HPC 작업을 위한 파일 액세스
스토리지 액세스는 HPC 워크로드 성능 계획의 중요한 부분입니다. 필요한 데이터가 적시에 HPC 클러스터 머신에 도달하도록 해야 합니다. 또한 개별 머신의 결과가 신속하게 저장되고 추가 분석을 위해 제공되도록 해야 합니다.
파일에는 다음을 비롯한 다양한 종류의 데이터가 포함될 수 있습니다.
- 비정형 데이터(예: 이미지, 문서 또는 미디어 파일)
- 다양한 소스의 시계열 데이터
- 가격 책정 데이터(예: 주가 기록)
- 계산 분석에 사용되는 자산(예: 게놈 데이터, 방사선 이미지 또는 날씨 시뮬레이션)
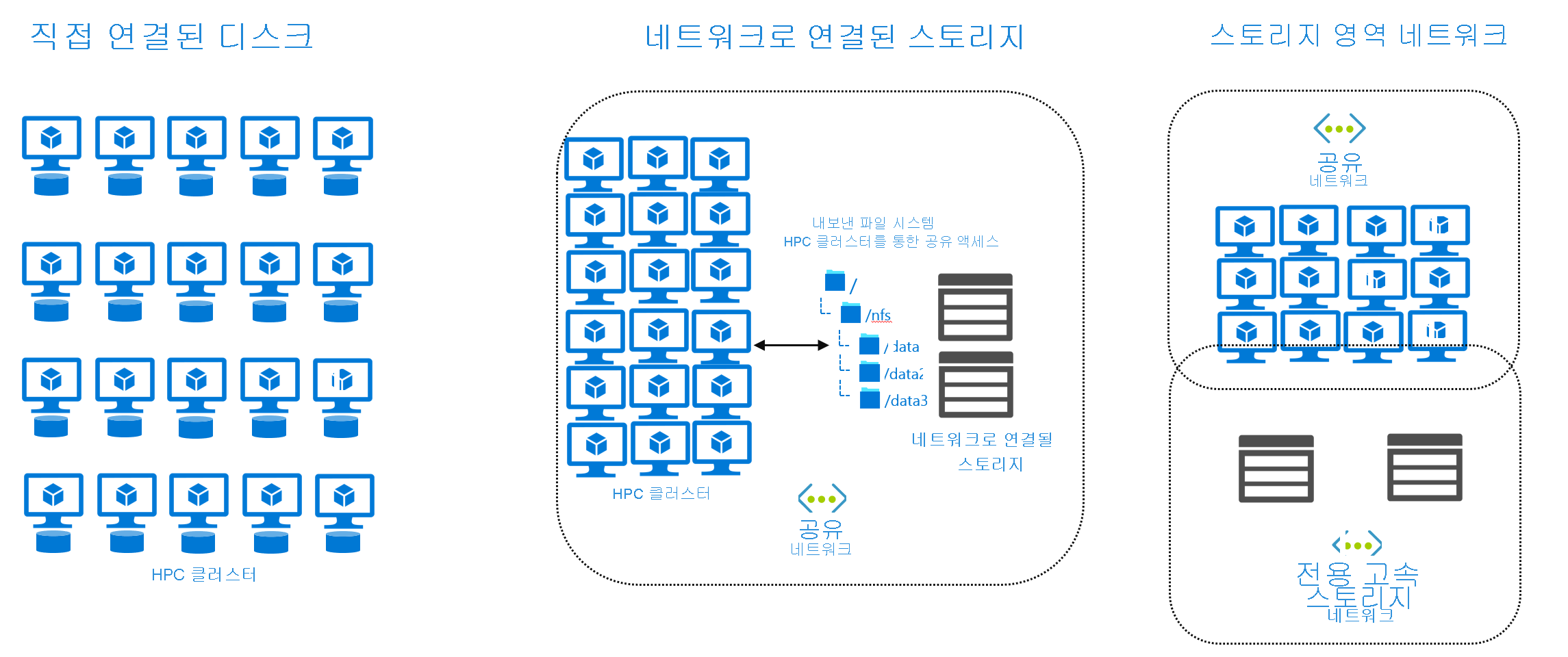
데이터는 로컬 환경의 하나 이상 스토리지 솔루션에 있는 것으로 간주됩니다. 이 맥락에서 스토리지 아키텍처에는 다음이 포함됩니다.
- 직접 연결된 디스크. 즉, HPC 클러스터의 각 머신에 고유한 로컬 스토리지 디스크가 있습니다.
- NAS(네트워크 연결 스토리지) 솔루션
- SAN(저장 영역 네트워크) 솔루션
분석가, 아티스트, 연구원 또는 과학자는 로컬에서 데이터를 만들 수 있습니다. 또는 정기적으로 타사에서 데이터를 가져와 로컬 스토리지 솔루션에 보관할 수도 있습니다.
파일 액세스 형식
이 모듈에서 설명하는 일반적인 파일 액세스 사용 사례는 다음 작업으로 제한됩니다.
- HPC 클러스터 머신에서 작업 코드, 라이브러리 및/또는 도구 체인 로드 및 실행
- 작업의 원본 데이터 읽기. 일일 가격 책정 데이터, 게놈 데이터 또는 위성 데이터를 예로 들 수 있습니다.
- 중간 또는 스크래치 쓰기 특정 작업의 경우 초기 데이터를 처리해야 하며 처리 출력이 다운스트림 활동의 새 입력이 됩니다.
- 작업의 결과 쓰기. 해당 사용 사례에는 추가 사용을 위해 데이터를 적절한 위치에 배치하는 작업도 포함됩니다. 예를 들어 비디오를 렌더링하고 렌더링된 결과를 사용할 수 있도록 공유 볼륨에 배치하는 경우입니다.
HPC 머신이 작업 집합 데이터를 가져오는 방법
HPC 클러스터의 머신은 직접 연결된 디스크나 네트워크 내보내기 또는 공유를 통해 파일에 액세스합니다. 두 경우 모두 파일은 로컬 경로(예: /mnt/data)에 표시됩니다.
실제 HPC 작업을 구성하는 코드와 스크립트는 이 파일 시스템에서 파일에 액세스할 수 있다고 가정하고 머신의 파일 액세스 기능을 사용하여 파일을 가져옵니다. 예를 들어 NAS에 있는 파일에 액세스해야 하는 Linux 실행 머신은 운영 체제의 일부로 설치된 NFS(네트워크 파일 시스템) 프로토콜 및 NFS 클라이언트 패키지를 사용합니다.
파일 메타데이터 이해
파일은 실제 데이터(예: 이미지 또는 텍스트 줄)와 ‘메타데이터’라는 추가 정보를 저장합니다. 해당 메타데이터는 파일 데이터 또는 디렉터리 내에 있습니다. HPC 파일 시스템 성능의 맥락에서 해당 메타데이터를 이해하는 것이 중요합니다.
메타데이터는 데이터 특성을 설명하는 값 세트지만 데이터의 일부는 아닙니다. 예를 들어 메타데이터는 파일을 만들고 수정한 시간, 파일을 만든 사람, 파일에 액세스할 수 있는 권한이 있는 사람을 알려줍니다.
파일을 만들 때는 구조를 할당하고 해당 파일의 디렉터리 항목을 업데이트하는 메타데이터 작업이 있습니다. 이러한 작업은 데이터를 파일에 쓰기 전에 발생합니다.