HDInsight Spark 클러스터에서 Jupyter Notebook 열기
HDInsight Spark 클러스터가 만들어진 후 Azure HDInsight에서 Apache Spark 클러스터에 관해 대화형 Spark SQL 쿼리 또는 작업을 실행할 수 있습니다. 이렇게 하려면 먼저 노트북을 만들어야 합니다. 노트북은 데이터 엔지니어 및 데이터 과학자가 다양한 언어를 사용하여 데이터와 상호 작용하는 데 사용되는 대화형 편집기입니다. 여기에는 Python, SQL, Scala 및 기타 언어가 포함될 수 있습니다. HDInsight는 데이터와 상호 작용을 위해 Jupyter, Zeppelin 및 Livy를 지원합니다. 상호 작용 수준은 관리 중인 워크로드에 따라 달라집니다.
HDInsight에서 Apache Spark는 다음 워크로드를 지원합니다.
대화형 데이터 분석 및 BI
노트북을 사용하여 비정형/반정형 데이터를 수집하고 노트북 내에서 스키마를 정의할 수 있습니다. 그런 다음, 스키마를 사용하여 비즈니스 사용자가 노트북에서 데이터에 대한 데이터 분석을 수행할 수 있도록 하는 Power BI 같은 도구에서 모델을 만들 수 있습니다.
Spark Machine Learning
MLlib(Spark를 기반으로 빌드된 기계 학습 라이브러리) 작업에 노트북을 사용하여 기계 학습 애플리케이션을 만들 수 있습니다.
Spark 스트리밍 및 실시간 데이터 분석
HDInsight용 Spark 클러스터는 실시간 분석 솔루션을 빌드하기 위한 풍부한 지원을 제공합니다. Spark에는 이미 Kafka, Flume, X, ZeroMQ 또는 TCP 소켓 같은 여러 원본에서 데이터를 수집하기 위한 커넥터가 있지만, HDInsight의 Spark는 Azure Event Hubs에서 데이터 수집을 위한 최상의 지원을 추가합니다.
Jupyter Notebook 만들기
다음 단계를 사용하여 Azure Portal에서 Jupyter Notebook을 만듭니다.
포털의 클러스터 대시보드 섹션에서 Jupyter Notebook을 선택합니다. 메시지가 표시되면 클러스터에 대한 클러스터 로그인 자격 증명을 입력합니다.
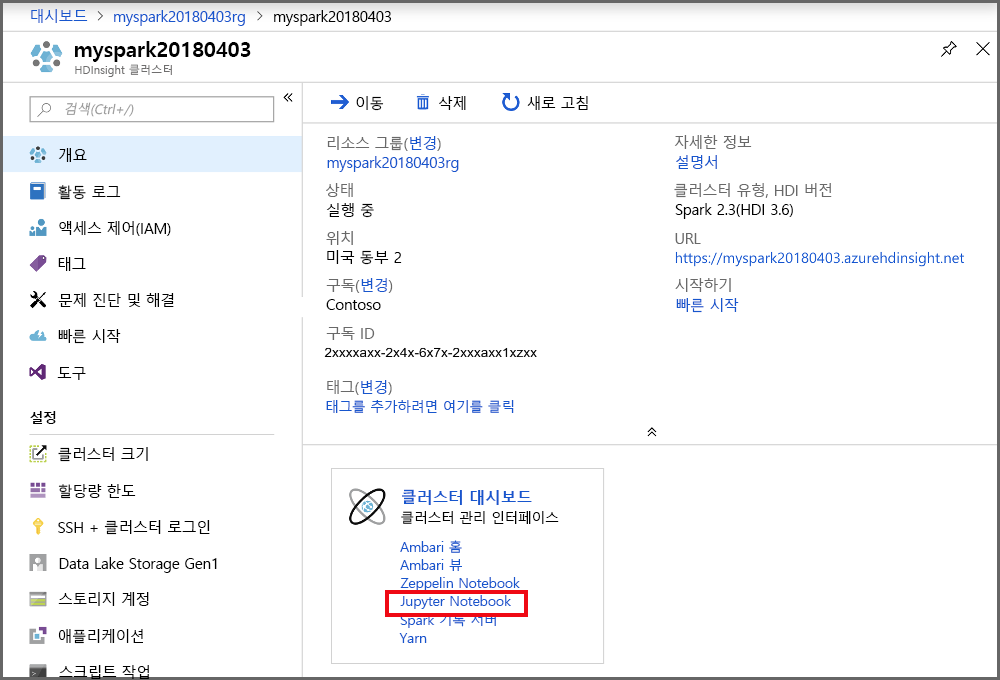
새로 만들기 > PySpark를 선택하여 Notebook을 만듭니다.
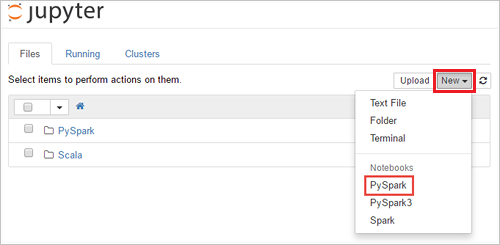
새 노트북이 만들어지고 쿼리 실행 작업을 만들기 시작할 수 있는 Untitled(Untitled.pynb)라는 이름으로 열립니다.