작은 조회 엔터티 모델링
데이터 모델에는 두 개의 작은 참조 데이터 엔터티인 ProductCategory, ProductTag가 포함되어 있습니다. 이러한 엔터티는 참조 값에 사용되며 1:Many relationship을 통해 다른 엔터티와 관련됩니다.
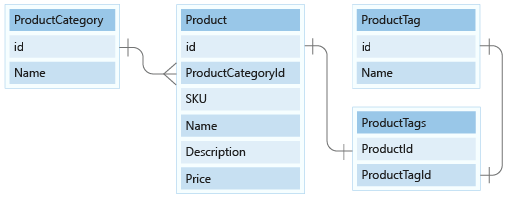
이 단원에서는 문서 모델에서 ProductCategory 및 ProductTag 엔터티를 모델링합니다.
제품 범주 모델링
우선, 범주의 경우 ID 및 이름 열을 유일한 속성으로 사용하여 데이터를 모델링하고 ProductCategory라는 새 컨테이너에 배치합니다.
다음으로 파티션 키를 선택해야 합니다. 이제 해당 데이터에 대해 수행해야 하는 작업을 살펴보겠습니다.
먼저 새 제품 범주를 생성한 후 제품 범주를 편집하고 모든 제품 범주를 나열합니다. 제품 범주 생성 및 편집 작업은 자주 실행되지 않습니다. 전자상거래 애플리케이션은 고객이 웹 사이트를 방문할 때 모든 제품 범주를 나열하는 경우가 많습니다. 즉, 마지막 작업이 가장 자주 실행될 것입니다.
이 마지막 작업에 대한 쿼리는 SELECT * FROM c와 같습니다.
id를 선택한 파티션 키로 사용하는 경우 이 쿼리는 이제 분할됩니다. 이러한 읽기 작업을 최적화하려는 경우에도 가능하면 단일 파티션만 사용합니다. 제품 범주에 대한 데이터는 크기가 20GB 정도로 절대 커지지 않으므로 어떻게 이 정보가 모든 제품 범주를 나열할 때 단일 파티션 쿼리를 생성하는 방식으로 데이터를 모델링하는 데 도움이 될 수 있을지도 알 수 있습니다.
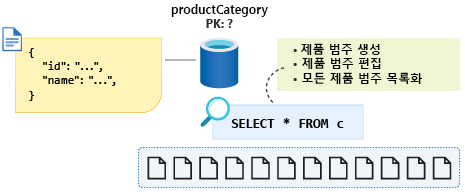
이와 같은 적은 양의 데이터를 다시 단일 파티션으로 강제 변환하기 위해 스키마에 엔터티 판별자 속성을 추가하고 이 컨테이너의 파티션 키로 사용할 수 있습니다. 컨테이너에서 이 형식의 모든 문서에 대한 상수 값을 이 속성에 할당하여 단일 파티션 쿼리를 사용할 수 있도록 합니다. 이 경우에는 이 속성을 type으로 지칭하고 상수 값 category를 제공합니다. 이제 쿼리는 SELECT * FROM c WHERE c.type = ”category”와 같습니다.

제품 태그 모델링
다음 차례는 ProductTag 엔터티입니다. 이 엔터티는 이전 섹션에서 설명한 ProductCategory 엔터티와 거의 동일하게 기능합니다. 여기에서 동일한 방법을 사용하고 ID 및 이름 속성을 포함하도록 문서를 모델링하고 type이라는 엔터티 판별자 속성을 만듭니다(이 경우 상수 값 tag 사용). ProductTag라는 새 컨테이너를 생성하고 type을 새 파티션 키로 만듭니다.
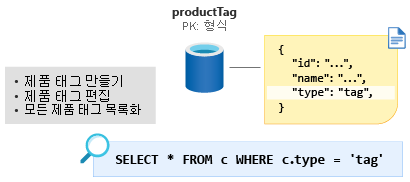
일부 사람들은 작은 조회 테이블을 모델링하는 해당 기술을 이상하게 생각합니다. 그러나 해당 방식으로 데이터를 모델링함으로써 다음 모듈에서 추가 최적화를 수행할 수 있도록 합니다.