HDInsight 구성 옵션
HDInsight에는 스트리밍 및 일괄 처리 데이터 시나리오를 처리하는 데 사용할 수 있는 광범위한 OSS 기술이 포함되며, 이는 람다 아키텍처 내에서 정의된 용어입니다. 이 아키텍처 모델에는 데이터의 실행 부하 과다 경로 및 콜드 경로가 있습니다. 데이터의 실행 부하 과다 경로는 디바이스, 센서 또는 애플리케이션에서 실시간으로 생성되고 데이터 분석은 거의 실시간으로 수행되며, 이를 스트리밍 데이터라고 합니다. 콜드 데이터 경로는 일반적으로 다른 데이터 저장소에서 데이터를 일괄 이동하는 경우이며, 이를 일괄 처리 데이터라고 합니다.
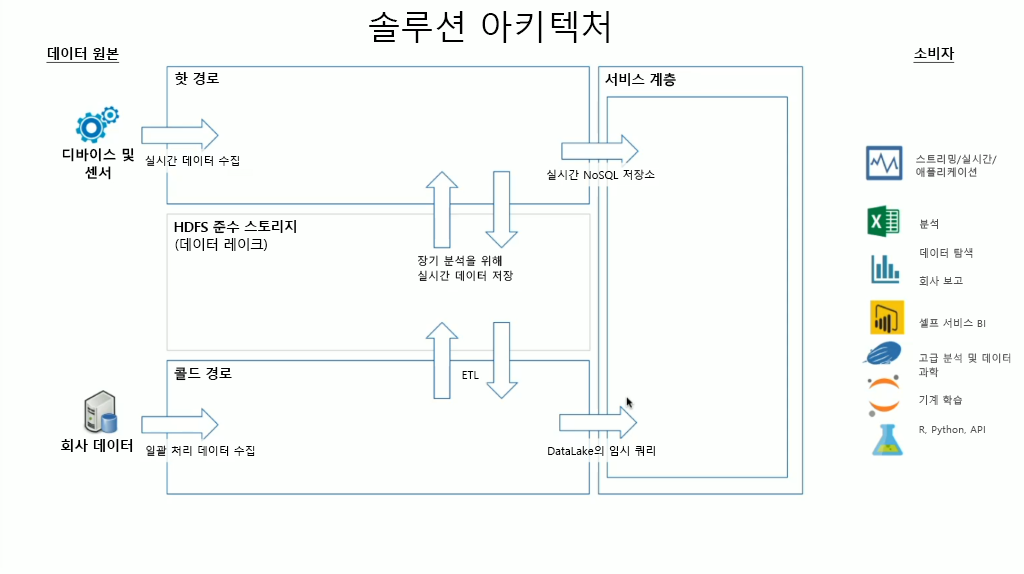
HDInsight를 구현할 때 데이터 스토리지는 규정을 준수하는 HDFS(Hadoop Distributed File System) 내에 유지됩니다. Azure에서 Data Lake Gen2는 일반적으로 HDFS 규격이므로 데이터 저장소로 사용됩니다. 처리 후 실행 부하 과다 경로 및 콜드 경로의 데이터는 Data Lake라는 중앙 집중형 데이터 저장소에 저장됩니다. 데이터 상태(랜딩 존, 변환 영역 등), 액세스 요구 사항(핫, 웜 및 콜드) 및 비즈니스 그룹별로 정의할 수 있는 다양한 구획에 데이터를 저장하도록 데이터 레이크 자체를 구획화할 수 있습니다. 서비스 레이어는 다양한 소비자가 사용할 수 있는 형식으로 데이터를 저장하는 데이터 레이크의 최종 구획입니다.
HDInsight의 컴퓨팅 측면은 스트리밍 또는 일괄 처리 데이터의 처리를 다루며 HDInsight 클러스터를 프로비저닝할 때 선택하는 클러스터 유형에 따라 달라질 수 있습니다. HDInsight는 다음 표에 나온 대로 서비스를 개별 클러스터 옵션으로 제공합니다.
| 클러스터 유형 | 설명 |
|---|---|
| Apache Hadoop | HDFS 및 간단한 MapReduce 프로그래밍 모델을 사용하여 일괄 처리 데이터를 처리하고 분석하는 프레임워크입니다. |
| Apache Spark | 메모리 내 처리를 지원하여 빅 데이터 분석 애플리케이션의 성능을 향상하는 오픈 소스 병렬 처리 프레임워크입니다. |
| HBase | 비정형 및 반정형 대량 데이터(잠재적으로 수십억 개의 행과 수십억 개의 열로 구성됨)에 관해 임의 액세스 및 강력한 일관성을 제공하는 Hadoop 기반의 NoSQL 데이터베이스입니다. |
| Apache Interactive Query | 더 빠른 대화형 Hive 쿼리를 위한 메모리 내 캐싱입니다. |
| Apache Kafka | 스트리밍 데이터 파이프라인 및 애플리케이션을 빌드하는 데 사용되는 오픈 소스 플랫폼입니다. 또한 Kafka는 데이터 스트림을 게시하고 구독할 수 있는 메시지 큐 기능을 제공합니다. |
따라서 해결하려는 비즈니스 사례를 충족하는 데 적합한 클러스터 유형을 선택하는 것이 중요합니다. 선택된 클러스터 유형에 관계없이 다음을 포함한 추가 기능을 제공하도록 다른 오픈 소스 구성 요소도 클러스터 내부에 추가됩니다.
Hadoop 관리
HCatalog - Hadoop용 테이블 및 스토리지 관리 레이어입니다.
Apache Ambari - Apache Hadoop 클러스터를 손쉽게 관리 및 모니터링할 수 있습니다.
Apache Oozie - Apache Hadoop 작업을 관리하기 위한 워크플로 스케줄러 시스템입니다.
Apache Hadoop YARN – 리소스 관리 및 작업 예약/모니터링을 관리합니다.
Apache ZooKeeper - 구성 정보 유지 관리, 이름 지정, 분산 동기화 제공 및 그룹 서비스 제공을 위한 중앙 집중형 서비스입니다.
데이터 처리
Apache Hadoop MapReduce - 방대한 양의 데이터를 처리하는 애플리케이션을 쉽게 작성하기 위한 프레임워크입니다.
Apache Tez - 데이터를 처리하기 위한 애플리케이션 프레임워크입니다.
Apache Hive - SQL을 사용하여 분산 스토리지에 상주하는 대량 데이터 세트를 쉽게 관리할 수 있습니다.
데이터 분석
Apache Pig – MapReduce에 대한 추상화 레이어를 제공하여 대량 데이터 세트를 분석합니다.
Apache Phoenix - Hadoop에서 OLTP 및 운영 분석을 사용하도록 설정합니다.
Apache Mahout – 고유한 알고리즘을 만들 수 있는 대수 프레임워크입니다.
참고 항목
작성할 때 Azure Data Lake Gen1 및 Azure Blob Storage는 HDInsight용으로 지원되는 데이터 스토리지 레이어입니다. Spark 및 Hadoop용 권장 스토리지 플랫폼이고 HBase의 기본 선택이므로 이 데이터를 Azure Data Lake Gen2로 마이그레이션해야 합니다.