Azure Data Factory 작동 방식
여기에서는 Azure Data Factory의 구성 요소와 상호 연결된 시스템과 그 작동 방식에 대해 알아봅니다. 이러한 지식은 조직의 요구 사항을 충족하기 위해 Azure Data Factory를 가장 잘 활용하는 방법을 결정하는 데 도움이 될 것입니다.
Azure Data Factory는 엔드투엔드 데이터 분석 플랫폼을 제공하기 위해 결합된 상호 연결된 시스템 컬렉션입니다. 이 단원에서는 다음 Azure Data Factory 함수에 관해 알아봅니다.
- 연결 및 수집
- 변환 및 보강
- CI/CD(연속 통합 및 지속적인 업데이트) 및 게시
- 모니터링
Azure Data Factory의 다음과 같은 주요 구성 요소에 대해서도 알아봅니다.
- 파이프라인
- 활동
- 데이터 세트
- 연결된 서비스
- 데이터 흐름
- 통합 런타임
Azure Data Factory 함수
Azure Data Factory는 데이터 엔지니어에게 완전한 데이터 분석 플랫폼을 제공하기 위해 결합된 여러 함수로 구성됩니다.
연결 및 수집
프로세스의 첫 번째 부분은 적절한 데이터 원본에서 필요한 데이터를 수집하는 것입니다. 이러한 원본은 온-프레미스 원본, 클라우드 등 다양한 위치에 있을 수 있습니다. 데이터는 다음 상태일 수 있습니다.
- 구조적
- 비구조적
- 반구조적
또한 개별 데이터는 서로 다른 속도와 간격으로 도착할 수 있습니다. Azure Data Factory를 사용하면 복사 작업을 사용하여 다양한 원본의 데이터를 클라우드의 중앙화된 단일 데이터 저장소로 이동할 수 있습니다. 데이터를 복사한 후에는 다른 시스템을 사용하여 데이터를 변환하고 분석합니다.
복사 작업은 다음과 같은 대략적인 단계를 수행합니다.
원본 데이터 저장소에서 데이터를 읽습니다.
탭에서 다음 작업을 수행합니다.
- Serialization/deserialization
- 압축/압축 풀기
- 열 매핑
참고
추가 작업이 있을 수 있습니다.
대상 데이터 저장소(‘싱크’라고 함)에 데이터를 씁니다.
이 프로세스는 다음 그래픽에 요약되어 있습니다.

변환 및 보강
데이터를 중앙 클라우드 기반 위치에 성공적으로 복사한 후에는 Azure Data Factory 매핑 데이터 흐름을 사용하여 필요에 따라 데이터를 처리하고 변환할 수 있습니다. ‘데이터 흐름’을 사용하면 Spark에서 실행되는 데이터 변환 그래프를 만들 수 있습니다. 그러나 Spark 클러스터 또는 Spark 프로그래밍을 이해하지 않아도 됩니다.
팁
필요하지는 않지만 변환을 수동으로 코딩하는 것이 좋을 수 있습니다. 이 경우 Azure Data Factory는 변환을 실행하기 위한 외부 활동을 지원합니다.
CI/CD 및 게시
CI/CD 지원을 통해 게시하기 전에 ETL(추출, 변환, 로드) 프로세스를 증분적으로 개발하고 제공할 수 있습니다. Azure Data Factory는 다음을 사용하여 데이터 파이프라인의 CI/CD를 위해 제공됩니다.
- Azure DevOps
- GitHub
참고
연속 통합은 코드베이스의 각 변경 내용을 최대한 빨리 자동으로 테스트하는 것을 의미합니다. 지속적인 업데이트는 이 테스트를 수행하고 변경 내용을 스테이징 또는 프로덕션 시스템에 푸시합니다.
Azure Data Factory가 원시 데이터를 구체화한 후에는 다음을 포함하여 비즈니스 사용자가 비즈니스 인텔리전스 도구에서 액세스할 수 있는 모든 분석 엔진에 데이터를 로드할 수 있습니다.
- Azure Synapse Analytics
- Azure SQL Database
- Azure Cosmos DB
Monitor
데이터 통합 파이프라인을 성공적으로 빌드하고 배포한 후에는 예약된 작업과 파이프라인을 모니터링해야 합니다. 모니터링을 통해 성공률과 실패율을 추적할 수 있습니다. Azure Data Factory는 다음 방법 중 하나를 사용하여 파이프라인 모니터링을 지원합니다.
- Azure Monitor
- API
- PowerShell
- Azure Monitor 로그
- Azure Portal의 상태 패널
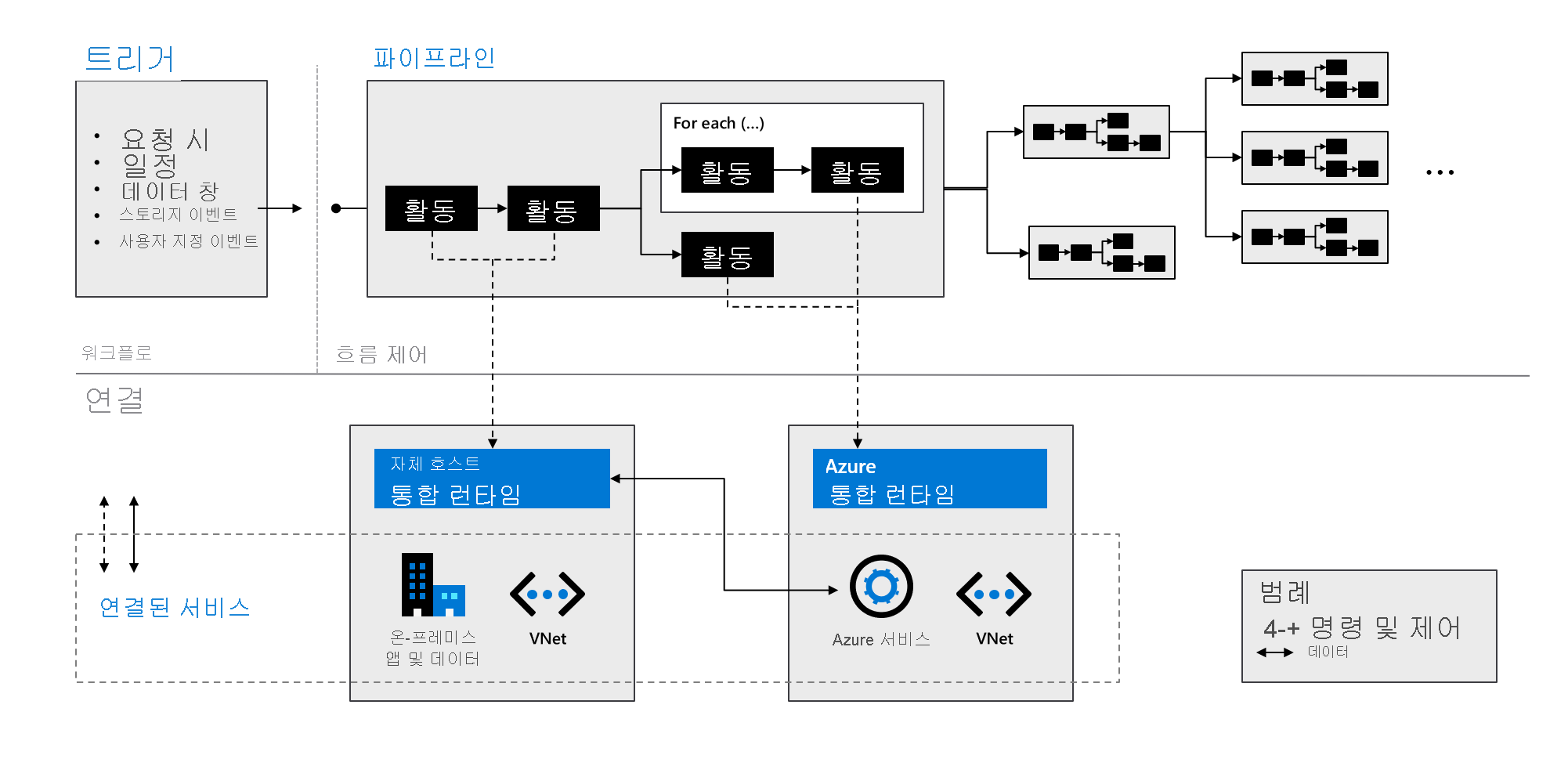
Azure Data Factory 구성 요소
Azure Data Factory는 다음 표에 설명된 구성 요소로 구성됩니다.
| 구성 요소 | Description |
|---|---|
| Pipelines | 특정 작업 단위를 수행하는 활동의 논리적 그룹화입니다. 이 활동은 함께 작업을 수행합니다. 파이프라인을 사용하면 개별 항목이 아닌 세트로 작업을 더 쉽게 관리할 수 있다는 이점이 있습니다. |
| 활동 | 파이프라인의 단일 처리 단계입니다. Azure Data Factory는 데이터 이동, 데이터 변환, 제어 활동이라는 세 유형의 활동을 지원합니다. |
| 데이터 세트 | 데이터 저장소 내에서 데이터 구조를 나타냅니다. 데이터 세트는 활동에서 입력 또는 출력으로 사용하려는 데이터를 가리키거나 참조합니다. |
| 연결된 서비스 | Azure Data Factory가 데이터 원본과 같은 외부 리소스에 연결하는 데 필요한 필수 연결 정보를 정의합니다. Azure Data Factory는 두 가지 목적으로 연결된 서비스를 사용합니다. 데이터 저장소 또는 컴퓨팅 리소스를 나타내는 것입니다. |
| 데이터 흐름 | 데이터 엔지니어는 코드를 작성하지 않아도 데이터 변환 논리를 개발할 수 있습니다. 데이터 흐름은 스케일 아웃된 Apache Spark 클러스터를 사용하는 Azure Data Factory 파이프라인 내에서 활동으로 실행됩니다. |
| 통합 런타임 | Azure Data Factory는 컴퓨팅 인프라를 사용하여 다양한 네트워크 환경에서 데이터 흐름, 데이터 이동, 작업 디스패치, SSIS(SQL Server Integration Services) 패키지 실행 등의 데이터 통합 기능을 제공합니다. Azure Data Factory에서 통합 런타임은 작업과 연결된 서비스 간에 브리지를 제공합니다. |
다음 그래픽에 표시된 것처럼 이 구성 요소는 함께 작동하여 데이터 엔지니어에게 완전한 엔드투엔드 플랫폼을 제공합니다. Data Factory를 사용하여 다음을 수행할 수 있습니다.
- 요구 사항에 따라 주문형 트리거를 설정하고 데이터 처리를 예약합니다.
- 파이프라인을 트리거와 연결하거나 필요할 때 수동으로 시작합니다.
- 온-프레미스 앱 및 데이터와 같은 연결된 서비스에 연결하거나 통합 런타임을 통해 Azure 서비스에 연결합니다.
- 모든 파이프라인은 기본적으로 Azure Data Factory 사용자 환경에서 모니터링하거나 Azure Monitor를 사용하여 모니터링합니다.