Azure Cosmos DB API 식별
Azure Cosmos DB는 관계형 및 비관계형 워크로드를 모두 지원하는 모든 크기 또는 규모의 애플리케이션을 위한 Microsoft의 완전 관리형 및 서버리스 분산 데이터베이스입니다. 개발자는 PostgreSQL, MongoDB 및 Apache Cassandra를 비롯한 선호하는 오픈 소스 데이터베이스 엔진을 사용하여 애플리케이션을 빠르게 빌드하고 마이그레이션할 수 있습니다. 새 Cosmos DB 인스턴스를 프로비저닝할 때 사용할 데이터베이스 엔진을 선택합니다. 엔진 선택은 저장할 데이터 형식, 기존 애플리케이션을 지원해야 하는 필요성 및 데이터 저장소로 작업할 개발자의 기술을 비롯한 여러 요인에 따라 달라집니다.
Azure Cosmos DB for NoSQL
Azure Cosmos DB for NoSQL는 문서 데이터 모델 작업을 위한 Microsoft의 네이티브 비관계형 서비스입니다. 이 서비스는 JSON 문서 형식의 데이터를 관리하며 NoSQL 데이터 스토리지 솔루션임에도 불구하고 SQL 구문을 사용하여 데이터를 사용합니다.
고객 데이터를 포함하는 Azure Cosmos DB 데이터베이스에 대한 SQL 쿼리는 다음과 유사할 수 있습니다.
SELECT *
FROM customers c
WHERE c.id = "joe@litware.com"
이 쿼리의 결과는 다음과 같이 하나 이상의 JSON 문서로 구성됩니다.
{
"id": "joe@litware.com",
"name": "Joe Jones",
"address": {
"street": "1 Main St.",
"city": "Seattle"
}
}
Azure Cosmos DB for MongoDB
MongoDB는 데이터가 BSON(Binary JSON) 형식으로 저장되는 인기 있는 오픈 소스 데이터베이스입니다. Azure Cosmos DB for MongoDB를 사용하면 개발자가 MongoDB 클라이언트 라이브러리를 사용하여 Azure Cosmos DB의 데이터로 작업하고 코드를 사용할 수 있습니다.
MQL(MongoDB 쿼리 언어)은 개발자가 개체를 사용하여 메서드를 호출하는 컴팩트한 개체 지향 구문을 사용합니다. 예를 들어 다음 쿼리는 찾기 메서드를 사용하여 db 개체의 제품 컬렉션을 쿼리합니다.
db.products.find({id: 123})
이 쿼리의 결과는 다음과 유사한 JSON 문서로 구성됩니다.
{
"id": 123,
"name": "Hammer",
"price": 2.99
}
Azure Cosmos DB for PostgreSQL
Azure Cosmos DB for PostgreSQL은 Azure의 분산형 PostgreSQL 옵션입니다. Azure Cosmos DB for PostgreSQL은 확장성 있는 앱을 빌드하는 데 도움이 되도록 데이터를 자동으로 분할하는 전역으로 분산된 관계형 데이터베이스인 네이티브 PostgreSQL입니다. 다른 데서도 PostgreSQL에서와 동일한 방식으로 단일 노드 서버 그룹에서 앱 빌드를 시작할 수 있습니다. 앱의 확장성 및 성능 요구 사항이 증가함에 따라 테이블을 투명하게 배포하여 여러 노드로 원활하게 확장할 수 있습니다. PostgreSQL은 데이터의 관계형 테이블을 정의하는 RDBMS(관계형 데이터베이스 관리 시스템)입니다. 예를 들어 다음과 같은 제품 테이블을 정의할 수 있습니다.
| ProductID | ProductName | 가격 |
|---|---|---|
| 123 | 망치 | 2.99 |
| 162 | Screwdriver | 3.49 |
그런 다음 이 테이블을 쿼리하여 다음과 같이 SQL을 사용하여 특정 제품의 이름과 가격을 검색할 수 있습니다.
SELECT ProductName, Price
FROM Products
WHERE ProductID = 123;
이 쿼리의 결과에는 다음과 같이 제품 123에 대한 행이 포함됩니다.
| ProductName | 가격 |
|---|---|
| 망치 | 2.99 |
Azure Cosmos DB for Table
Azure Cosmos DB for Table은 Azure Table Storage와 유사한 키-값 테이블의 데이터로 작업하는 데 사용됩니다. Azure Table Storage보다 뛰어난 확장성과 성능을 제공합니다. 예를 들어 다음과 같이 Customers라는 테이블을 정의할 수 있습니다.
| PartitionKey | RowKey | 속성 | |
|---|---|---|---|
| 1 | 123 | Joe Jones | joe@litware.com |
| 1 | 124 | Samir Nadoy | samir@northwind.com |
그런 다음 언어별 SDK 중 하나를 통해 Table API를 사용하여 서비스 엔드포인트를 호출한 후 테이블에서 데이터를 검색할 수 있습니다. 예를 들어 다음 요청은 이전 표에서 Samir Nadoy에 대한 레코드가 포함된 행을 반환합니다.
https://endpoint/Customers(PartitionKey='1',RowKey='124')
Azure Cosmos DB for Apache Cassandra
Azure Cosmos DB for Apache Cassandra는 열 패밀리 스토리지 구조를 사용하는 인기 있는 오픈 소스 데이터베이스인 Apache Cassandra와 호환됩니다. 열 패밀리는 관계형 데이터베이스의 테이블과 유사하며 모든 행에 동일한 열을 포함해야 하는 것은 아닙니다.
예를 들어 다음과 같이 Employees 테이블을 만들 수 있습니다.
| ID | 속성 | Manager |
|---|---|---|
| 1 | Sue Smith | |
| 2 | Ben Chan | Sue Smith |
Cassandra는 SQL을 기반으로 하는 구문을 지원하므로 클라이언트 애플리케이션은 다음과 같이 Ben Chan에 대한 레코드를 검색할 수 있습니다.
SELECT * FROM Employees WHERE ID = 2
Azure Cosmos DB for Apache Gremlin
Azure Cosmos DB for Apache Gremlin은 그래프 구조의 데이터와 함께 사용되며 엔터티가 연결된 그래프에서 노드를 형성하는 꼭짓점으로 정의됩니다. 노드는 다음과 같이 관계를 나타내는 에지에 의해 연결됩니다.
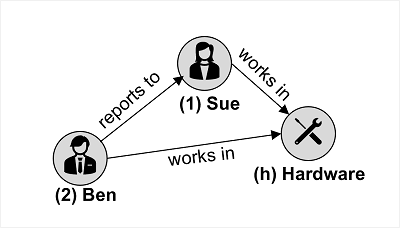
이미지의 예제에서는 두 종류의 꼭짓점(직원 및 부서)과 이를 연결하는 에지(직원 “Ben”은 직원 “Sue”에 보고하고 두 직원 모두 “하드웨어” 부서에서 근무)를 보여 줍니다.
Gremlin 구문에는 꼭짓점 및 에지에서 작동하는 함수가 포함되어 있어 그래프에서 데이터를 삽입, 업데이트, 삭제 및 쿼리할 수 있습니다. 예를 들어 다음 코드를 사용하여 ID가 1(Sue)인 직원에게 보고하는 Alice라는 새 직원을 추가할 수 있습니다.
g.addV('employee').property('id', '3').property('firstName', 'Alice')
g.V('3').addE('reports to').to(g.V('1'))
다음 쿼리는 ID 순서로 모든 직원 꼭짓점을 반환합니다.
g.V().hasLabel('employee').order().by('id')