사용자 지정 텍스트 분류 기술
사용자 지정 텍스트 분류를 사용하면 텍스트의 구절을 다른 사용자 정의 클래스에 매핑할 수 있습니다. 예를 들어 책 뒷부분에 있는 개요에 대한 모델을 학습하여 책 장르를 자동으로 식별할 수 있습니다. 그런 다음, 식별된 장르를 사용하여 장르 패싯으로 온라인 상점 검색 엔진을 보강합니다.
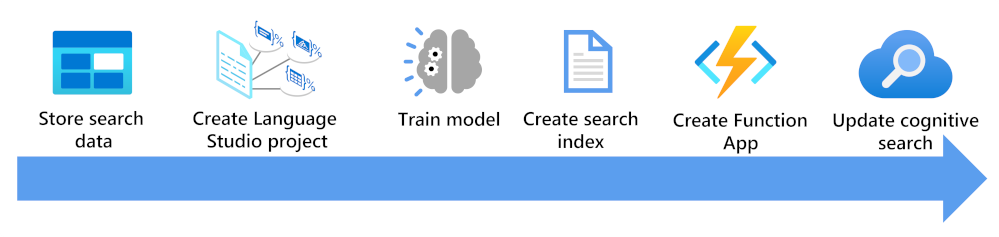
여기서는 사용자 지정 텍스트 분류 모델을 사용하여 검색 인덱스 보강을 위해 고려해야 할 사항을 확인할 수 있습니다.
- Language Studio 및 Azure AI 검색 인덱서에서 액세스할 수 있도록 문서를 저장합니다.
- 사용자 지정 텍스트 분류 프로젝트를 만듭니다.
- 모델을 학습하고 테스트합니다.
- 저장된 문서를 기반으로 검색 인덱스를 만듭니다.
- 배포된 학습 모델을 사용하는 함수 앱을 만듭니다.
- 검색 솔루션, 인덱스, 인덱서, 사용자 지정 기술 세트를 업데이트합니다.
데이터 저장
Azure Blob Storage는 Language Studio와 Azure AI 서비스 모두에서 액세스할 수 있습니다. 컨테이너에 액세스할 수 있어야 하므로 가장 간단한 옵션은 컨테이너를 선택하는 것이지만 몇 가지 추가 구성으로 프라이빗 컨테이너를 사용할 수도 있습니다.
데이터와 함께 각 문서에 대한 분류를 할당하는 방법도 필요합니다. Language Studio는 각 문서를 한 번에 하나씩 수동으로 분류하는 데 사용할 수 있는 그래픽 도구를 제공합니다.
두 가지 형식의 프로젝트 중에서 선택할 수 있습니다. 문서가 단일 클래스에 매핑되는 경우 단일 레이블 분류 프로젝트를 사용합니다. 하나의 문서를 두 개 이상의 클래스에 매핑하려면 다중 레이블 분류 프로젝트를 사용합니다.
각 문서를 수동으로 분류하고 싶지 않으면 Azure AI 언어 프로젝트를 만들기 전에 모든 문서에 레이블을 지정할 수 있습니다. 이 프로세스에는 다음 형식의 레이블 JSON 문서를 만드는 작업이 포함됩니다.
{
"projectFileVersion": "2022-05-01",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "CustomMultiLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project-description",
"language": "en-us"
},
"assets": {
"projectKind": "CustomMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
}
]
}
classes 배열에 있는 만큼 클래스를 추가합니다. 문서가 일치하는 클래스를 포함하여 documents 배열의 각 문서에 대한 항목을 추가합니다.
Azure AI 언어 프로젝트 만들기
Azure AI 언어 프로젝트를 만드는 방법에는 두 가지가 있습니다. Azure Portal의 언어 서비스를 먼저 만들지 않고 Language Studio를 사용하기 시작하면 Language Studio에서 언어 서비스를 만들 수 있습니다.
Azure AI 언어 프로젝트를 만드는 가장 유연한 방법은 먼저 Azure Portal을 사용하여 언어 서비스를 만드는 것입니다. 이 옵션을 선택하면 사용자 지정 기능을 추가하는 옵션이 제공됩니다.
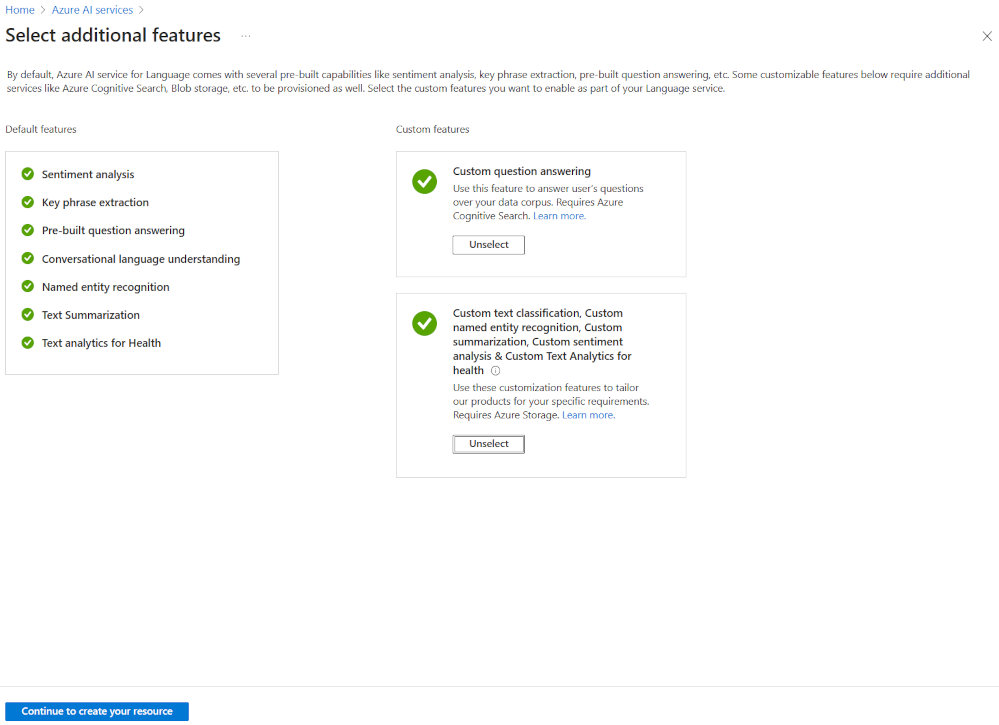
사용자 지정 텍스트 분류를 만들 예정이었기 때문에 언어 서비스를 만들 때 해당 사용자 지정 기능을 선택합니다. 또한 이 메서드를 사용하여 언어 서비스를 스토리지 계정에 연결합니다.
리소스가 배포되면 언어 서비스의 개요 창에서 Language Studio로 직접 이동할 수 있습니다. 그런 다음, 새 사용자 지정 텍스트 분류 프로젝트를 만들 수 있습니다.
참고 항목
Language Studio에서 언어 서비스를 만든 경우 다음 단계를 따라야 할 수도 있습니다. Azure 언어 리소스 및 스토리지 계정에 대한 역할을 설정하여 스토리지 컨테이너를 사용자 지정 텍스트 분류 프로젝트에 연결합니다.
분류 모델 학습
모든 AI 모델과 마찬가지로 학습에 사용할 수 있는 식별된 데이터가 있어야 합니다. 모델은 클래스에 데이터를 매핑하는 방법의 예제를 확인하고 모델을 테스트하는 데 사용할 수 있는 몇 가지 예제가 있어야 합니다. 모델이 학습 데이터를 자동으로 분할하도록 선택할 수 있습니다. 기본적으로 문서의 80%를 사용하여 모델을 학습시키고 20%를 블라인드 테스트합니다. 모델을 테스트하려는 특정 문서가 있는 경우 테스트를 위해 문서에 레이블을 지정할 수 있습니다.

Language Studio의 프로젝트에서 데이터 레이블 지정을 선택합니다. 모든 문서가 표시됩니다. 테스트 집합에 추가하려는 각 문서를 선택한 다음, 모델의 성능 테스트를 선택합니다. 업데이트된 레이블을 저장한 다음, 새 학습 작업을 만듭니다.
검색 인덱스 만들기
사용자 지정 텍스트 분류 모델에 의해 보강되는 검색 인덱스 만들기에 필요한 구체적인 작업은 없습니다. Azure AI 검색 솔루션 만들기의 단계를 따릅니다. 함수 앱을 만든 후 인덱스, 인덱서, 사용자 지정 기술을 업데이트합니다.
Azure 함수 앱 만들기
함수 앱에 원하는 언어와 기술을 선택할 수 있습니다. 앱은 사용자 지정 텍스트 분류 엔드포인트에 JSON을 전달할 수 있어야 합니다. 예를 들면 다음과 같습니다.
{
"displayName": "Extracting custom text classification",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en-us",
"text": "This film takes place during the events of Get Smart. Bruce and Lloyd have been testing out an invisibility cloak, but during a party, Maraguayan agent Isabelle steals it for El Presidente. Now, Bruce and Lloyd must find the cloak on their own because the only non-compromised agents, Agent 99 and Agent 86 are in Russia"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"project-name": "movie-classifier",
"deployment-name": "test-release"}
}
]
}
그런 다음, 모델에서 JSON 응답을 처리합니다. 예를 들면 다음과 같습니다.
{
"jobId": "be1419f3-61f8-481d-8235-36b7a9335bb7",
"lastUpdatedDateTime": "2022-06-13T16:24:27Z",
"createdDateTime": "2022-06-13T16:24:26Z",
"expirationDateTime": "2022-06-14T16:24:26Z",
"status": "succeeded",
"errors": [],
"displayName": "Extracting custom text classification",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomMultiLabelClassificationLROResults",
"taskName": "Multi Label Classification",
"lastUpdateDateTime": "2022-06-13T16:24:27.7912131Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "1",
"class": [
{
"category": "Action",
"confidenceScore": 0.99
},
{
"category": "Comedy",
"confidenceScore": 0.96
}
],
"warnings": []
}
],
"errors": [],
"projectName": "movie-classifier",
"deploymentName": "test-release"
}
}
]
}
}
그런 다음 이 함수는 구조화된 JSON 메시지를 AI 검색의 사용자 지정 기술 세트로 반환합니다. 예:
[{"category": "Action", "confidenceScore": 0.99}, {"category": "Comedy", "confidenceScore": 0.96}]
함수 앱에서 알아야 할 5가지 사항은 다음과 같습니다.
- 분류할 텍스트입니다.
- 학습된 사용자 지정 텍스트 분류 배포 모델의 엔드포인트입니다.
- 사용자 지정 텍스트 분류 프로젝트의 기본 키입니다.
- 프로젝트 이름입니다.
- 배포 이름입니다.
분류할 텍스트는 AI 검색의 사용자 지정 기술 세트에서 함수에 입력으로 전달됩니다. 나머지 4개 항목은 Language Studio에서 찾을 수 있습니다.

엔드포인트 및 배포 이름은 모델 배포 창에 있습니다.

프로젝트 이름 및 기본 키는 프로젝트 설정 창에 있습니다.
Azure AI 검색 솔루션 업데이트
검색 인덱스 보강을 위해 수행해야 하는 Azure Portal의 세 가지 변경 내용이 있습니다.
- 사용자 지정 텍스트 분류 보강을 저장하려면 인덱스에 필드를 추가해야 합니다.
- 분류할 텍스트를 사용하여 함수 앱을 호출하는 사용자 지정 기술 세트를 추가해야 합니다.
- 기술 세트의 응답을 인덱스로 매핑해야 합니다.
기존 인덱스에 필드 추가
Azure Portal에서 AI 검색 리소스로 이동하여 인덱스를 선택하고 다음 형식으로 JSON을 추가합니다.
{
"name": "classifiedtext",
"type": "Collection(Edm.ComplexType)",
"analyzer": null,
"synonymMaps": [],
"fields": [
{
"name": "category",
"type": "Edm.String",
"facetable": true,
"filterable": true,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "standard.lucene",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
},
{
"name": "confidenceScore",
"type": "Edm.Double",
"facetable": true,
"filterable": true,
"retrievable": true,
"sortable": false,
"analyzer": null,
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
]
}
이 JSON은 인덱스로 복합 필드를 추가하여 검색 가능한 category 필드에 클래스를 저장합니다. 두 번째 confidenceScore 필드는 신뢰도 백분율을 이중 필드에 저장합니다.
사용자 지정 기술 세트 편집
Azure Portal에서 기술 세트를 선택하고 다음 형식으로 JSON을 추가합니다.
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "Genre Classification",
"description": "Identify the genre of your movie from its summary",
"context": "/document",
"uri": "https://learn-acs-lang-serives.cognitiveservices.azure.com/language/analyze-text/jobs?api-version=2022-05-01",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "lang",
"source": "/document/language"
},
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "text",
"targetName": "class"
}
],
"httpHeaders": {}
}
이 WebApiSill 기술 정의는 문서의 언어와 내용이 함수 앱에 입력으로 전달되도록 지정합니다. 앱은 class라는 JSON 텍스트를 반환합니다.
함수 앱의 출력을 인덱스로 매핑
마지막 변경 내용은 출력을 인덱스로 매핑하는 것입니다. Azure Portal에서 인덱서를 선택하고 JSON을 편집하여 새 출력 매핑을 만듭니다.
{
"sourceFieldName": "/document/class",
"targetFieldName": "classifiedtext"
}
이제 인덱서는 함수 앱 document/class의 출력이 classifiedtext 필드에 저장되어야 한다는 것을 알고 있습니다. 이는 복합 필드로 정의되었으므로 함수 앱은 category 및 confidenceScore 필드를 포함하는 JSON 배열을 반환해야 합니다.
이제 보강된 검색 인덱스에서 사용자 지정 분류 텍스트를 검색할 수 있습니다.