하이브리드 파일 액세스 요구 사항
이전 단원에서는 주로 스토리지 솔루션이 수행하는 ‘작업’을 중점적으로 살펴보았습니다. 이 단원은 데이터가 있는 위치에 중점을 둡니다. 특히 하이브리드 파일 액세스 고려 사항 및 접근 방법을 알아봅니다.
하이브리드 파일 액세스 개요
현재 데이터 센터에서 실행 중인 HPC 워크로드를 Azure에서 실행하기로 했습니다. 컴퓨팅 환경은 워크로드에 NFSv3 작업을 제공하는 NAS의 데이터에 액세스합니다. NAS는 몇 년 동안 실행되어 왔지만 NAS 환경은 주기가 끝나가고 있을 수도 있습니다. 이를 대체하는 대신 클라우드로의 장기적인 마이그레이션을 고려하고 있습니다.
이 결정을 내린 후 HPC 워크로드의 전체 클라우드를 배포하기 전에 Azure 전략을 결정하고 기준 계정/구독/보안 설정을 확립합니다. 이제 어려운 부분인 HPC 워크로드 이동이 남았습니다.
HPC 클러스터 빌드 및 관리 평면은 이 모듈의 범위를 벗어납니다. 클러스터에서 실행할 가상 머신 유형 및 수량을 결정한다고 가정합니다.
또한 지금은 워크로드를 현재 상태로 실행하는 것을 목표로 한다고 가정합니다. 즉, 현재 온-프레미스에 배포된 논리 또는 액세스 방법을 수정하지 않으려고 합니다. 따라서 코드를 실행하면 클러스터 멤버 로컬 파일 시스템의 디렉터리 경로에 데이터가 있어야 합니다.
첫 번째 목표는 어떤 데이터가 필요한지와 데이터 원본 위치가 어디인지를 파악하는 것입니다. 데이터가 단일 NAS 환경의 단일 디렉터리에 있을 수도 있고 여러 환경에 분산되어 있을 수도 있습니다.
다음 목표는 워크로드를 실행하는 데 필요한 데이터양을 결정하는 것입니다. 원본 데이터가 2~3GB인가요, 아니면 수백 테라바이트인가요?
마지막으로, 데이터가 Azure 컴퓨팅에 표시되는 방법을 결정해야 합니다. 각 HPC 클러스터 머신에 로컬로 제공되나요, 아니면 클라우드 기반 NAS 솔루션에서 공유하나요?
원격 데이터 액세스 고려 사항
Azure에서 실행하려는 유전체학 워크로드가 있습니다. 데이터는 유전자 시퀀서에 의해 온-프레미스에서 생성되어 로컬 NAS 환경으로 전송됩니다. 온-프레미스 연구원은 이 데이터를 다양한 용도로 사용합니다. 연구원은 Azure에서 실행하려는 HPC 워크로드의 결과를 사용할 수도 있습니다. 하지만 일부는 온-프레미스 워크스테이션을 사용합니다. 또한 새로운 게놈 데이터가 정기적으로 생성된다고 가정하겠습니다. 따라서 데이터를 바꾸거나 새로 고치기 전에는 현재 워크로드의 실행 간격이 제한적입니다.
문제는 데이터에 대한 온-프레미스 액세스를 유지하면서 적시에 비용 효율적인 방법으로 데이터를 Azure 컴퓨팅에 제공하는 것입니다.
다음은 Azure에서 HPC 워크로드를 실행하려 할 때 확인할 수 있는 몇 가지 주요 질문입니다.
- 온-프레미스 복사본을 유지하지 않고 원본 데이터를 Azure로 이동할 수 있나요?
- 온-프레미스 복사본을 유지하지 않고 결과 데이터를 Azure Storage에 저장할 수 있나요?
- 온-프레미스 사용자가 원본 또는 결과 데이터에 동시에 액세스해야 하나요?
- 동시에 액세스해야 하는 경우 Azure에서 데이터로 작업할 수 있나요, 아니면 온-프레미스에 데이터를 저장해야 하나요?
데이터를 온-프레미스에 유지해야 하는 경우 워크로드를 위해 Azure로 복사해야 하는 데이터양은 어느 정도인가요? 데이터를 처리한 후 얼마 후에 새 데이터 세트를 처리해야 하나요? 이 기간에 워크로드가 실행되나요?
또한 Azure에 대한 네트워크 연결을 고려해야 합니다. Azure에 대한 인터넷 액세스만 있나요? 해당 제한 사항은 복사/전송할 데이터 크기와 새로 고침 간격에 따라 문제가 되지 않을 수도 있습니다. 매번 많은 양의 데이터를 복사해야 할 수 있습니다. Azure ExpressRoute를 사용하여 WAN(광역 네트워크)을 통해 Azure에 연결해야 할 수도 있으며 이 경우 더 많은 대역폭으로 데이터를 복사/전송할 수 있습니다.
ExpressRoute가 이미 Azure에 연결된 경우 다음으로 고려할 사항은 데이터 복사 작업에 사용할 수 있는 연결의 양입니다. 링크가 심하게 포화된 경우에는 하루 중 언제 데이터를 전송하는 것이 좋을지 고려해야 할 수 있습니다. 또는 대규모 데이터 전송을 수용할 더 큰 ExpressRoute 연결을 구성해야 할 수도 있습니다.
데이터를 Azure로 이동하는 경우에는 데이터를 보호하는 방법을 고려해야 할 수도 있습니다. 예를 들어 권한을 해당 사용자로 확장하는 데 도움이 되는 디렉터리 서비스를 사용하는 온-프레미스 NFS 환경을 보유하고 있을 수 있습니다. 이 보안을 Azure에 복사하려는 경우 Azure 빌드 과정에서 디렉터리 서비스가 필요한지 여부를 결정해야 합니다. 그러나 워크로드가 HPC 클러스터로 제한되고 결과가 다시 로컬 환경으로 전송되는 경우에는 이 요구 사항을 생략할 수 있습니다.
다음으로 데이터에 액세스하는 방법, 즉 캐싱, 복사, 동기화를 살펴보겠습니다.
캐싱, 복사, 동기화
Azure에 데이터를 추가하는 데 사용할 수 있는 일반적인 방법을 알아봅니다. 이 데이터 전송 논의의 초점은 데이터 보관 및 백업이 아닌 활성 데이터입니다.
예제에서 전송되는 데이터는 HPC 워크로드의 ‘작업 집합’으로 간주됩니다. 생명 과학 HPC 환경의 데이터에는 원본 데이터(예: 원시 게놈 데이터), 데이터 처리에 사용되는 이진 항목 또는 보조 데이터(예: 참조 게놈)가 포함될 수 있습니다. 데이터가 도착하면 즉시 또는 오래지 않아 처리해야 합니다. 또한 IOPS, 대기 시간, 처리량, 비용 측면에서 적절한 성능 프로필이 있는 미디어에 데이터를 저장해야 합니다. 반면에 보관/백업 데이터는 대체로 고성능 액세스용이 아닌, 가장 저렴한 스토리지 솔루션으로 전송됩니다.
활성 데이터를 전송하는 기본 방법은 ‘캐싱’, ‘복사’, ‘동기화’입니다. 복사를 시작으로 각 접근 방식의 장단점을 살펴보겠습니다.
데이터 복사는 가장 일반적인 데이터 이동 방법입니다. 사용하는 도구에 따라 다양한 방법으로 데이터가 복사됩니다.
다음 항목을 고려합니다.
- 파일 크기
- 파일 수
- 데이터 전송에 사용할 수 있는 처리량
- 전송에 사용할 수 있는 시간
적절한 크기의 파일 몇 개를 원격 대상으로 전송하는 경우에는 cp 같은 기본 복사 도구만 있으면 됩니다. scp는 SSH(Secure Shell) 연결을 통해 암호화를 제공하므로 보호되지 않은 네트워크를 통해 데이터를 전송하는 경우에는 cp 대신 scp를 사용하는 것이 좋습니다.
데이터를 복사하려는 위치에 따라 복사 작업을 최적화하는 다양한 방법이 있습니다. 예를 들어 각 HPC 머신에 파일을 직접 복사하는 경우 각 노드에서 개별 복사 작업을 예약할 수 있습니다.
WAN 링크를 통해 데이터를 복사하는 경우 고려해야 할 사항 중 하나는 복사 중인 파일 및 폴더의 수량입니다. 많은 수의 작은 파일을 복사하는 경우 tar와 같은 보관과 복사를 함께 사용하여 WAN 링크에서 메타데이터 오버헤드를 제거하는 것이 좋습니다. .tar 파일을 Azure에 복사한 다음, 데이터를 머신에 복사합니다.
복사에 관한 또 다른 문제는 중단 위험입니다. 예를 들어 큰 파일을 복사하는 중 전송 오류가 발생할 경우 cp는 중단된 위치부터 복사를 다시 시작할 수 없기 때문에 효과가 없습니다.
데이터를 복사하는 경우의 마지막 문제는 복사본이 ‘부실’해질 수 있다는 것입니다. 예를 들어 데이터 세트를 Azure에 복사할 수 있습니다. 그동안 어떤 온-프레미스 사용자가 하나 이상의 원본 파일을 업데이트했을 수 있습니다. 올바른 데이터를 사용하고 있는지 확인하는 프로세스를 파악해야 합니다.
데이터 동기화는 복사의 한 형태이지만 더 정교합니다. rsync와 같은 도구를 사용하면 데이터를 원본에서 복사할 뿐 아니라 원본과 대상 간에 데이터를 동기화할 수도 있습니다. rsync는 파일 크기 및 수정 날짜를 기준으로 파일이 최신 상태인지 확인합니다. 동기화를 사용하면 부실 파일을 사용할 가능성을 최소화할 수 있습니다.
rsync에는 복구 기능이 있습니다. 예를 들어 큰 파일을 복사하는 중 전송 문제가 발생한 경우에는 rsync를 사용하여 중단된 위치에서 다시 시작할 수 있습니다.
rsync는 비용이 들지 않고 쉽게 구현할 수 있습니다. rsync에는 여기서 설명되지 않은 기능도 포함되며, 이 도구를 사용하여 온-프레미스 데이터를 기준으로 Azure에서 동기화된 파일 시스템을 구축할 수 있습니다.
또한 rsync에는 언급해야 할 제한 사항이 있습니다. 첫째, 이 도구는 ‘단일 스레드’입니다. 한 번에 하나의 작업만 실행할 수 있으며 데이터 액세스를 병렬화할 수 없습니다. 복사 유틸리티 cp도 단일 스레드입니다. 따라서 해당 도구는 대량의 데이터를 사용하는 짧은 시간의 대규모 복사/동기화 작업에 최적화되지 않습니다. 또한 데이터를 동기화하려면 도구를 실행해야 합니다. 도구를 실행하면 시간 프레임 요구 사항에 따라 실행되고 있는지 확인해야 하므로 사용자 환경이 더욱 복잡해집니다. 예를 들어 rsync를 포함하는 스크립트를 예약할 수 있습니다. 이 방법을 사용할 때는 문제가 있을 경우를 대비해 스크립트 로깅을 추가해야 합니다. 또한 문제가 발생하는지 주시해야 합니다. 복잡성 수준이 빠르게 증가할 수 있습니다.
상용 NAS 솔루션을 실행하는 경우 보다 정교하고 다중 스레드 성능을 제공하는 서버 수준 동기화 도구를 구입할 수 있습니다. 해당 도구를 사용하도록 설정하고 구성하면 항상 작동하며 하나 이상의 원본과 대상 간에 데이터를 동기화합니다.
복사 및 동기화는 원본 데이터의 전체 복사본을 전송합니다. 더 작은 데이터 세트 또는 파일 크기에는 전체 파일 전송이 적합할 수 있습니다. 원본 데이터가 많은 수의 큰 파일로 구성되면 상당히 지연될 수 있습니다. 전송하는 데이터가 많을수록 전송 시간이 길어집니다. 동기화를 사용하면 클라우드에 새 파일만 추가하게 됩니다. 그러나 해당 파일은 여전히 전체를 전송해야 합니다. 때에 따라서는 HPC 워크로드에 지정된 파일 세트 전체가 필요하지 않을 수도 있으며, 특정 파일 영역에만 액세스해야 할 수 있습니다.
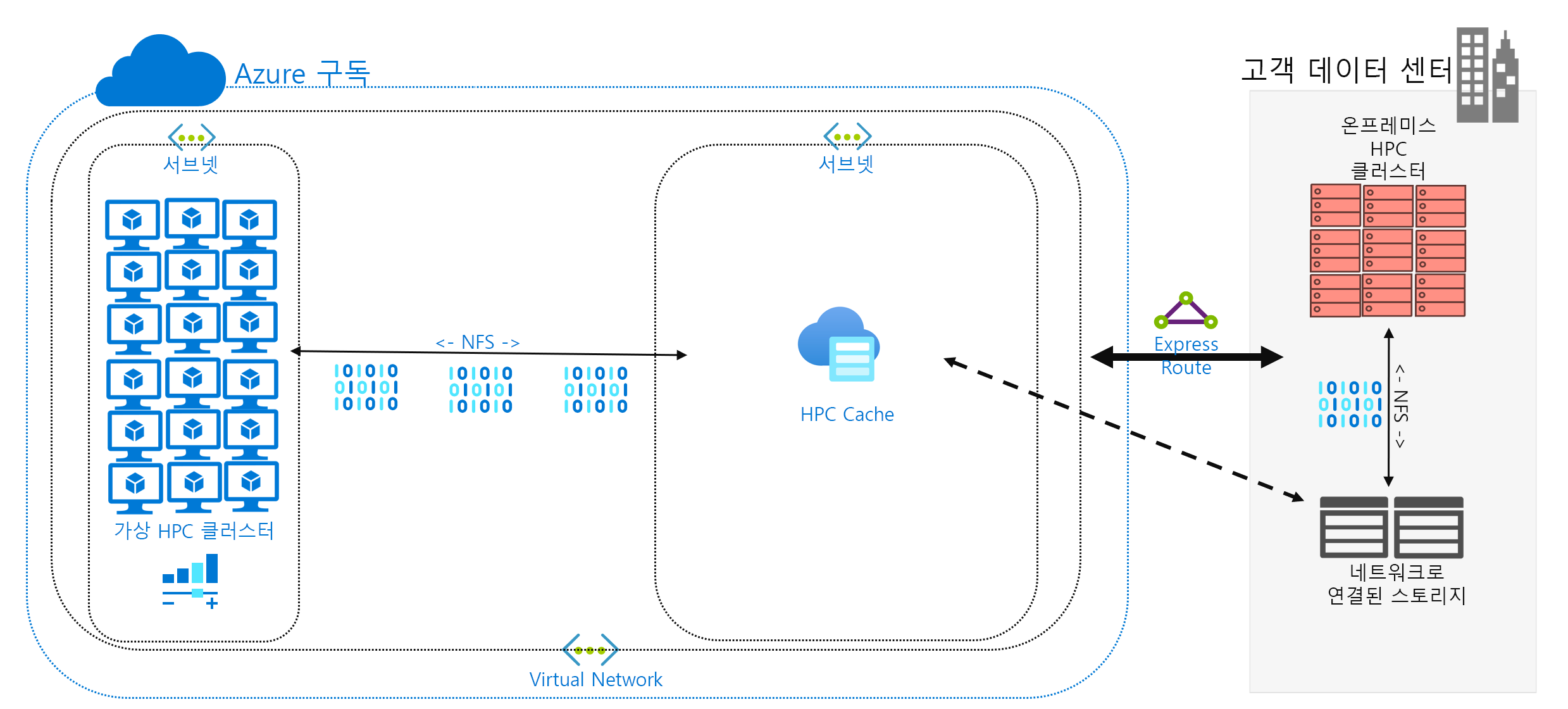
데이터 캐싱은 Azure에 데이터를 추가하는 세 번째 방법입니다. ‘캐싱’은 캐시를 통해 파일 데이터를 검색하고 표시하는 것을 나타냅니다. 캐시는 개별 로컬 클라이언트에 있거나 모든 HPC 머신에 서비스를 제공하는 분산 캐시일 수도 있습니다. 일반적으로 캐시는 대기 시간을 최소화하는 데 사용되므로 대기 시간 경계에 캐시를 배치하는 것이 데이터를 제공하는 최적의 방법입니다. 예를 들어 WAN 연결을 통해 온-프레미스 스토리지에 연결된 Azure Compute에 분산 캐시를 배치하여 WAN 연결을 통해 데이터 요청을 캐시할 수 있습니다.
이 모듈에서는 특히 캐시 자체가 머신의 요청을 처리하는 ‘파일 캐싱’을 나타냅니다. 백 엔드 스토리지 환경(예: NFS NAS 환경)에서 데이터를 검색하고 해당 데이터를 클라이언트에 제공합니다.
캐싱의 장점은 두 가지입니다. 첫째, 캐시는 전체 파일을 검색하지 않습니다. 캐시는 전체 파일이 아니라 파일의 요청된 하위 집합 또는 바이트 범위를 검색합니다. 검색은 해당 바이트 범위에 대한 클라이언트 요청을 기반으로 합니다. 이 검색 방법은 파일의 작은 섹션만 필요할 때 큰 파일 전체를 검색함으로써 발생하는 성능 저하를 최소화합니다.
두 번째, 캐시는 자주 요청되는 데이터의 반복 액세스를 최적화합니다. 바이트 범위가 캐시에 있으면 해당 데이터에 대한 이후 요청이 빠릅니다. 검색이 느릴 때는 처음에 검색할 때뿐입니다. 공통 파일 세트에 액세스하는 많은 수의 HPC 클라이언트/스레드를 실행하는 경우 상당한 이점을 얻을 수 있습니다.
캐싱은 하이브리드 시나리오에서 또 다른 이점을 제공합니다. 데이터는 Azure에(캐시에) 일시적으로 저장됩니다. 그리고 HPC 워크로드 작업 중에만 저장됩니다. 따라서 Azure를 향한 좀 더 구체적인 데이터 이동과 관련된 로지스틱 오버헤드를 줄일 수 있습니다. 데이터 개인 정보 및 보안 문제를 캐시 및 HPC 머신 자체로 분리할 수 있습니다.
마지막으로, 특정 캐싱 솔루션은 ‘특성 확인’이라는 기능을 제공합니다. 동기화와 유사하게 캐시는 원본에 있는 파일의 특성을 주기적으로 확인하고, 원본에서 파일 수정이 더 많이 이루어질 경우 바이트 범위를 검색합니다. 이 아키텍처는 HPC 환경이 항상 최신 데이터로 작동하도록 합니다.