집계 함수를 사용하여 데이터 그룹화
모든 부문의 조직은 끊임없는 데이터 흐름을 처리하고 이 데이터를 의미 있고 유용한 인사이트로 변환해야 합니다. 기상 시나리오에서는 미국의 폭풍우 데이터가 포함된 데이터 세트가 제공되었습니다. 이전 모듈에서는 데이터를 탐색하기 위한 기본 쿼리 생성 방법을 배웠습니다.
이 단원에서는 Kusto 쿼리 언어(KQL)를 사용하여 데이터 그룹을 비교하고 결과를 시각적으로 표시하는 방법을 알아봅니다.
데이터 그룹 비교
폭풍 이벤트 시나리오의 데이터는 이벤트 수준에 표시됩니다. 즉, 각 행이 특정 폭풍 이벤트와 관련 정보를 나타냅니다. 이는 수많은 개별 폭풍들을 나타내며, 개별 이벤트를 확인하여 유의미한 인사이트를 얻기가 어려울 수 있습니다. 이러한 개별 이벤트를 공통 필드(예: 위치)로 그룹화하면 그룹 간에 의미 있는 비교를 수행할 수 있습니다.
집계 함수를 사용하면 여러 행의 값을 그룹화하여 단일 요약 값을 형성함으로써 이러한 비교를 수행할 수 있습니다. 요약 값의 형식은 사용하는 특정 함수에 따라 달라지며 개수, 평균, 최대값, 최소값 또는 중앙값일 수 있습니다. 예를 들어, 다음 그림에서는 위치별 폭풍 유형 수를 요약합니다.

시각적으로 결과 표시
데이터를 그룹화하면 결과에서 인사이트를 얻을 수 있습니다. 쿼리의 기본 출력은 테이블 형식입니다. 그러나 많은 시나리오에서 그래픽 표현은 결과를 더 잘 전달할 수 있습니다. render 연산자를 사용하여 Kusto 쿼리 결과를 그래픽 시각화로 변환하는 몇 가지 방법을 살펴보겠습니다.
사용 가능한 시각화 유형으로는 linechart, columnchart, barchart, piechart, scatterchart, pivotchart 등이 있습니다. 다음 이미지는 꺾은선형 차트, 세로 막대형 차트 및 가로 막대형 차트로 렌더링된 샘플 Kusto 쿼리 결과를 보여줍니다.
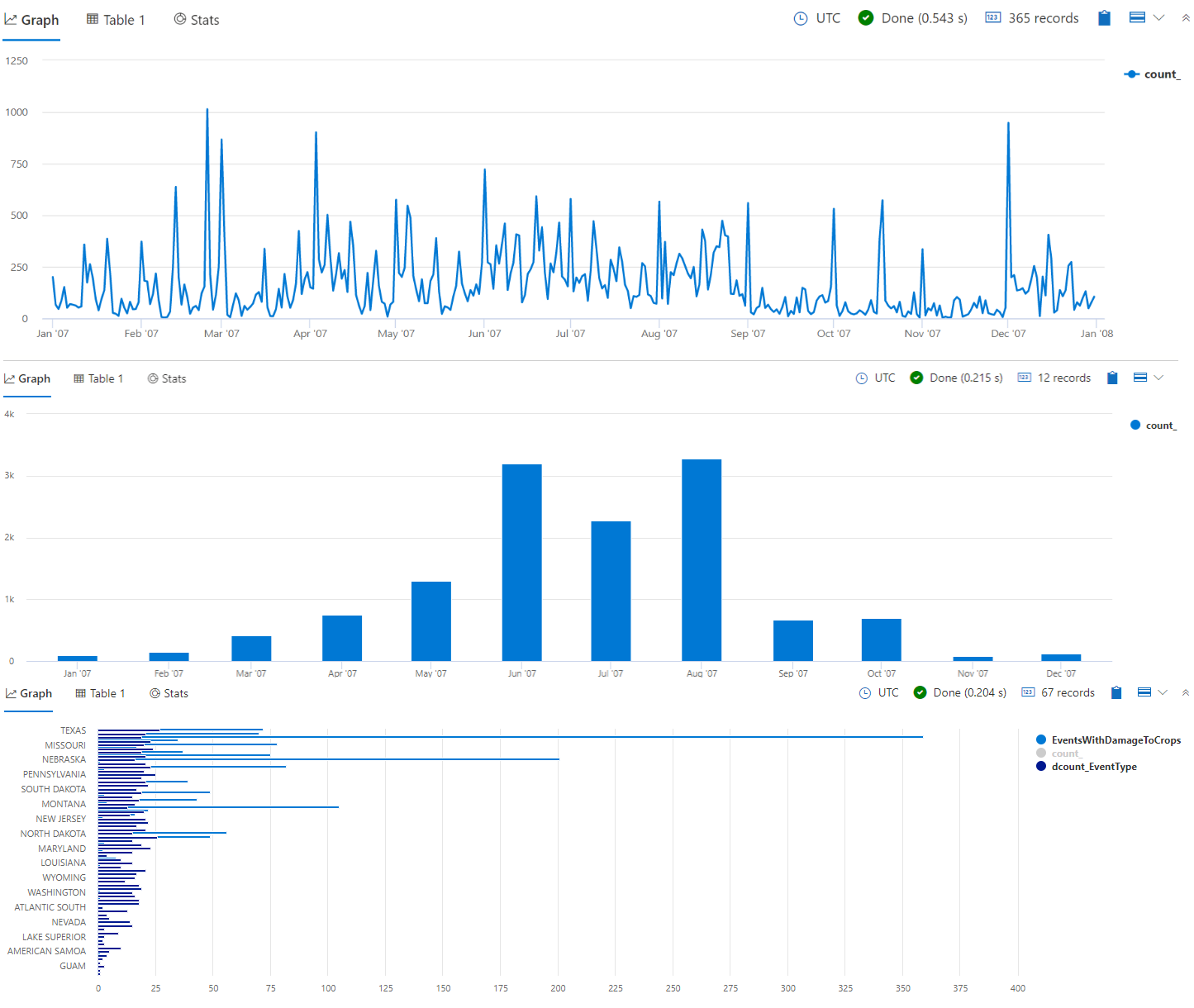
다음 단원에서는 가장 일반적인 집계 함수 중 일부에 대해 알아보고, render 연산자를 사용하여 함수 결과를 시각화한 다음, 복잡한 쿼리를 작성합니다. 이러한 KQL 기술은 미국 기상 데이터를 포함하는 샘플 데이터 세트에 대한 인사이트를 얻는 데 도움이 됩니다.