HDInsight 클러스터 만들기
HDInsight 클러스터를 만드는 방법은 간편한 사용자 인터페이스를 위해 Azure Portal을 사용하는 방법부터 자동화된 배포에 도움이 될 수 있는 스크립팅된 설정까지 다양합니다. 다음 표는 HDInsight 클러스터를 설정하기 위해 사용할 수 있는 다양한 방법을 보여 줍니다.
| 다음을 사용하여 만든 클러스터 | 웹 브라우저 | 명령줄 | REST API | SDK |
|---|---|---|---|---|
| Azure Portal | ✔ | |||
| Azure Data Factory | ✔ | ✔ | ✔ | ✔ |
| Azure CLI | ✔ | |||
| Azure PowerShell | ✔ | |||
| cURL | ✔ | ✔ | ||
| .NET SDK | ✔ | |||
| Azure Resource Manager 템플릿 | ✔ |
모든 HDInsight 설정에는 다음을 비롯한 기본 정보가 필요합니다.
기본 사항 탭
프로젝트 세부 정보
구독
HDInsight 요금이 청구되고 HDInsight를 관리할 Azure 구독을 정의합니다.
리소스 그룹 이름
리소스 그룹은 일반적으로 동일한 애플리케이션 또는 애플리케이션 수명 주기에 관련된 Azure 기술 및 서비스를 논리적으로 그룹화한 것입니다. 동일한 리소스 그룹의 서비스를 그룹화하면 관리 유지 관리가 쉬워집니다.
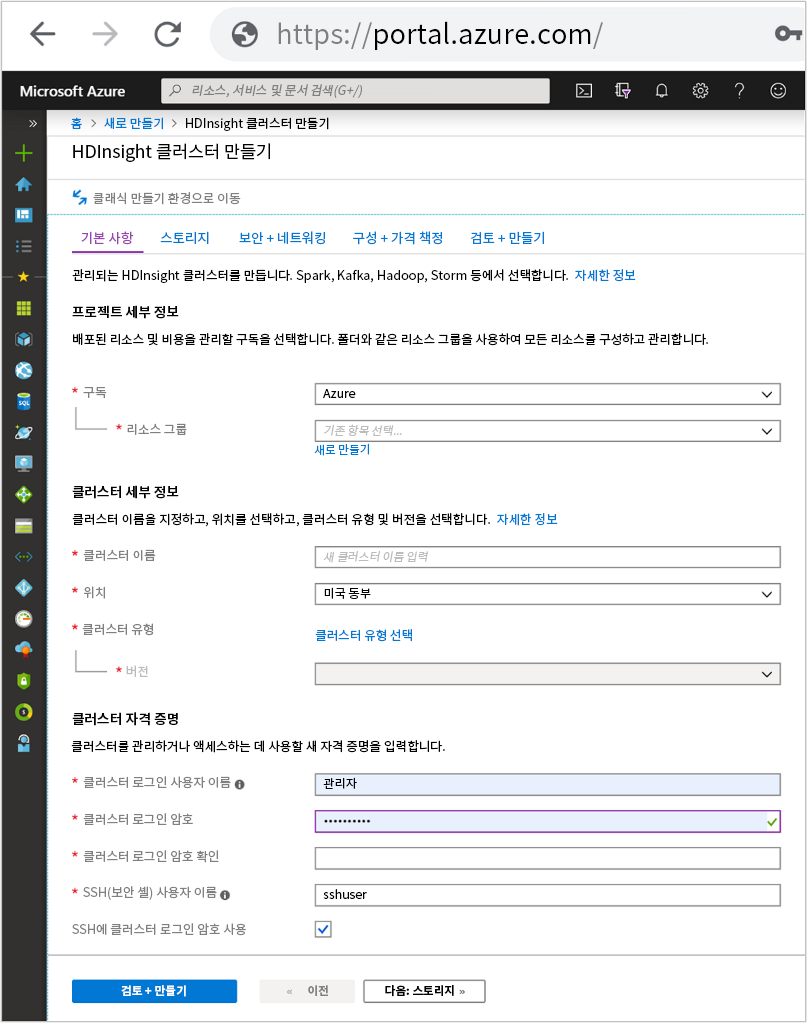
클러스터 세부 정보
클러스터 이름
HDInsight 클러스터 이름에는 다음 제한 사항이 있습니다.
- 허용되는 문자: a-z, 0-9, A-Z
- 최대 길이: 59
- 예약된 이름: apps
- 클러스터 명명 범위는 모든 구독에서 모든 Azure에 해당합니다. 따라서 클러스터 이름은 전 세계에서 고유해야 합니다.
- 처음 6자는 VNET 내에서 고유해야 합니다.
위치
클러스터 유형이 저장되는 위치를 지정합니다. 위치가 정의되지 않으면 클러스터는 기본 스토리지와 동일한 위치에 함께 배치됩니다. 이 위치는 대기 시간을 줄이기 위해 최대한 사용자와 가까워야 합니다.
클러스터 유형
리소스 클러스터에서 프로비저닝된 기술 스택을 정의합니다. 보유하고 있는 데이터 형식 및 시나리오에 필요한 종류 처리를 기준으로 클러스터 유형을 선택합니다. 사용 가능한 클러스터 유형은 다음 표에 나와 있습니다.
| 클러스터 유형 | 설명 |
|---|---|
| Apache Hadoop | HDFS 및 간단한 MapReduce 프로그래밍 모델을 사용하여 일괄 처리 데이터를 처리하고 분석하는 프레임워크입니다. |
| Apache Spark | 메모리 내 처리를 지원하여 빅 데이터 분석 애플리케이션의 성능을 향상하는 오픈 소스 병렬 처리 프레임워크입니다. |
| HBase는 | 비정형 및 반정형 대량 데이터(잠재적으로 수십억 개의 행과 수십억 개의 열로 구성됨)에 관해 임의 액세스 및 강력한 일관성을 제공하는 Hadoop 기반의 NoSQL 데이터베이스입니다. |
| Apache Interactive Query | 더 빠른 대화형 Hive 쿼리를 위한 메모리 내 캐싱입니다. |
| Apache Kafka | 스트리밍 데이터 파이프라인 및 애플리케이션을 빌드하는 데 사용되는 오픈 소스 플랫폼입니다. 또한 Kafka는 데이터 스트림을 게시하고 구독할 수 있는 메시지 큐 기능을 제공합니다. |
버전
이 클러스터에 대한 HDInsight 버전을 정의합니다. HDInsight 4.0은 최신 버전이며 클러스터에 프로비저닝된 가장 최근 프레임워크를 포함합니다.
클러스터 자격 증명
HDInsight 클러스터를 사용하면 클러스터 생성 중에 두 개의 사용자 계정을 구성할 수 있습니다.
클러스터 로그인 및 암호
기본 사용자 이름은 admin입니다. Azure Portal에서 기본 구성을 사용합니다. 경우에 따라 “클러스터 사용자”라고도 합니다.
SSH 사용자 이름 및 암호
SSH를 통해 클러스터에 연결하는 데 사용됩니다.
참고
엔터프라이즈 보안 패키지를 사용하면 Active Directory 및 Apache Ranger와 HDInsight를 통합할 수 있습니다. Enterprise Security Package를 사용하여 여러 사용자를 만들 수 있습니다.
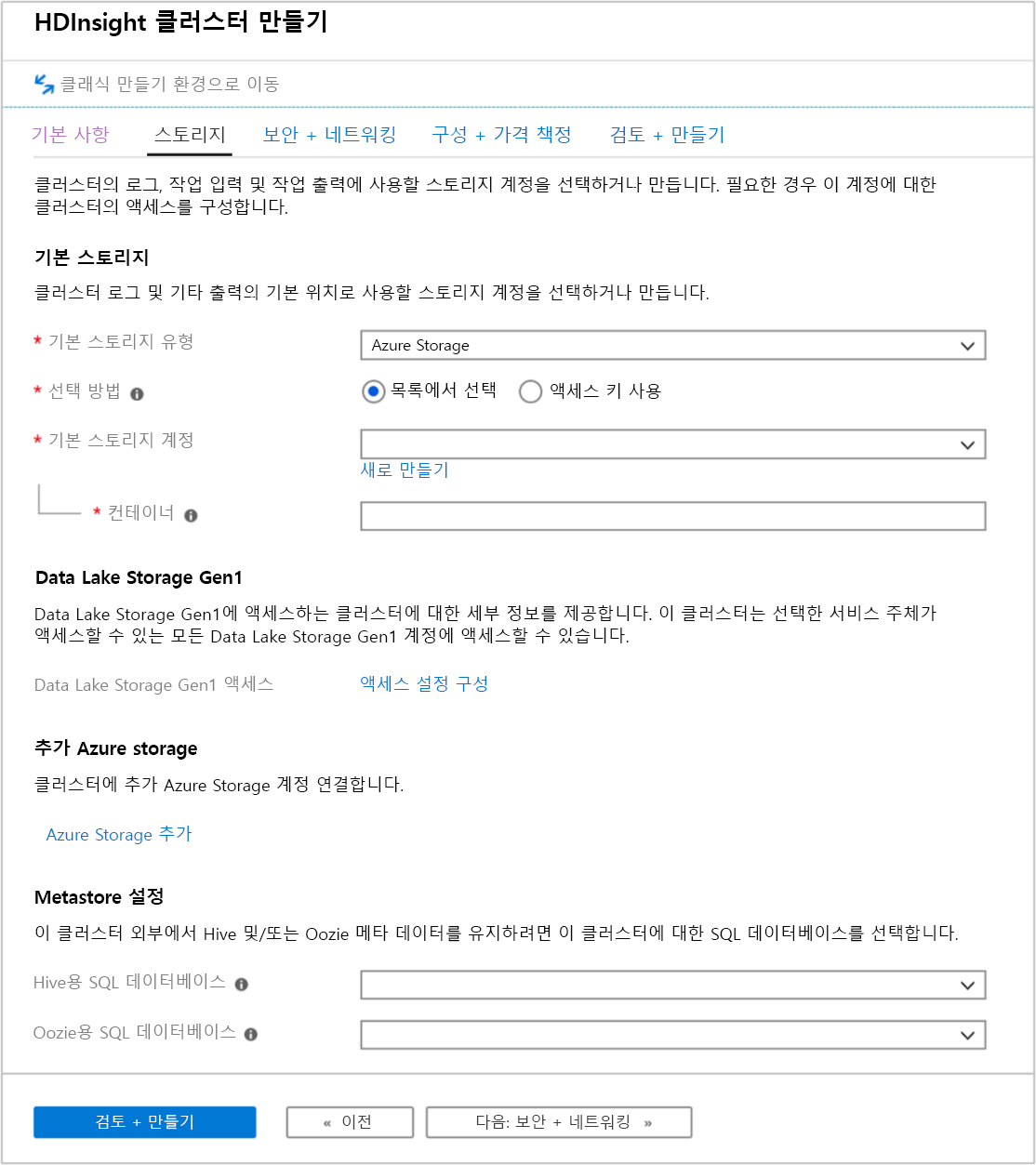
스토리지 탭
HDInsight 클러스터는 스토리지 화면에 표시된 대로 다음 스토리지 옵션을 사용할 수 있습니다.
- Azure Data Lake Storage Gen2
- Azure Data Lake Storage Gen1
- Azure Storage 범용 v2
- Azure Storage 범용 v1
- Azure Storage 블록 Blob(보조 스토리지로만 지원됨)
스토리지 화면에서는 기본 스토리지 계정 및 기본 컨테이너를 정의할 수 있습니다. 추가 Azure Storage를 클러스터에 연결할 수도 있습니다. Metastore 설정을 사용하면 클러스터가 삭제된 후 Hive 테이블을 저장할 외부 SQL 데이터베이스를 정의하고 외부 저장소에 메타데이터를 저장하여 Oozie 성능을 개선할 수 있습니다.
보안 및 네트워킹
Hadoop, Spark, HBase, Kafaka 및 Interactive Query 클러스터 유형의 경우 Enterprise Security Package를 사용하도록 선택할 수 있습니다. 이 패키지는 Apache Ranger를 사용하고 Microsoft Entra ID와 통합하여 보다 안전한 클러스터를 설정하는 옵션을 제공합니다.
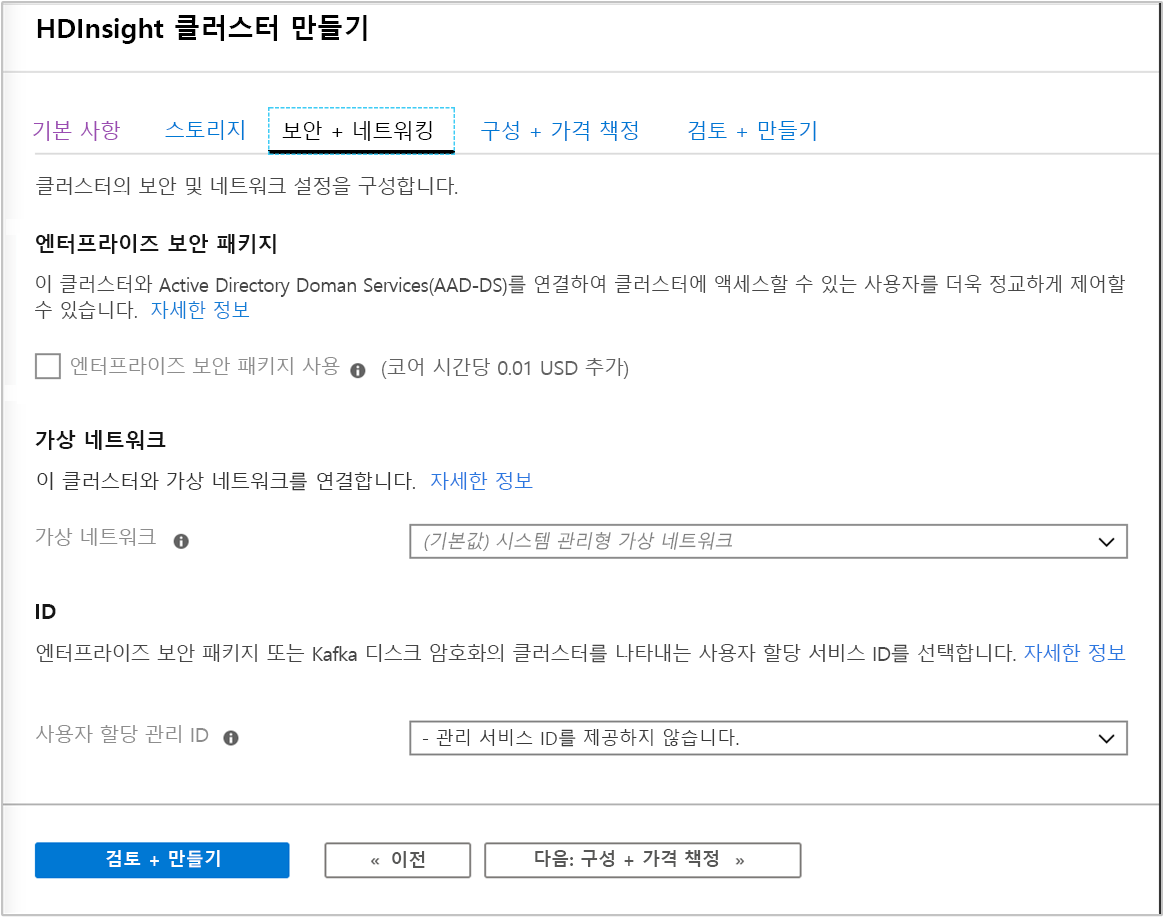
또한 VNet 내에 HDInsight 클러스터를 배포하는 것이 좋으며 이 화면에서 가상 네트워킹을 정의하고 설정할 수 있습니다. 사용자 솔루션에 여러 유형의 HDInsight 클러스터에 분산되어 있는 기술이 필요한 경우, Azure 가상 네트워크는 필요한 클러스터 유형을 연결할 수 있습니다. 이 구성은 클러스터를 허용하며, 배포하는 임의의 코드가 서로 직접 통신하도록 허용합니다.
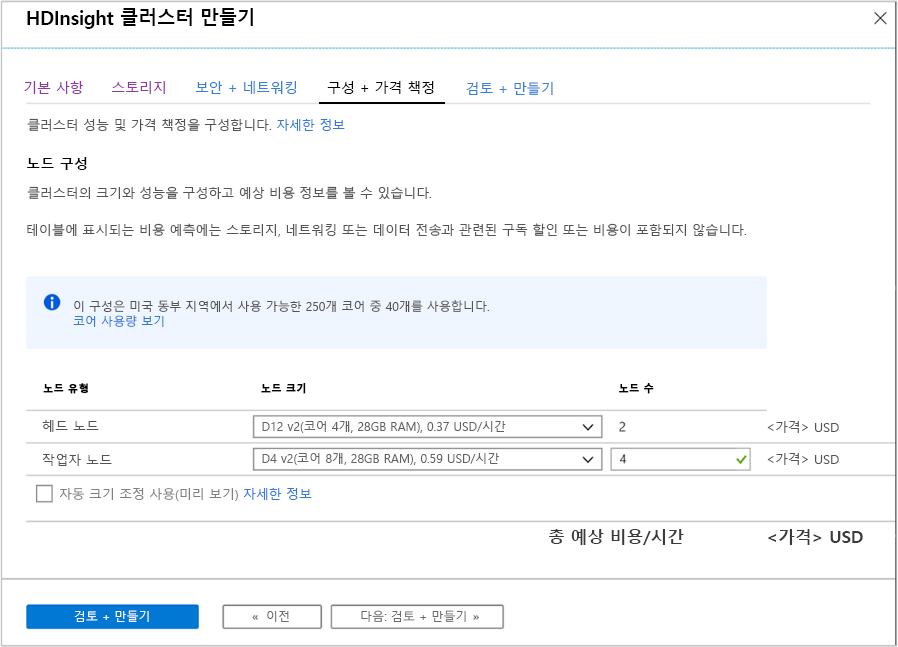
구성 및 가격 책정
이 페이지에서는 클러스터의 크기와 성능을 구성하고 예상 비용 정보를 볼 수 있습니다. 이 화면에서 헤드(마스터) 노드 및 작업자 노드에 사용될 가상 머신을 정의할 수 있습니다.