지능형 쿼리 처리 설명
Microsoft는 SQL Server 2017 및 2019, Azure SQL에서 호환성 수준 140 및 150에 새로운 기능을 많이 도입했습니다. 해당 기능 중 대부분은 사용자 정의된 스칼라 값 함수를 사용하고 테이블 변수를 사용하는 것과 같이 이전 안티패턴을 수정합니다.
기능은 다음과 같은 몇 가지 기능 제품군으로 분류됩니다.
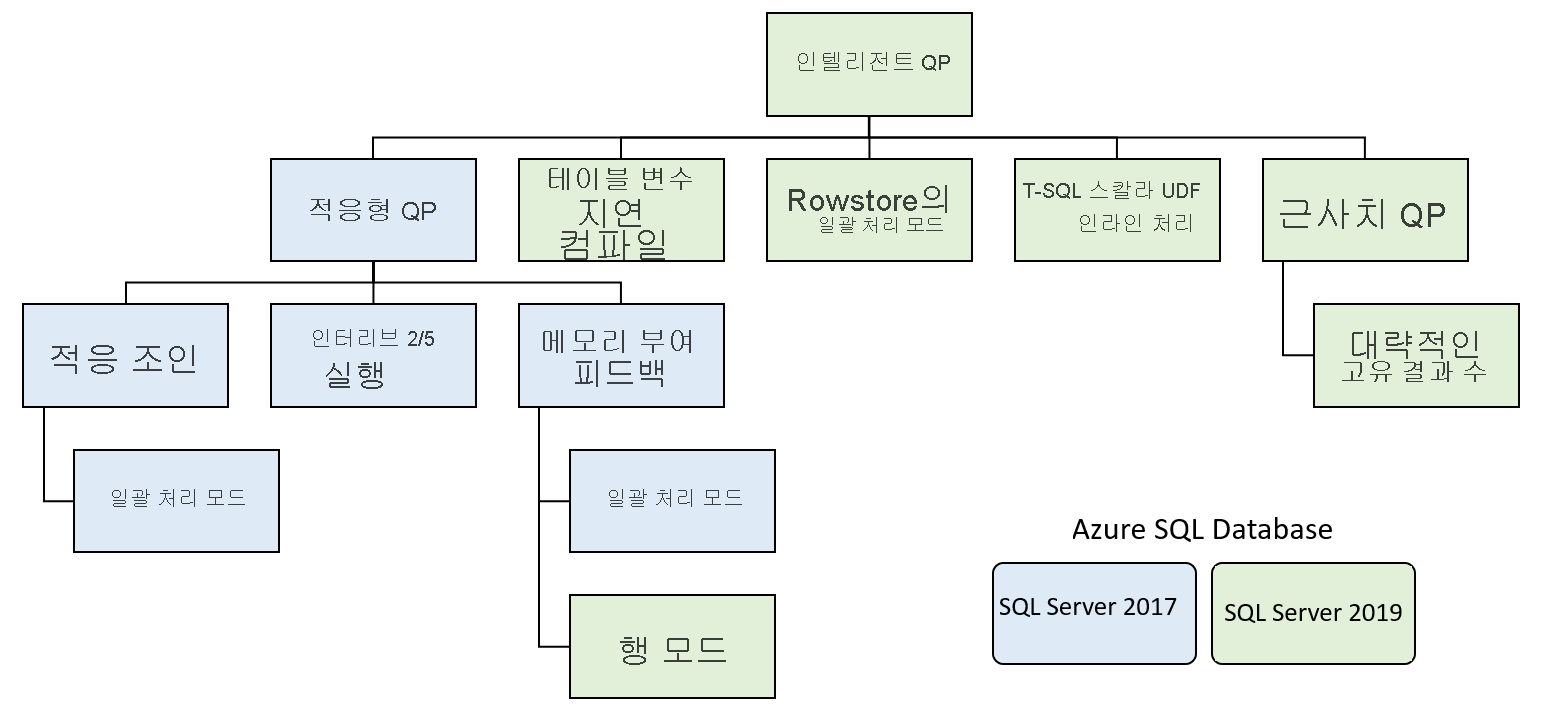
지능형 쿼리 처리에는 최소한의 구현 노력으로 기존 워크로드 성능을 향상시키는 기능이 포함됩니다.
워크로드가 지능형 쿼리 처리에 자동으로 적합하도록 하려면 해당 데이터베이스 호환성 수준을 150으로 변경합니다. 예를 들면 다음과 같습니다.
ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 150;
적응 쿼리 처리
적응 쿼리 처리에는 쿼리의 실행 컨텍스트를 토대로 쿼리를 보다 동적으로 처리하는 많은 옵션이 포함되어 있습니다. 옵션에는 쿼리 처리를 향상시키는 몇 가지 기능이 포함되어 있습니다.
적응 조인 - 데이터베이스 엔진은 조인하는 행 수에 따라 해시와 중첩 루프 사이의 조인 선택을 지연시킵니다. 적응 조인은 현재 일괄 처리 실행 모드에서만 작동합니다.
인터리브 실행 - 현재 이 기능은 MSTVF(다중 문 테이블 반환 함수)를 지원합니다. SQL Server 2017 이전에는 MSTVF에서 버전 SQL Server에 따라 하나 또는 100행의 고정 행 예상치를 사용했습니다. 이 예상치는 함수에서 더 많은 행을 반환한 경우 최적이 아닌 쿼리 계획으로 이어질 수 있었습니다. 인터리브된 실행을 사용하면 나머지 계획을 컴파일하기 전에 MSTVF에서 실제 행 수가 생성됩니다.
메모리 부여 피드백 - SQL Server는 통계의 행 개수 예상치에 따라 쿼리의 초기 계획에 메모리 부여를 생성합니다. 심각한 데이터 기울이기는 행 개수의 과도 또는 과소 예측으로 이어질 수 있기 때문에 동시성을 감소시키는 메모리를 과도하게 부여하거나 메모리를 과소하게 부여하여 쿼리가 데이터를 tempdb로 스필될 수 있습니다. 메모리 부여 피드백을 사용하여 SQL Server에서 해당 조건을 감지하고 스필 또는 초과 할당을 방지하기 위해 쿼리에 부여되는 메모리 양을 줄이거나 늘립니다.
해당 기능은 모두 호환성 모드 150에서 자동으로 활성화되며, 활성화하기 위해 달리 변경하지 않아도 됩니다.
테이블 변수 지연 컴파일
MSTVF와 마찬가지로, SQL Server 실행 계획의 테이블 변수는 하나의 행에 대해 고정된 행 수 예측치를 수행했습니다. MSTVF와 마찬가지로 해당 고정 예측치는 변수가 예상보다 훨씬 큰 행 개수를 가진 경우 성능이 저하되었습니다. SQL Server 2019를 사용하면 이제 테이블 변수가 분석되고 실제 행 수가 존재하게 됩니다. 지연된 컴파일은 그 특성상 실행 계획 내에서 동적으로 실행되는 것이 아니라 쿼리의 첫 번째 컴파일에서 실행되는 점을 제외하고는 MSTVF 인터리브 실행과 유사합니다.
행 저장소의 일괄 처리 모드
일괄 처리 실행 모드를 사용하면 데이터를 행 단위가 아닌 일괄 처리할 수 있습니다. 이 처리 모델은 계산 및 집계에 대해 상당한 CPU 비용이 발생하는 쿼리에서 큰 이점을 얻을 수 있습니다. 일괄 처리 및 columnstore 인덱스를 분리하면 더 많은 워크로드가 일괄 모드 처리의 이점을 얻을 수 있습니다.
스칼라 사용자 정의 함수 인라인 처리
이전 버전의 SQL Server에서 스칼라 함수는 몇 가지 이유로 제대로 수행되지 않았습니다. 스칼라 함수는 반복적으로 실행되어 사실상 한 번에 한 행씩 처리했습니다. 실행 계획에 적절한 비용 예측이 없었고 쿼리 계획의 병렬 처리를 허용하지 않았습니다. 사용자 정의 함수 인라인 처리를 사용하면 해당 함수가 실행 계획에서 사용자 정의 함수 연산자 대신 스칼라 하위 쿼리로 변환됩니다. 이 변환으로 인해 스칼라 함수 호출과 관련한 쿼리의 성능을 크게 향상시킬 수 있습니다.
대략적인 고유 결과 수
일반적인 데이터 웨어하우스 쿼리 패턴은 고유한 주문 또는 사용자 수를 실행하는 것입니다. 이 쿼리 패턴은 대형 테이블에 비해 비용이 많이 들 수 있습니다. 대략적인 고유 결과 수는 행을 그룹화하여 더 빠르게 고유 카운트를 수집합니다. 이 함수는 97% 신뢰도 간격으로 2% 오류 비율을 보장합니다.