병렬 파일 시스템
NFS는 엔터프라이즈에서 발전했으며 규모가 점점 커지는 동시 파일 액세스를 처리하도록 설계되었습니다. 그러나 NFS 솔루션을 사용하여 얻을 수 있는 성능과 규모에는 상한이 있습니다. 여러 동시 프로세스가 파일의 일부 섹션에 쓰는 기능을 포함하여 훨씬 더 뛰어난 파일 병렬 액세스가 필요한 워크로드 클래스도 있습니다.
대규모 읽기 및 쓰기의 필요성은 지난 20년 동안 상당히 증가했습니다. 최대 규모의 고성능 워크로드를 가속화하려고 할 때 병렬 파일 시스템 솔루션을 주로 선택합니다. 병렬 파일 시스템은 슈퍼 컴퓨팅 센터에서 시작되었습니다. 이제 다양한 시나리오에 널리 배포됩니다. 예를 들어, 주요 석유 및 가스 회사에서 사용하는 지진 처리 및 해석 솔루션과 게놈 데이터의 2차/3차 분석 등이 있습니다.
이 단원에서는 병렬 파일 시스템을 간단히 다룹니다. 관련 워크로드를 실행해 온 경우라면 아마 해당 솔루션의 드라이버, 요구 사항, 아키텍처에 대해 잘 알고 계실 것입니다. NFS 및 병렬 파일 시스템을 제공하는 분산 NAS 솔루션 간에는 애매한 부분이 있습니다. 병렬 파일 시스템을 사용하면 요구 사항을 더 잘 충족할 수 있습니다.
이 단원을 완료하면 병렬 파일 시스템의 주요 기능을 더 잘 알게 됩니다.
지금까지 병렬 파일 시스템은 애플리케이션 I/O에 대한 심층적인 지식이 필요한 전체 기능 클래스였습니다. 이 정보의 목적은 전문 지식을 쌓는 것이 아니라 이해를 돕는 것입니다.
분산 NAS(NFS), 병렬 파일 시스템
분산 NAS와 병렬 파일 시스템은 모두 공유 파일 시스템입니다. 여러 클라이언트가 동시에 파일을 읽고, 파일을 쓰고, 잠그고, 메타데이터를 수정하는 등의 작업을 수행할 수 있습니다.
스토리지 하드웨어 기술을 추가 또는 업그레이드하거나, 프런트 엔드 서버를 추가하여 클라이언트 액세스를 스케일링하거나, 네트워크 연결을 개선하여 두 가지 시스템을 모두 스케일링할 수 있습니다.
병렬 I/O
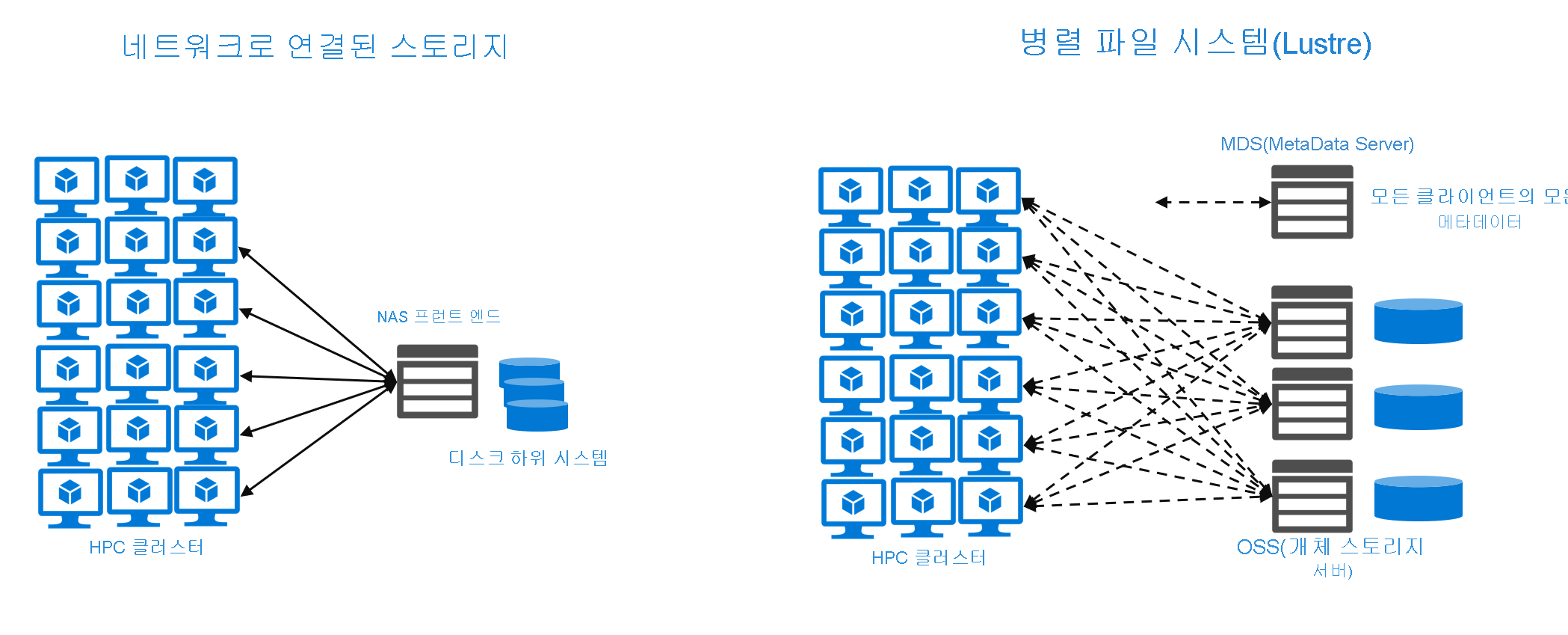
병렬 파일 시스템은 파일을 불연속 블록 또는 스트라이프로 분할하고 여러 스토리지 서버에 파일을 분산합니다. 데이터를 스트라이핑하는 분산 파일 시스템이 있습니다. 차이점은 병렬 파일 시스템의 경우 호스팅 스토리지 서버 자체와 통신하여 스트라이프를 클라이언트에 직접 노출한다는 것입니다. 스트라이핑을 사용하면 표준 분산 NAS 시스템을 통해 상당한 병렬 I/O를 처리할 수 있습니다. 가장 일반적인 스케일 아웃 NAS 환경에서 실행되는 NFS 클라이언트는 단일 서버를 통해 파일에 액세스해야 합니다. 클라이언트가 단일 서버에 액세스하는 경우 ‘동시 요청’ 수가 서버에서 처리할 수 있는 개수를 초과하면 문제가 발생합니다. 또한 스트라이핑과 병렬 액세스에 대한 병렬 파일 시스템 접근 방식은 많은 수의 동시 클라이언트에 있는 큰 파일에 액세스해야 하는 워크로드에 적합합니다.
다음은 세 가지 주요 병렬 파일 시스템입니다.
- Spectrum Scale이라고 하는 IBM의 GPFS
- 오픈 소스이지만 몇몇 상용 구현이 있는 Lustre
- BeeGFS
해당 시스템은 다양한 방식으로 병렬 I/O를 달성합니다. GPFS는 고성능 SAN(저장 영역 네트워크)에 연결하는 ‘NSD(네트워크 스토리지 디바이스)’라는 서버를 사용합니다. 따라서 GPFS 서버는 원시 디스크 I/O를 지원 스토리지로 포함합니다. BeeGFS에는 Lustre와 동일한 아키텍처 구성 요소가 많이 있지만 강력한 분산 메타데이터 아키텍처도 있습니다. BeeGFS On Demand의 약어인 BeeOND는 각 클라이언트의 스토리지를 사용하는 주문형 BeeGFS 환경을 가능하게 합니다. 이 임시 파일 시스템 환경을 버스트 버퍼링에 사용할 수 있습니다.
그러나 두 경우 모두 스토리지 서버를 더 추가함으로써 클라이언트에 더 많은 병렬 I/O를 제공하여 병렬 파일 시스템을 스케일링할 수 있습니다. 또한 총 클라이언트 수도 상당하여 수만 개에 이를 수 있습니다.
메타데이터
NFS 클라이언트는 메타데이터 정보를 제공하고 클라이언트를 위해 데이터를 검색하는 NFS 서버와 직접 연결됩니다. 클라이언트의 양과 예상 트래픽 요금에 따라 서버 구성 요소의 크기를 조정해야 합니다. 이 구성 요소는 병목 상태가 될 수 있습니다. NAS 공급업체가 일부 메타데이터 최적화를 구현할 수는 있지만 대부분의 NFS 구현은 별도의 메타데이터 서비스를 인식하지 못합니다.
그 반면에 병렬 파일 시스템은 클라이언트 데이터 액세스를 보다 효율적으로 스케일링하는 전략을 구현합니다. 예를 들어 Lustre는 별도의 MDS(메타데이터 서버)를 구현합니다. 클라이언트는 해당 시스템에서 모든 메타데이터를 검색합니다. 그리고 Lustre 클라이언트는 지정된 파일이 있는 스토리지 서버에 직접 액세스하고 여러 병렬 스레드를 읽거나 쓸 수 있습니다. 이 방법을 사용하면 아키텍처가 배포된 스토리지 서버 수에 따라 대역폭을 스케일링할 수 있습니다.
블록 크기
블록 크기는 앞의 NFS 맥락에서 설명했습니다. 병렬 파일 시스템 블록 크기는 NFS 블록 크기보다 클 수 있습니다. NFS 클라이언트의 기본 rsize/wsize는 일반적으로 64,000입니다. 예를 들어 Lustre는 블록 크기를 MB 단위로 표시합니다. 블록 크기가 더 크기 때문에 다음 두 가지 효과가 있습니다. 첫째, 병렬 파일 시스템의 대용량 파일 읽기/쓰기 성능이 높습니다. 그러나 파일 크기가 작고 파일 수가 많은 경우에는 병렬 파일 시스템의 이점이 거의 없습니다.
복잡성
NFS를 실행하는 분산 파일 시스템 솔루션은 일반적인 사용 사례에 맞게 쉽게 설정하고 실행할 수 있습니다. 모든 시스템과 마찬가지로 워크로드에 따른 클라이언트-서버 블록 크기(rsize/wsize) 조작을 포함하여 성능을 위해 튜닝할 수 있습니다.
병렬 파일 시스템은 일반적으로 스케일링 환경의 복잡한 워크로드에 대해 작동합니다. 또한 충분한 성능과 규모를 보장하기 위해 구성 및 튜닝이 필요할 가능성이 더 큽니다.
배포 고려 사항
Azure는 여러 고유한 병렬 파일 시스템 제품을 제공합니다. Azure Marketplace로 이동하여 BeeGFS, Lustre 등의 여러 옵션을 확인할 수 있습니다. (Whamcloud를 검색하세요.) 표준 Linux 가상 머신에 Lustre를 설치하거나 Azure 빠른 시작 사이트에 있는 ARM(Azure Resource Manager) 템플릿을 사용할 수도 있습니다.