Azure Data Factory 구성 요소 이해
Azure 구독에는 하나 이상의 Azure Data Factory 인스턴스가 있을 수 있습니다. Azure Data Factory는 네 가지 핵심 구성 요소로 구성됩니다. 이러한 구성 요소는 함께 작동하여 데이터를 이동하고 변환하는 단계를 사용하여 데이터 기반 워크플로를 작성할 수 있는 플랫폼을 제공합니다.
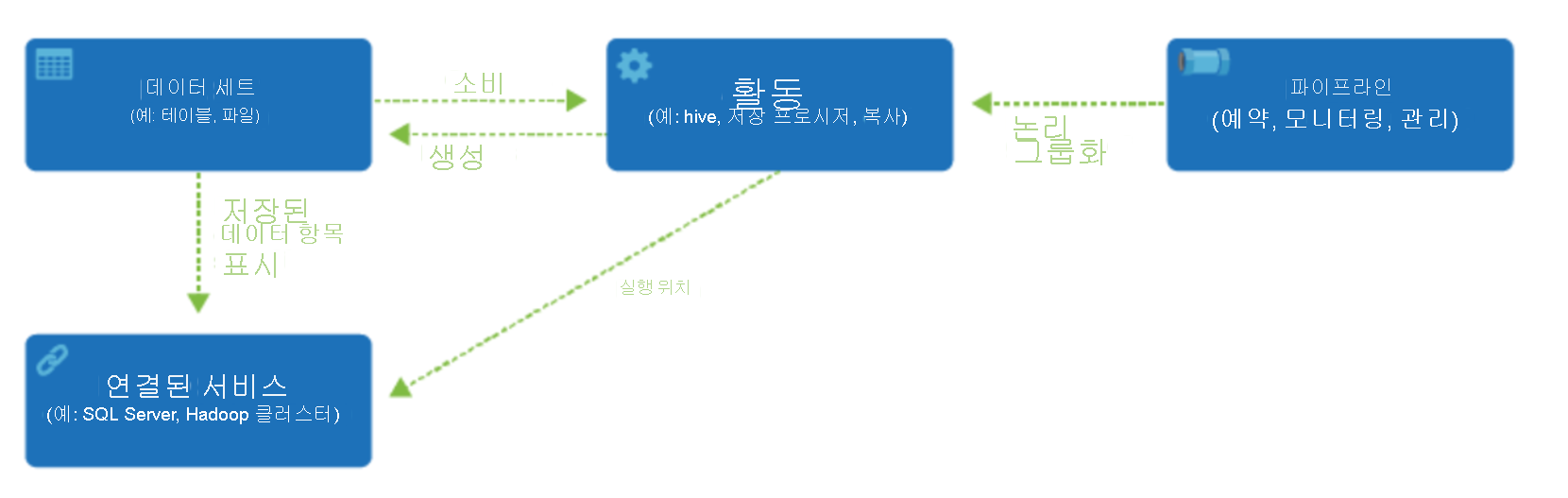
Data Factory는 연결된 서비스라고 알려진 개체를 만들어 연결할 수 있는 다양한 데이터 원본을 지원합니다. 이 개체를 사용하면 준비된 데이터 원본에서 데이터를 수집하여 변환 및/또는 분석을 위한 데이터를 준비할 수 있습니다. 또한 연결된 서비스는 주문형으로 컴퓨팅 서비스를 실행할 수 있습니다. 예를 들어 Hive 쿼리를 통해 데이터를 처리하는 용도로 주문형 HDInsight 클러스터를 시작해야 하는 요구 사항이 있을 수 있습니다. 따라서 연결된 서비스를 사용하면 데이터 원본 또는 데이터를 수집하고 준비하는 데 필요한 컴퓨팅 리소스를 정의할 수 있습니다.
연결된 서비스를 정의하면, Azure Data Factory는 데이터 세트 개체 생성를 통해 사용해야 하는 데이터 세트를 인식합니다. 데이터 세트는 연결된 서비스 개체에서 참조하는 데이터 저장소 내의 데이터 구조를 나타냅니다. 작업이라고 하는 ADF 개체에서 데이터 세트를 사용할 수도 있습니다.
작업에는 일반적으로 Azure Data Factory 작업의 변환 논리 또는 분석 명령이 포함됩니다. 작업에는 다양한 데이터 원본에서 데이터를 수집하는 데 사용할 수 있는 복사 작업이 포함됩니다. 코드 없는 데이터 변환을 수행하기 위한 매핑 데이터 흐름이 포함될 수도 있습니다. 또한 데이터 변환을 위한 저장 프로시저, Hive 쿼리 또는 Pig 스크립트의 실행이 포함될 수 있습니다. 데이터를 Machine Learning 모델에 푸시하여 분석을 수행할 수 있습니다. SQL 저장 프로시저를 사용하여 데이터를 변환한 다음 Databricks를 사용하여 분석을 수행하는 것을 포함하여 여러 작업이 발생하는 것은 드문 일이 아닙니다. 이 경우 여러 작업을 파이프라인이라고 하는 개체와 논리적으로 그룹화하여 실행하도록 예약할 수 있습니다. 또는 파이프라인 실행을 시작해야 하는 시기를 결정하는 트리거를 정의할 수 있습니다. 다양한 유형의 이벤트에 대한 다른 종류의 트리거가 있습니다.
흐름 제어는 파이프라인 수준에서 시퀀스, 분기, 매개 변수 정의의 작업 연결 그리고 주문형으로 또는 트리거에서 파이프라인을 호출할 때 인수 전달을 포함하는 파이프라인 작업의 조율입니다. 또한 사용자 지정 상태 전달 및 컨테이너 루핑, 그리고 For-each 반복기도 포함합니다.
매개 변수는 읽기 전용 구성의 키-값 쌍입니다. 매개 변수는 파이프라인에서 정의됩니다. 정의된 매개 변수에 대한 인수는 트리거에 의해 만들어진 실행 컨텍스트 또는 수동으로 실행한 파이프라인에서 실행하는 동안 전달됩니다. 파이프라인 내의 작업은 매개 변수 값을 사용합니다.
Azure Data Factory에는 작업과 연결된 서비스 개체 간의 연결을 설정하는 통합 런타임이 있습니다. 이는 연결된 서비스에 의해 참조되며 작업이 실행하거나 디스패치되는 컴퓨팅 환경을 제공합니다. 이렇게 하여 가능한 가장 가까운 지역에서 작업을 수행할 수 있습니다. Integration Runtime에는 Azure, 자체 호스팅, Azure-SSIS의 세 가지 유형이 있습니다.
모든 작업이 완료되면 Data Factory를 사용하여 최종 데이터 세트를 다른 연결된 서비스에 게시할 수 있습니다. 그러면 Power BI 또는 Machine Learning 등의 기술에서 이 서비스를 사용할 수 있습니다.