KQL 쿼리를 빌드하는 방법
이제 쿼리 언어의 작동 방식과 KQL을 사용할 수 있는 위치를 살펴보았으므로 KQL 쿼리가 빌드되는 방식을 살펴보겠습니다.
KQL 쿼리 구조
KQL 쿼리는 데이터를 처리하고 결과를 반환하기 위한 읽기 전용 요청입니다. 요청은 쉽게 읽고 작성하고 자동화할 수 있는 데이터 흐름 모델을 사용하여 일반 텍스트로 서술됩니다.
쿼리 언어에 따라 구조가 다른 경우가 많습니다. KQL은 데이터가 처리되는 방식에 따라 구성됩니다. 각 KQL 쿼리는 데이터 원본으로 시작합니다. 그런 다음, 필터를 사용하여 조건을 통과하고, 순서를 지정하고, 더 축소하여 데이터를 처리합니다.
데이터 처리
데이터가 데이터 처리 깔때기를 통해 이동한다고 상상해 보세요. 테이블 형식 입력은 데이터 유입 경로의 시작입니다. 이 데이터는 다음 줄로 파이프되며 연산자를 사용하여 필터링되거나 조작됩니다. 살아남은 데이터는 최종 쿼리 출력에 도착할 때까지 후속 줄로 파이프됩니다. 이 쿼리 출력은 테이블 형식으로 반환됩니다.
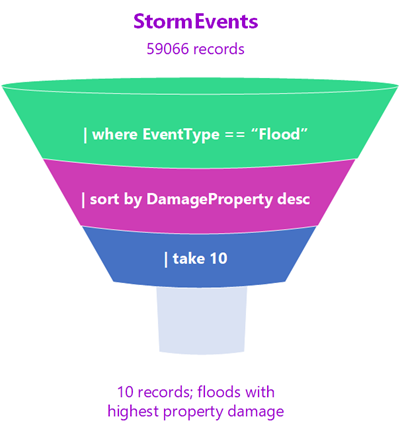
필터 도형에서 깔때기의 “위쪽”에 있는 데이터가 끝의 데이터 크기보다 크게 시작되는 것을 볼 수 있습니다. 가장 많은 양의 데이터를 제거하는 단계는 일반적으로 쿼리 시작 부분에 사용됩니다. 이렇게 하면 다음 연산자는 처리할 데이터 양이 적어지고 쿼리 결과가 빠르게 반환됩니다. 실제로 KQL의 장점 중 하나는 매우 다양한 대량의 데이터를 신속하게 처리할 수 있다는 것입니다.