를 제공합니다. 단일 인터페이스를 사용하여 모든 클러스터를 모니터링합니다.
HDInsight를 사용하여 빅 데이터로 작업하는 방법
빅 데이터 처리를 활용하는 다양한 시나리오에 HDInsight를 사용할 수 있습니다. 다음과 같은 데이터일 수 있습니다.
- 기록 데이터: 이 데이터는 이미 수집 및 저장되어 있습니다.
- 실시간 데이터: 이 데이터는 원본에서 직접 스트리밍됩니다.
이 데이터의 처리 시나리오는 다음과 같은 범주로 요약됩니다.
- 일괄 처리
- 데이터 웨어하우징
- IoT
- 데이터 과학
- 하이브리드
이러한 범주를 좀 더 자세히 살펴보겠습니다.
일괄 처리
조직은 일괄 처리 작업을 사용하여 추가 분석을 위해 빅 데이터를 준비합니다. 일반적으로 이 프로세스에는 다음 세 단계가 포함됩니다.
- 다른 유형의 데이터 원본에서 원본 데이터 파일을 읽습니다.
- 데이터를 처리합니다.
- 스케일링할 수 있는 스토리지에 데이터를 씁니다.
참고
이 프로세스를 종종 ETL이라고 합니다.
변환된 데이터를 데이터 웨어하우징 또는 데이터 과학에 사용할 수 있습니다.
팁
ETL의 중요 요구 사항은 컴퓨팅 스케일 아웃으로, 대용량 데이터 볼륨을 처리할 수 있게 합니다.
데이터 웨어하우징
데이터 웨어하우스는 조직에 데이터를 분석하기 위해 대기하는 동안 빅 데이터를 보관할 위치를 제공합니다. 데이터 웨어하우징을 통해 다음을 수행할 수 있습니다.
- 데이터를 저장합니다.
- 분석을 위해 데이터를 준비합니다.
- 준비된 데이터를 구조화된 형식으로 제공합니다. 그런 다음 분석 도구를 사용하여 데이터를 쿼리할 수 있습니다.
다음 다이어그램은 HDInsight의 Apache Hadoop을 통해 여러 원본의 데이터를 수집하고 저장하는 방법을 보여 줍니다. Apache Spark와 Apache Hive는 데이터를 준비하고 분석합니다. 마지막으로, 데이터는 BI(비즈니스 인텔리전스) 도구에서 사용할 수 있도록 모델링됩니다. Power BI는 데이터 시각화에 사용됩니다.
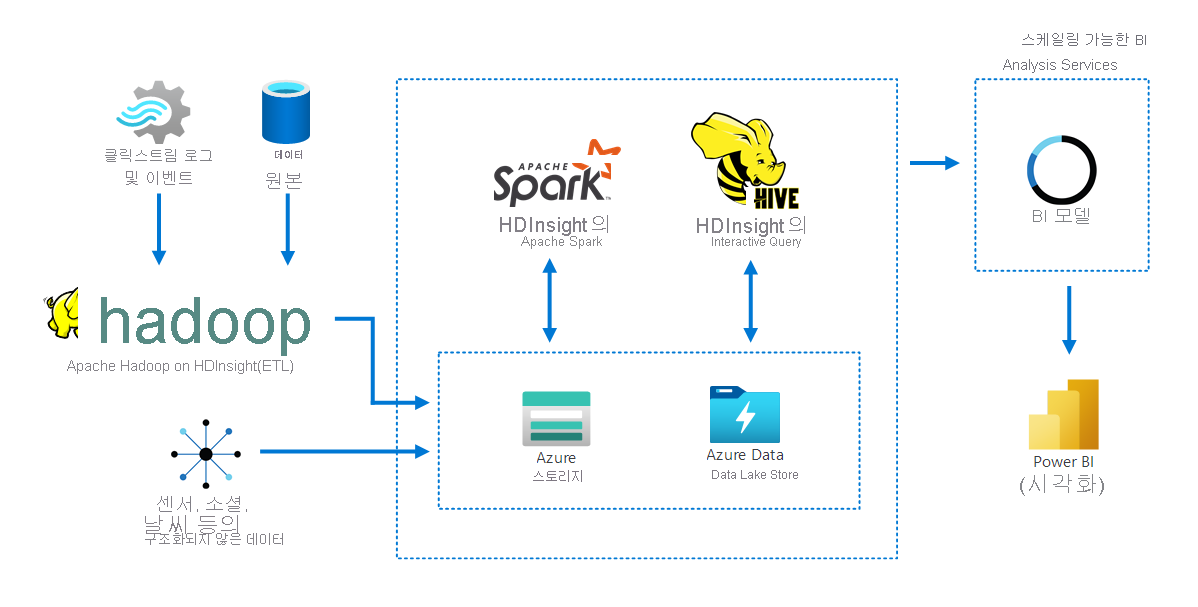
이 시나리오의 구성 요소는 다음과 같습니다.
- Apache Spark는 병렬 처리 프레임워크입니다. 빅 데이터 분석 애플리케이션의 성능을 향상하는 데 도움이 되는 메모리 내 처리를 지원합니다.
- HDInsight의 Apache Hive는 Apache Hadoop을 위한 데이터 웨어하우스 시스템입니다. Hive는 데이터 요약, 쿼리, 분석을 가능하게 합니다. 이 구성 요소를 사용하여 모든 형식의 정형 데이터 및 비정형 데이터에 대해 페타바이트 규모로 쿼리를 처리할 수 있습니다.
팁
Hive 쿼리는 SQL과 유사한 쿼리 언어인 HiveQL로 작성됩니다.
사물 인터넷
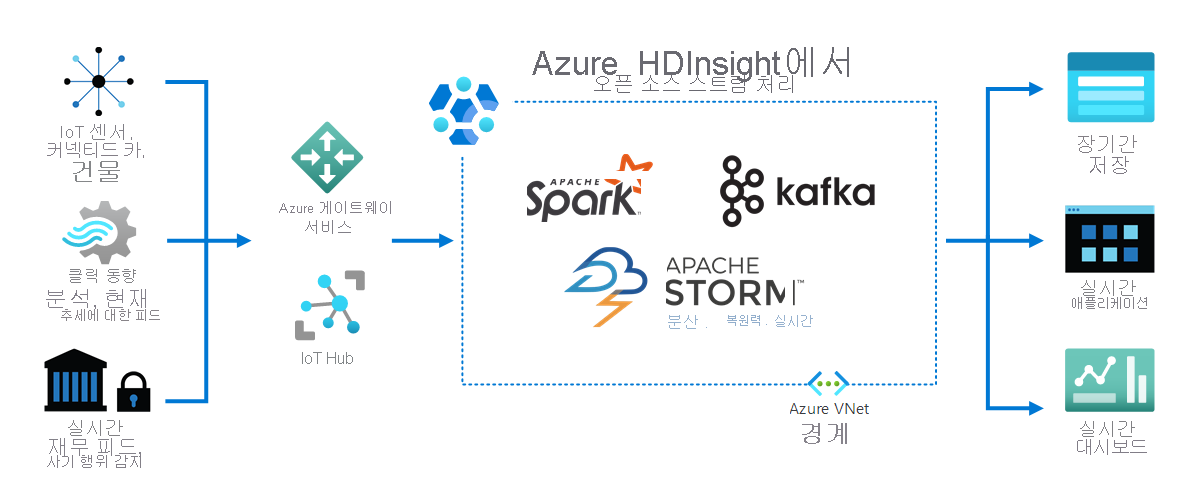
다음 다이어그램은 HDInsight가 다양한 디바이스와 센서에서 실시간으로 수신되는 스트리밍 데이터를 처리하는 것을 보여 줍니다. 이 예제에서는 Apache Spark와 Apache Kafka를 포함한 여러 오픈 소스 프레임워크에서 스트림 처리를 제공합니다.
Azure 게이트웨이 서비스 및 IoT 허브는 다양한 원본의 데이터를 이러한 프레임워크로 보냅니다. 그런 다음 해당 프레임워크는 데이터를 처리하고 다음으로 전달합니다.
- 장기 스토리지
- 실시간 앱.
- 실시간 대시보드.
데이터 과학
HDInsight를 사용하여 다음과 같은 일반적인 데이터 과학 작업을 완료할 수 있습니다.
- 데이터 수집.
- 기능 엔지니어링.
- 모델링.
- 모델 평가.
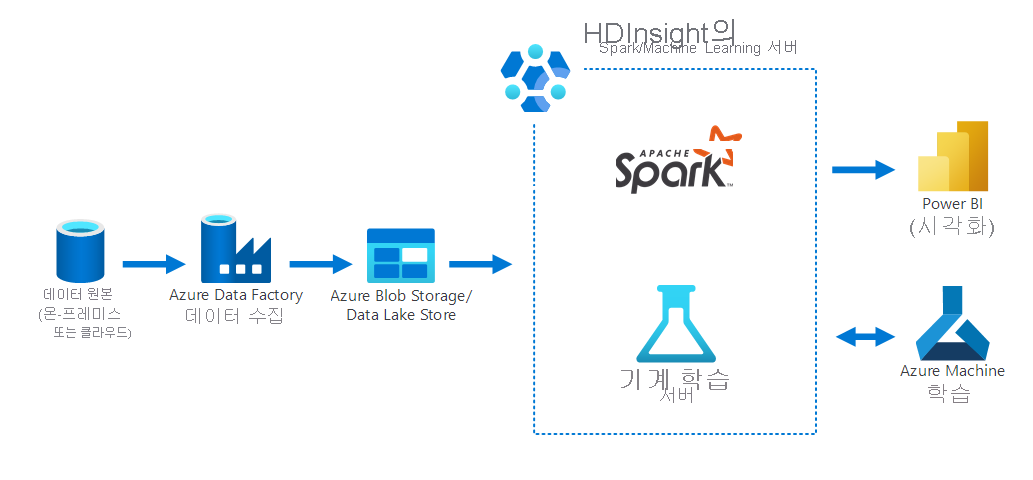
다음 다이어그램은 다음과 같은 데이터 과학 시나리오를 보여 줍니다.
- Azure Data Factory를 사용하여 온-프레미스 데이터 원본에서 데이터를 수집합니다.
- 수집된 데이터는 Azure 스토리지(Azure Blob Storage 또는 Data Lake Store)에 저장됩니다.
- HDInsight의 Azure Spark는 Azure Machine Learning을 위한 데이터를 처리하고 준비합니다. 또한 Power BI를 사용하여 데이터를 시각화합니다.
하이브리드
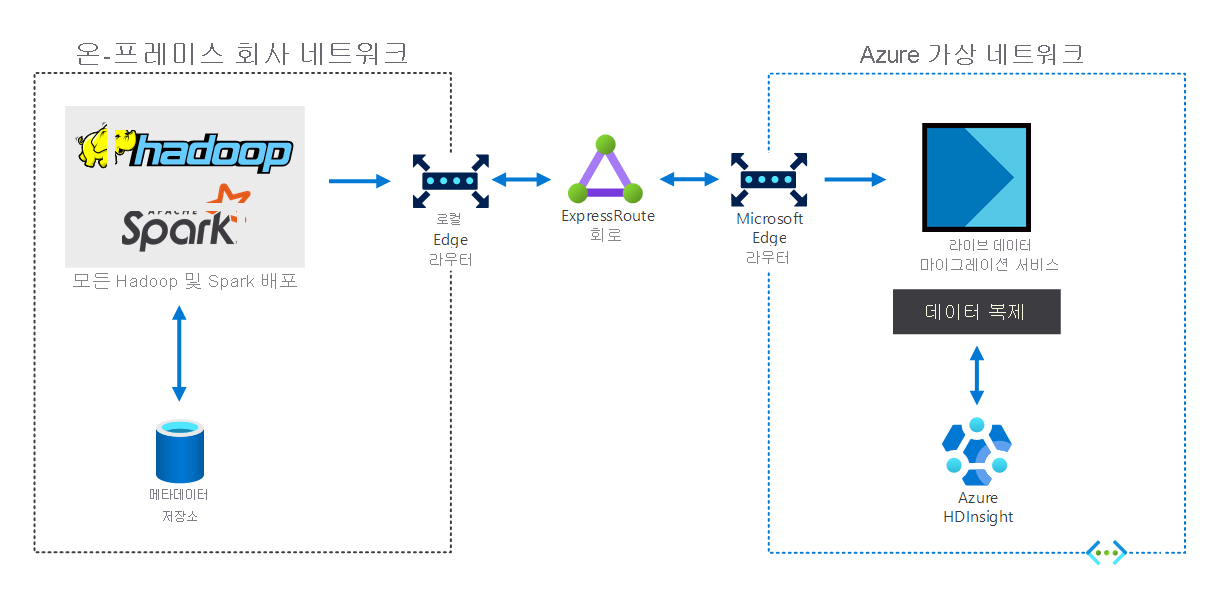
온-프레미스 빅 데이터 인프라가 있는 조직은 HDInsight를 사용하여 Azure로 확장할 수 있습니다. 이를 통해 Azure 클라우드의 고급 분석 기능의 이점을 누릴 수 있습니다. 다음 다이어그램은 다음과 같은 하이브리드 시나리오를 보여 줍니다.
- 온-프레미스 빅 데이터 인프라는 메타데이터 저장소와 로컬 VM의 Hadoop 또는 Spark 배포로 구성됩니다.
- Azure ExpressRoute 회로는 온-프레미스 회사 네트워크 환경을 Azure 가상 네트워크에 연결합니다.
- Azure용 실시간 데이터 마이그레이터는 온-프레미스에서 수신된 데이터를 HDInsight에 복제합니다.