Azure Databricks 시작
Azure Databricks는 데이터 엔지니어링, 기계 학습 및 분석을 위한 통합 환경을 제공하는 클라우드 기반 데이터 분석 플랫폼입니다. Azure Databricks는 리더십으로 Apache Spark를 만든 Databricks와 협업하여 설계되었습니다. Azure Databricks는 빠르고 쉽고 협동적인 Apache Spark 기반 분석 서비스를 제공합니다. 이 플랫폼은 Azure의 다른 서비스와 긴밀하게 통합되어 사용자에게 보안 강화, 성능 및 확장성을 제공하는 원활한 환경을 제공합니다. 데이터 준비, 기계 학습, 데이터 과학 워크플로와 같은 데이터 기반 작업을 지원하므로 빅 데이터의 힘을 활용하려는 조직에 적합한 다양한 도구입니다.
Azure Databricks의 주요 기능으로는 Microsoft Entra ID와의 네이티브 통합과 Azure Storage, Azure Data Lake Storage, Azure Cosmos DB 등 다른 Azure 서비스를 사용할 수 있는 기능이 있습니다. 이 플랫폼은 또한 데이터 과학자, 데이터 엔지니어 및 비즈니스 분석가 간의 협업을 용이하게 하는 대화형 작업 영역을 제공합니다. 이 협업 환경은 Python, Scala, R, SQL과 같은 다양한 프로그래밍 언어를 지원하여 팀이 효율적으로 데이터 모델을 개발하고 반복할 수 있도록 합니다. 또한 Azure Databricks는 기계 학습 알고리즘의 계산 요구 사항과 대규모 데이터 세트의 처리 요구 사항을 모두 관리하여 쉽게 크기 조정할 수 있도록 설계되었습니다.
Azure Databricks 작업 영역 만들기
Azure Databricks를 사용하려면 Azure 구독에서 Azure Databricks 작업 영역을 만들어야 합니다. 이렇게 되도록 하려면 다음 작업을 수행하세요.
- Azure Portal 사용자 인터페이스 사용
- ARM(Azure Resource Manager) 또는 Bicep 템플릿 사용
- New-AzDatabricksWorkspace Azure PowerShell cmdlet 사용
- az databricks workspace create Azure CLI(명령줄 인터페이스) 명령 사용
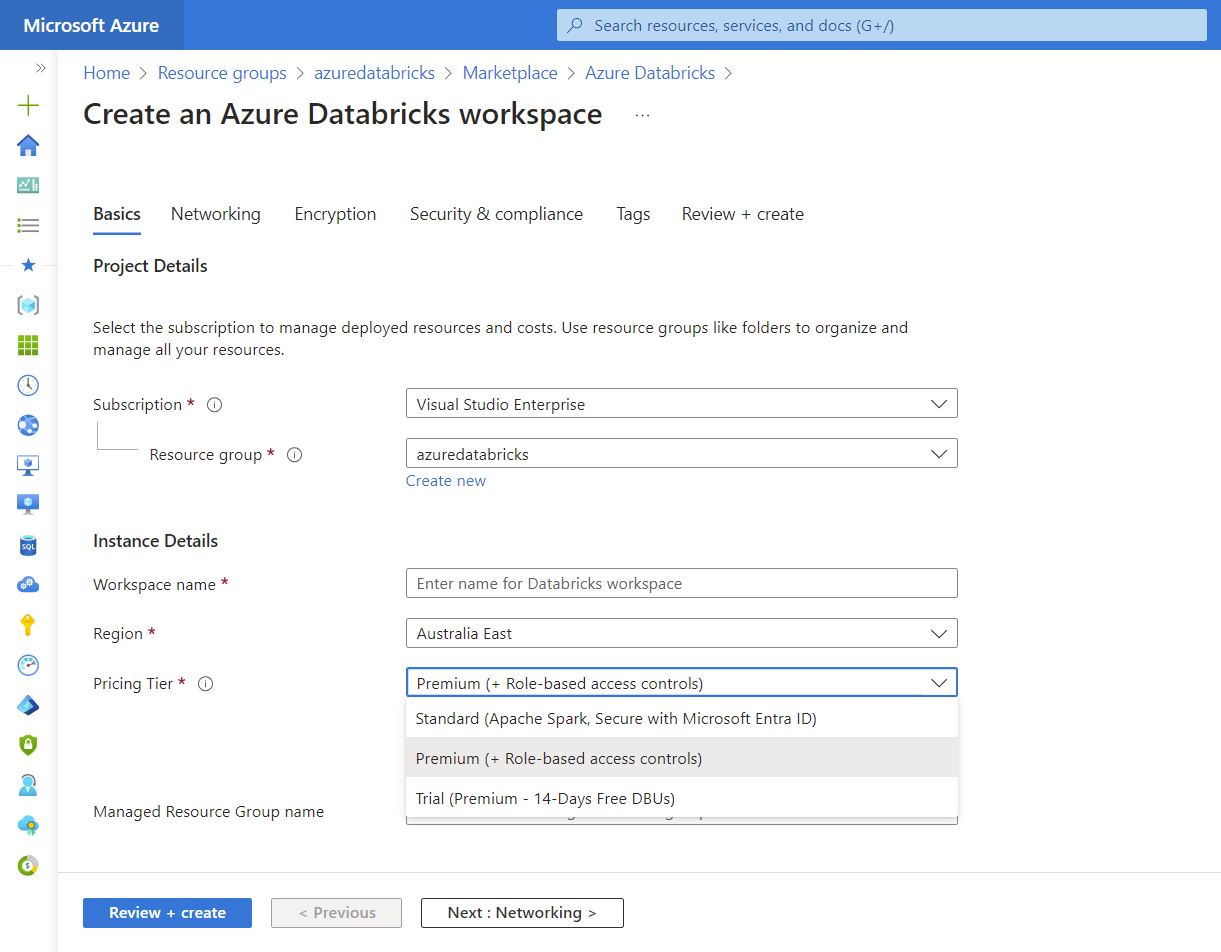
작업 영역을 만들 때 다음 가격 책정 계층 중 하나를 지정해야 합니다.
- 표준 - Microsoft Entra 통합을 사용하는 핵심 Apache Spark 기능입니다.
- 프리미엄 - 역할 기반 액세스 제어 및 기타 엔터프라이즈 수준 기능입니다.
- 평가판 - 프리미엄 수준 작업 영역의 14일 평가판
Azure Databricks 포털 사용
Azure Databricks 작업 영역을 프로비전한 후 Azure Databricks 포털을 사용하여 데이터 및 컴퓨팅 리소스를 작업할 수 있습니다. Azure Databricks 포털은 Spark 클러스터와 같은 작업 영역 리소스를 만들고 관리하고, Notebook 및 쿼리를 사용하여 파일과 테이블의 데이터로 작업할 수 있는 웹 기반 사용자 인터페이스입니다.
