연습 - Azure Data Factory 랭글링 데이터 사용
Azure Data Factory 내의 파워 쿼리 기능을 사용하면 데이터를 작업하고 랭글링할 수 있습니다. 코드 없는 데이터 준비를 수행하기 위해 캔버스 디자이너에 Azure Data Factory 파이프라인의 작업으로 추가할 수 있는 개체입니다. 이를 통해 Spark 또는 SQL Server 같은 기존 데이터 준비 기술과 Python 및 T-SQL 같은 언어에 익숙하지 않은 개인이 클라우드 규모의 데이터를 반복적으로 준비할 수 있습니다.
파워 쿼리 기능은 기본적인 데이터 준비에 시각적으로 Excel과 비슷한 그리드 유형 인터페이스를 사용하며 이 인터페이스는 온라인 매시업 편집기로 알려져 있습니다. 또한 편집기를 통해 고급 사용자는 수식을 사용하여 더 복잡한 데이터 준비를 수행할 수 있습니다. 먼저 데이터 원본에 연결된 서비스를 만들어야 데이터에 액세스할 수 있습니다.
수식은 파워 쿼리 온라인에서 작동하며 데이터 팩터리 사용자가 파워 쿼리 M 함수를 사용할 수 있도록 합니다. 파워 쿼리는 온라인 매시업 편집기에서 생성한 M 언어를 클라우드 규모 실행용 Spark 코드로 변환합니다.
이 기능을 통해 데이터 엔지니어와 데이터 분석가가 모두 대화형으로 데이터 세트를 탐색하고 준비할 수 있습니다. 또한 M 언어로 대화형으로 작업하고 더 넓은 파이프라인의 컨텍스트에서 확인하기 전에 먼저, 결과를 미리 볼 수 있습니다.
Azure Data Factory에서 파워 쿼리 활동을 추가하려면 더하기 아이콘을 클릭하고 팩터리 리소스 창에서 파워 쿼리를 선택합니다.

랭글링 데이터 흐름의 원본 데이터 세트를 추가하고 싱크 데이터 세트를 선택합니다. 다음 데이터 원본이 지원됩니다.
| 커넥터 | 데이터 형식 | 인증 유형 |
|---|---|---|
| Azure Blob Storage | CSV, Parquet | 계정 키 |
| Azure Data Lake Storage Gen1 | CSV | 서비스 주체 |
| Azure Data Lake Storage Gen2 | CSV, Parquet | 계정 키, 서비스 주체 |
| Azure SQL Database | SQL 인증 | |
| Azure Synapse Analytics | SQL 인증 |
원본을 선택한 후 생성를 클릭합니다.

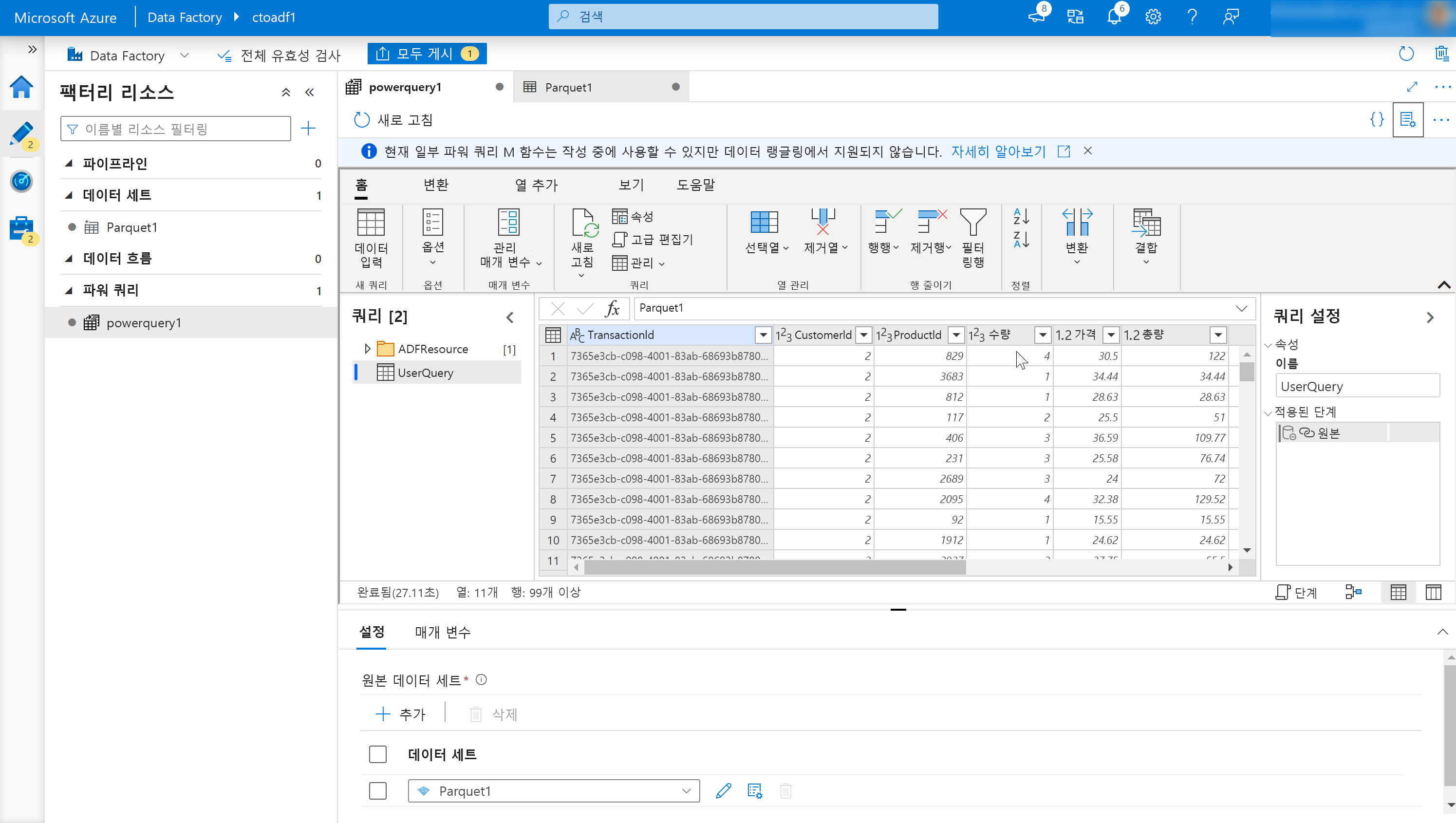
온라인 매시업 편집기가 열립니다.

다음 구성 요소로 구성됩니다.
데이터 세트 목록.
데이터 랭글링의 원본으로 정의된 데이터 세트를 제공합니다.
랭글링 함수 도구 모음.
도구 모음에는 다음을 비롯하여 사용자가 데이터를 조작하기 위해 액세스할 수 있는 다양한 데이터 랭글링 함수가 포함되어 있습니다.
- 열 관리.
- 테이블 변환.
- 행 축소.
- 열 추가
- 테이블 결합.
각 항목은 상황에 따라 달라지며 고유한 하위 함수를 포함합니다.
열 제목.
열 이름을 바꿀 수 있을 뿐만 아니라 열을 마우스 오른쪽 단추로 클릭하면 열 관리를 위한 상황에 맞는 항목이 표시됩니다.
설정.
이를 통해 데이터 원본 및 데이터 싱크를 추가하거나 편집하고 랭글링 데이터 작업에 대한 설정을 수정할 수 있습니다.
단계 창.
이 창에는 랭글링 출력에 적용된 단계가 표시됩니다. 그래픽 예에서는 “Source”라는 단계가 “UserQuery”라는 랭글링 출력에 적용되었습니다.
파워 쿼리가 출력 목록을 생성합니다.
정의된 데이터 랭글링 출력을 나열합니다.
게시 단추.
생성된 작업을 게시할 수 있습니다.
파워 쿼리 작업을 복사 작업 또는 매핑 데이터 흐름 작업과 마찬가지로 캔버스 디자이너에 추가하고 동일한 방식으로 관리 및 모니터링할 수 있습니다.
