모델 이해 및 테스트
기계 학습 모델을 만들었습니다. 테스트하여 모델의 성능을 살펴보겠습니다.
모델 성능
모델을 테스트하면 Custom Vision에 세 가지 메트릭이 표시됩니다. 메트릭은 모델의 성능을 이해하는 데 도움이 되는 지표입니다. 지표는 모델이 얼마나 사실에 기반하는지 또는 정확한지를 나타내지 않습니다. 지표는 제공한 데이터에서의 모델 성능만 알려 줍니다. 알려진 데이터에서의 모델 성능을 알면 새 데이터에서의 모델 성능을 예상할 수 있습니다.
전체 모델 및 각 클래스에 대해 다음과 같은 메트릭이 제공됩니다.
| 메트릭 | 설명 |
|---|---|
precision |
모델이 태그를 예측하는 경우 이 메트릭은 올바른 태그가 예측되었을 가능성을 나타냅니다. |
recall |
이 메트릭은 모델이 올바르게 예측해야 하는 태그 중에서 모델이 올바르게 예측한 태그의 비율을 나타냅니다. |
average precision |
이 메트릭은 다양한 임계값에서 정밀도와 재현율을 계산하여 모델 성능을 측정합니다. |
Custom Vision 모델을 테스트하면 반복 테스트 결과에서 이러한 각 메트릭의 숫자를 볼 수 있습니다.
일반적인 실수
모델을 테스트하기 전에 기계 학습 모델 빌드를 처음 시작할 때 조심해야 할 "초보자의 실수"를 살펴보겠습니다.
불균형 데이터 사용
모델을 배포할 때 다음과 같은 경고가 표시될 수 있습니다.
Unbalanced data detected. The distribution of images per tag should be uniform to ensure model performance.
이 경고는 각 데이터 클래스의 샘플 수가 균일하지 않음을 나타냅니다. 이 시나리오에 여러 옵션이 있지만 불균형 데이터를 해결하는 일반적인 방법은 SMOTE(Synthetic Minority Over-sampling Technique)를 사용하는 것입니다. SMOTE는 기존 학습 풀의 학습 예제를 복제합니다.
참고
이 모델에서는 특히 데이터 세트의 일부를 업로드한 경우 이 경고가 표시되지 않을 수 있습니다. 빨간색 꼬리 호크(다크 모핑) 모델 데이터 하위 집합에는 사진이 100개 이상 있는 다른 모델에 비해 60개 미만의 사진이 포함되어 있습니다. 불균형 데이터를 사용하는 것은 모든 기계 학습 모델에서 주의해야 할 일입니다.
모델 과적합
데이터가 충분하지 않거나 데이터가 충분히 다양하지 않은 경우 모델이 과적합될 수 있습니다. 모델이 과적합되면 모델은 제공된 데이터 세트를 잘 알게 되고 해당 데이터의 패턴에 과적합됩니다. 이 경우 모델은 학습 데이터에서는 성능이 좋지만 이전에 본 적 없는 새 데이터에서는 성능이 저하됩니다. 그래서 모델을 테스트할 때는 항상 새 데이터를 사용하는 것입니다.
학습 데이터를 사용하여 테스트
과적합에서와 마찬가지로 모델을 학습시키는 데 사용한 것과 동일한 데이터를 사용하여 모델을 테스트하면 모델의 성능이 좋은 것처럼 보입니다. 하지만 프로덕션 환경에 모델을 배포하면 성능이 나쁠 가능성이 높습니다.
잘못된 데이터 사용
또 다른 일반적인 실수는 잘못된 데이터를 사용하여 학습시키는 것입니다. 일부 데이터는 실제로 모델의 정확도를 낮출 수 있습니다. 예를 들어 "잡음이 있는" 데이터를 사용하면 모델의 정확도가 떨어질 수 있습니다. 잡음이 있는 데이터에서는 유용하지 않은 정보가 데이터 세트에 너무 많아 모델의 혼동을 야기합니다. 데이터는 많을수록 좋다는 말은 모델이 사용할 수 있는 좋은 데이터인 경우에만 맞습니다. 모델 정확도를 향상시키기 위해 데이터를 삭제하거나 특성을 제거해야 할 수도 있습니다.
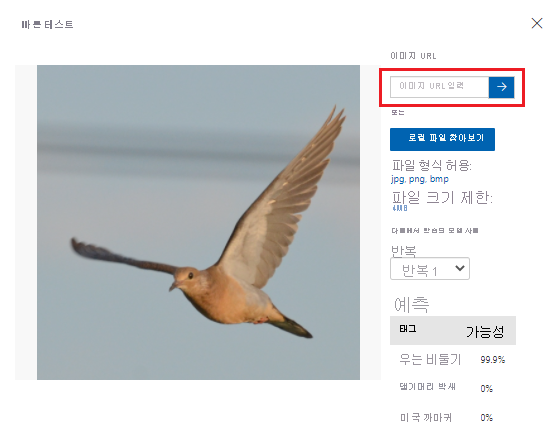
모델 테스트
Custom Vision이 제공하는 메트릭에 따르면 모델의 성능이 만족스러운 수준입니다. 이제 모델을 테스트하고 보이지 않는 데이터에서 어떻게 수행되는지 살펴보겠습니다. 인터넷 검색에서 얻은 조류의 이미지를 사용하겠습니다.
웹 브라우저에서 모델이 인식하도록 학습시켰던 종 중 하나와 일치하는 조류의 이미지를 검색합니다. 이미지의 URL을 복사합니다.
Custom Vision 포털에서 조류 분류 프로젝트를 선택합니다.
맨 위의 메뉴 모음에서 빠른 테스트를 선택합니다.
빠른 테스트에서 이미지 URL에 URL을 붙여넣은 다음 Enter 키를 눌러 모델의 정확도를 테스트합니다. 예측은 창에 표시됩니다.
Custom Vision이 이미지를 분석하여 모델의 정확도를 테스트하고 결과를 표시합니다.
다음 단계에서는 모델을 배포합니다. 모델 배포 후에는 만든 엔드포인트를 사용하여 더 많은 테스트를 수행할 수 있습니다.