분석 데이터 처리 살펴보기
분석 데이터 방대한 양의 기록 데이터 또는 비즈니스 메트릭을 저장하는 읽기 전용(대부분 읽기) 시스템을 주로 사용합니다. 분석은 특정 시점의 데이터 스냅샷 또는 일련의 스냅샷을 기반으로 할 수 있습니다.
분석 처리 시스템의 구체적인 세부 사항은 솔루션에 따라 다를 수 있으나, 엔터프라이즈 규모 분석의 공통적인 아키텍처는 다음과 같습니다.
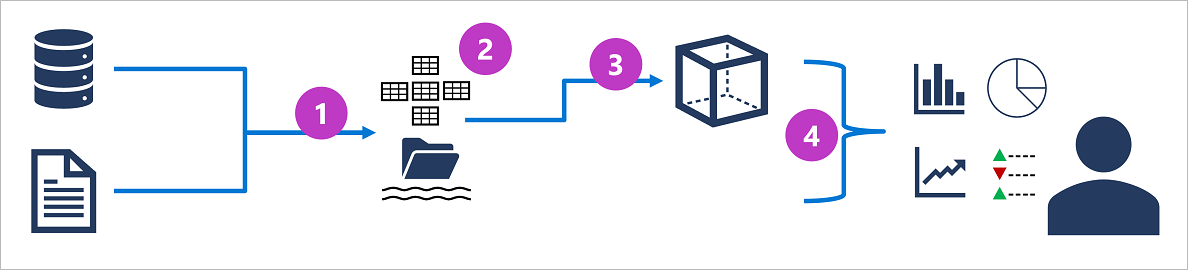
- 작동 데이터가 분석을 위해 데이터 레이크로 추출, 변환 및 로드(ETL)됩니다.
- 데이터가 테이블 스키마로 로드됩니다. 일반적으로 데이터 레이크의 파일에 대한 테이블 형식 추상화가 있는 Spark 기반 데이터 레이크하우스 또는 완전 관계형 SQL 엔진이 있는 데이터 웨어하우스에서 로드됩니다.
- 데이터 웨어하우스의 데이터는 집계하여 OLAP(온라인 분석 처리) 모델(큐브)에 로드할 수 있습니다. 팩트 테이블의 집계된 숫자 값(측정값)은 차원 테이블의 차원의 교집합에 대해 계산됩니다. 예를 들어, 판매 수익을 날짜, 고객, 제품을 기준으로 합산할 수 있습니다.
- 데이터 레이크, 데이터 웨어하우스 및 분석 모델의 데이터를 쿼리하여 보고서, 시각화 및 대시보드를 생성할 수 있습니다.
데이터 레이크는 대규모 데이터 분석 처리 시나리오에서 공통으로 나타나는 요소로, 대량의 파일 기반 데이터가 수집되어 분석되는 곳입니다.
데이터 웨어하우스는 읽기 작업(주로 보고 및 데이터 시각화를 지원하는 쿼리)에 최적화된 관계형 스키마에 데이터를 저장하는 확립된 방법입니다. 데이터 레이크하우스는 데이터 레이크의 유연하고 확장성 있는 스토리지와 데이터 웨어하우스의 관계형 쿼리 의미 체계가 결합한 최신 혁신의 결과물입니다. 테이블 스키마는 OLTP 데이터 원본에 있는 데이터의 비정규화(쿼리가 더 빠르게 수행되도록 얼마간의 중복을 도입하는 작업)를 요구할 수 있습니다
OLAP 모델은 분석 워크로드에 최적화된 데이터 스토리지의 집계된 유형입니다. 데이터 집계는 여러 수준에서 여러 차원에 걸쳐 이루어지기 때문에 어려 계층 구조 수준에서 드릴업/드릴다운하여 집계를 볼 수 있습니다(예: 지역, 도시 또는 개별 주소의 판매 합계 찾기). OLAP 데이터는 미리 집계되어 있기 때문에 OLAP 데이터에 포함된 요약을 반환하는 쿼리가 빠르게 실행될 수 있습니다.
전체 아키텍처의 여러 스테이지에서 다양한 유형의 사용자가 데이터 분석 작업을 수행할 수 있습니다. 예:
- 데이터 과학자는 데이터 레이크에 있는 데이터 파일로 직접 작업하여 데이터를 살펴보고 모델링할 수 있습니다.
- 데이터 분석가는 데이터 웨어하우스에 있는 테이블을 직접 쿼리하여 복합적인 보고서 및 시각화를 생성할 수 있습니다.
- 비즈니스 사용자는 분석 모델의 미리 집계된 데이터를 보고서 또는 대시보드 형태로 소비할 수 있습니다.