Azure Data Lake를 사용하여 데이터 통합 솔루션 디자인
Data Lake는 일반적으로 Blob 또는 파일로서 해당 기본 형식으로 저장된 데이터의 리포지토리입니다. Azure Data Lake Storage는 Azure에 구축된 빅 데이터 분석을 위한 포괄적이며, 확장성 있고, 비용 효율적인 데이터 레이크 솔루션입니다. Azure Data Lake Storage는 파일 시스템과 스토리지 플랫폼을 결합하여 데이터에 대한 인사이트를 빠르게 파악할 수 있도록 지원합니다. 솔루션은 분석 워크로드에 대한 최적화를 제공하기 위해 Azure Blob Storage 기능을 기반으로 합니다. 이러한 통합을 통해 Azure Storage의 분석 성능, 고가용성, 보안 및 내구성 기능을 사용할 수 있습니다.
참고
현재 구현된 서비스는 Azure Data Lake Storage Gen2입니다.
Azure Data Lake Storage에 대해 알아야 할 사항
Azure Data Lake Storage를 보다 잘 이해하기 위해 다음과 같은 특성을 검토할 수 있습니다.
- Azure Data Lake Storage는 데이터의 네이티브 형식을 사용하여 모든 형식의 데이터를 저장할 수 있습니다. 데이터 형식 및 대규모 데이터 크기를 지원하므로 Azure Data Lake Storage는 정형, 반정형 및 비정형 데이터에 작용할 수 있습니다.
- 이 솔루션은 기본적으로 Hadoop, Apache HDFS(Hadoop 분산 파일 시스템)를 데이터 액세스 계층으로 사용하는 모든 프레임워크에서 사용할 수 있도록 설계되었습니다. HDFS를 데이터 액세스 계층으로 사용하는 데이터 분석 프레임워크는 직접 액세스할 수 있습니다.
- Azure Data Lake Storage는 입출력 집약적인 분석 및 데이터 이동을 위해 높은 처리량을 지원합니다.
- Azure Data Lake Storage 액세스 제어 모델은 Azure RBAC(Azure 역할 기반 액세스 제어)와 POSIX(Portable Operating System Interface for UNIX) ACL(액세스 제어 목록)을 모두 지원합니다.
- Azure Data Lake Storage는 Azure Blob 복제 모델을 활용합니다. 이러한 모델은 LRS(로컬 중복 스토리지)를 통해 단일 데이터 센터에서 데이터 중복성을 제공합니다.
- Azure Data Lake Storage는 대규모 스토리지를 제공하며 다양한 데이터 형식의 분석을 허용합니다.
- Azure Data Lake Storage는 Azure Blob Storage 수준에서 가격이 책정됩니다.
Azure Data Lake Storage 작동 방식
Azure Data Lake Storage를 사용하는 데는 세 가지 중요한 단계가 있습니다.
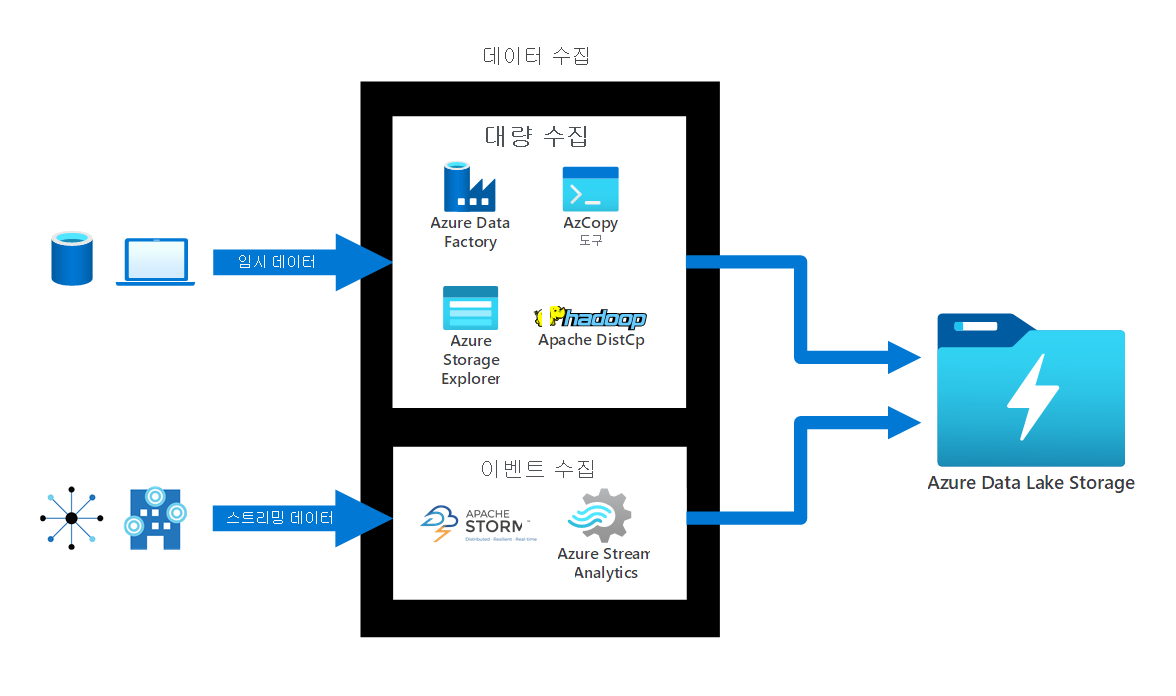
데이터 수집. Azure Data Lake Storage는 다양한 데이터 수집 방법을 제공합니다.
- 계획되지 않은 데이터의 경우 AzCopy, Azure CLI, PowerShell 및 Azure Storage Explorer 같은 도구를 사용할 수 있습니다.
- 관계형 데이터의 경우 Azure Data Factory 서비스를 사용합니다. Azure Cosmos DB, SQL Database, Azure SQL Managed Instance 등과 같은 모든 원본에서 데이터를 전송할 수 있습니다.
- 스트리밍 데이터의 경우 Azure HDInsight 기반 Apache Storm, Azure Stream Analytics 등과 같은 도구를 사용합니다.
다음 다이어그램에서는 계획되지 않은 데이터 및 스트리밍 데이터가 Azure Data Lake Storage에 대량으로 수집되거나 계획되지 않고 수집되는 방식을 보여 줍니다.
저장된 데이터에 액세스. 데이터에 액세스하는 가장 쉬운 방법은 Azure Storage Explorer를 사용하는 것입니다. Storage Explorer는 Azure Data Lake Storage 데이터에 액세스하기 위해 GUI(그래픽 사용자 인터페이스)를 사용하는 독립 실행형 애플리케이션입니다. PowerShell, Azure CLI, HDFS CLI 또는 기타 프로그래밍 언어 SDK를 사용하여 데이터에 액세스할 수도 있습니다.
액세스 제어 구성. 권한 부여 메커니즘을 구현하여 Azure Data Lake Storage 저장된 데이터에 액세스할 수 있는 사용자를 제어합니다. Azure RBAC 또는 ACL을 선택할 수 있습니다.
비즈니스 시나리오
Tailwind Traders는 웹 사이트, POS(Point of Sale) 시스템, 소셜 미디어 사이트, IoT(사물 인터넷) 디바이스 등 여러 원본의 데이터를 보유하고 있습니다. 이 회사는 Azure를 사용하여 모든 비즈니스 데이터를 분석하는 데 관심이 있습니다. Azure에서 기존 BI 시스템을 향상시킬 수 있는 방법에 대한 지침을 제공해야 합니다. Azure Storage 기능이 회사의 BI 솔루션에 가치를 더하는 방법에 대해 팀에 조언해야 합니다. 데이터 요구 사항을 충족하기 위해 Azure Data Lake Storage를 권장할 계획입니다. Data Lake Storage는 고성능 빅 데이터 분석을 위해 엄청난 양의 비정형 데이터를 업로드하고 저장할 수 있는 리포지토리를 제공합니다.
Azure Data Lake Storage 조직의 빅 데이터 요구 사항에 적합한 선택이 될 수 있는 방법을 검토해 보겠습니다.
| 시나리오 | 솔루션 |
|---|---|
| 대량 데이터를 관리하기 위해 클라우드에서 데이터 웨어하우스를 제공합니다. | Azure Data Lake Storage는 Azure 플랫폼의 가상 하드웨어에서 실행합니다. 스토리지는 대규모 요금이 발생하지 않고 스케일링 가능하고 빠르며 안정적입니다. 스토리지 비용이 컴퓨팅 비용과 구분됩니다. 데이터 볼륨이 증가하면서 스토리지 요구 사항만 달라집니다. |
| JSON 파일, CSV, 로그 파일 또는 기타 형식과 같은 다양한 유형의 데이터 수집을 지원합니다. | Azure Data Lake Storage를 사용하면 모든 데이터 형식(원시 데이터 포함)을 단일 위치에 저장하여 조직의 데이터를 민주화할 수 있습니다. 데이터 사일로를 제거하면 사용자는 Azure Data Explorer와 같은 도구를 사용하여 스토리지 계정의 모든 데이터 항목에 액세스하고 작업할 수 있습니다. |
| 실시간 데이터 수집 및 스토리지를 활성화합니다. | Azure Data Lake Storage는 Azure HDInsight 기반 Apache Storm, Azure IoT Hub, Azure Event Hubs 또는 Azure Stream Analytics 인스턴스에서 직접 실시간 데이터를 수집할 수 있습니다. 또한 반구조적 데이터에서도 작동하며 모든 실시간 데이터를 스토리지 계정에 수집할 수 있습니다. |
Azure Blob Storage 또는 Azure Data Lake를 선택할 때 고려할 사항
다음 표에서는 Azure Blob Storage 및 Azure Data Lake를 사용할 경우의 스토리지 솔루션 조건을 비교합니다. 조건을 검토하고 Tailwind Traders에 가장 적합한 솔루션을 고려합니다.
| 비교 | Azure 데이터 레이크 | Azure Blob Storage |
|---|---|---|
| 데이터 형식 | 대량의 텍스트 데이터를 저장하는 데 적합합니다. | 사진, 비디오, 백업 등과 같은 구조화되지 않은 비 텍스트 기반 데이터를 저장하는 데 적합합니다. |
| 지리적 중복 | 데이터 복제를 수동으로 구성해야 합니다. | 기본적으로 지역 중복 스토리지를 제공합니다. |
| 네임스페이스 | 계층 구조 네임스페이스를 지원합니다. | 플랫 네임스페이스를 지원합니다. |
| Hadoop 호환성 | Hadoop 서비스는 Azure Data Lake에 저장된 데이터를 사용할 수 있습니다. | 애플리케이션 및 프레임워크는 Azure Blob Filesystem Driver를 사용하여 Azure Blob Storage의 데이터에 액세스할 수 있습니다. |
| 보안 | 세분화된 액세스 지원 | 세분화된 액세스가 지원되지 않습니다. |