클라우드에서 자동 크기 조정
클라우드 관리자가 수동으로 수요 감소를 수행할 수 있는 경우 증가된 수요를 처리하기 위해 규모를 확대 또는 확장하고 비용을 줄입니다. 예를 들어 주의 깊은 관리자는 수요가 증가하고 있음을 감지하고 클라우드 서비스 공급자가 제공하는 도구를 사용하여 추가 VM을 온라인으로 가져오거나(확장) 기존 VM을 더 많은 CPU 및 더 많은 메모리가 있는 더 큰 CPU로 교체(확대)할 수 있습니다. 핵심 단어는 "주의 깊은"입니다. 수요가 최고에 도달하지만 아무도 인지하지 못한 경우 최종 사용자에게는 시스템 전체의 응답 속도가 느려질 수 있습니다. 반대로, 과도한 부하를 처리하기 위해 확대하거나 확장하는 경우 부하가 감소하면 필요하지 않은 리소스에 대한 비용을 지불하게 됩니다.
그렇기 때문에 인기 있는 클라우드 플랫폼은 자동 크기 조정 메커니즘을 제공하여 사람의 개입 없이 변동하는 수요에 대응하여 리소스를 확장합니다. 자동 크기 조정에는 두 가지 기본 방법이 있습니다.
시간 기반 - 미리 정해진 일정에 따라 리소스의 크기를 조정합니다. 예를 들어 조직의 웹 사이트에 업무 시간 동안 가장 많은 부하가 발생하는 경우 매일 오전 8시에 리소스를 확대 또는 확장하고 매일 오후 5시에 축소 또는 감축하도록 자동 확장을 구성하는 식입니다. 시간 기반 크기 조정은 예약된 크기 조정이라고도 합니다.
메트릭 기반 - 부하를 예측하기 어려운 경우 CPU 사용률, 메모리 부족 또는 평균 요청 대기 시간과 같은 미리 정의된 메트릭을 기반으로 리소스를 확장합니다. 예를 들어 평균 CPU 사용률이 70%에 도달하면 자동으로 추가 VM을 온라인으로 가져오고 30%로 다시 줄어들면 추가 VM을 프로비저닝 해제합니다.
시간 또는 메트릭 항목이든 둘 다를 기준으로 확장하도록 선택하든 자동 크기 조정은 클라우드 관리자가 구성한 크기 조정 규칙 또는 크기 조정 정책을 사용합니다. 최신 클라우드 플랫폼은 매일 오전 8시에 2개의 인스턴스에서 4개의 인스턴스로 확장하고 오후 5시에 2개의 인스턴스로 되돌리는 것과 같은 단순한 규칙부터 복잡한 규칙에 이르는 다양한 크기 조정 규칙을 지원합니다. 예를 들어 최대 CPU 사용률이 70%를 초과하거나 평균 요청 대기 시간이 5초에 도달하면 VM 수를 하나씩 늘립니다. 올바른 규칙 조합을 찾으려면 일반적으로 클라우드 관리자 측에서 약간의 실험이 필요합니다.
Amazon, Microsoft 및 Google을 비롯한 모든 주요 클라우드 서비스 공급자는 자동 크기 조정을 지원합니다. AWS 자동 크기 조정은 EC2 인스턴스, DynamoDB 테이블 및 선택한 기타 AWS 클라우드 서비스에 적용될 수 있습니다. Azure는 App Service 및 Virtual Machines를 비롯한 주요 서비스에 자동 크기 조정 옵션을 제공합니다. Google의 경우 Google Compute Engine과 Google App Engine에 동일하게 제공합니다.
일반적으로 자동 크기 조정 서비스는 확대 및 축소가 아닌 감축 및 확장이 가능합니다. 부분적으로 확대 및 축소는 한 인스턴스를 다른 인스턴스로 교체해야 하며, 새 인스턴스가 생성되고 온라인으로 가져올 때 필연적으로 가동 중지 시간이 발생하기 때문입니다.
시간 기반 자동 크기 조정
시간 기반 자동 크기 조정은 부하를 예측 가능한 방식으로 변동하는 경우에 적합합니다. 예를 들어 많은 조직의 IT 시스템에서 업무 시간 중에 가장 높은 부하가 발생하고 새벽 시간에는 부하가 거의 발생하지 않을 수 있습니다. Domino 피자는 거의 100개 국가/지역에서 16,000개가 넘는 매장을 운영하므로 해당 웹 사이트는 항상 부하가 발생할 수 있습니다. 그러나 특정 기간 동안에는 평소보다 높은 예측이 가능합니다.
두 시나리오 모두 시간 기반 자동 크기 조정을 위한 후보입니다. 그림 7은 예약된 자동 크기 조정이 Azure에서 적용되는 방법을 보여 줍니다. 이 예제에서 클라우드 관리자는 조직 웹 사이트를 호스트하는 Azure App Service를 구성하여 기본적으로 2개의 인스턴스를 실행하고 일요일을 제외한 날에는 오전 6시부터 오후 6시 사이에 인스턴스 4개로 확대합니다. 관리자는 "시작/종료 날짜 지정" 옵션을 선택하여 슈퍼볼 경기가 있는 일요일에 10개의 인스턴스로 확장하도록 App Service를 쉽게 구성할 수 있습니다. 또한 다른 날짜에 확장하기 위해 여러 크기 조정 조건을 정의할 수 있습니다.
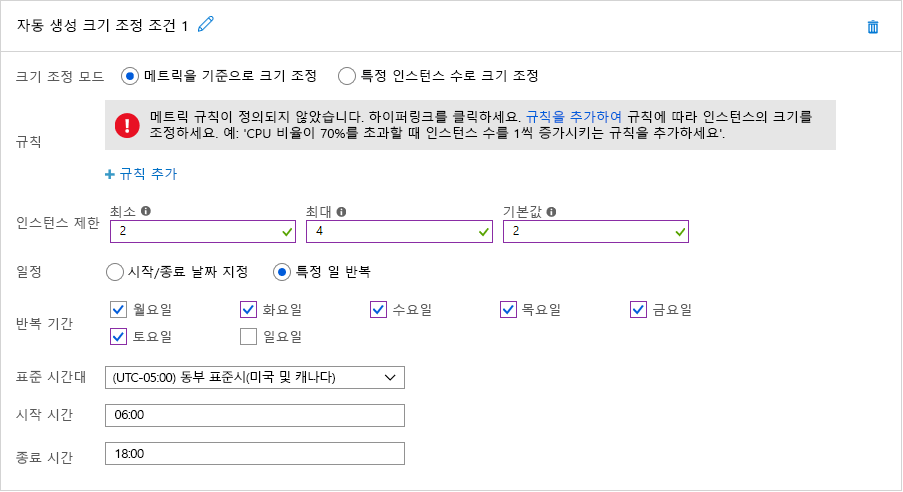
그림 7: Azure에 예약된 자동 크기 조정입니다.
메트릭 기반 자동 크기 조정
부하를 예측할 수 없는 경우 CPU 사용률 및 평균 요청 대기 시간과 같은 메트릭을 기반으로 크기를 조정하는 것이 적절합니다. 모니터링은 성능 메트릭에 따라 리소스를 효과적으로 자동 크기 조정을 수행하는 데 중요한 요소입니다. 자동 크기 조정기가 크기 조정 시기를 알 수 있기 때문입니다. 모니터링을 통해 트래픽 패턴 또는 리소스 사용률을 분석하여 비용을 최소화하면서 서비스 품질을 최대화하기 위해 리소스를 언제, 얼마나 크기 조정해야 하는지에 대한 교육 평가를 수행할 수 있습니다.
리소스의 크기 조정을 트리거하기 위해 모니터링되는 리소스의 몇 가지 측면이 있습니다. 가장 일반적인 메트릭은 리소스 사용률입니다. 예를 들어 모니터링 서비스는 각 리소스 노드의 CPU 사용률을 추적하고 사용량이 지나치게 많거나 적은 경우 리소스를 확장할 수 있습니다. 각 리소스에 대한 사용량이 90%보다 높으면 시스템이 과부하 상태가 되기 때문에 더 많은 리소스를 추가하는 것이 좋습니다. 일반적으로 서비스 공급자는 리소스 노드의 중단점과 장애가 발생하기 시작하는 시점을 분석하고, 다양한 부하 수준에서 동작을 매핑하여 해당 트리거 지점을 결정합니다. 비용상의 이유로 각 리소스를 최대한 활용하는 것이 중요하지만 운영 체제가 오버헤드 활동을 할 수 있도록 약간의 여유 공간을 두는 것이 좋습니다. 마찬가지로 사용률이 30% 미만이면 모든 리소스 노드가 필요한 것은 아니며 일부는 프로비저닝되지 않을 수 있습니다.
실제로 서비스 공급자는 일반적으로 리소스를 크기 조정할 시기를 평가하기 위해 여러 가지의 리소스 노드 메트릭 조합을 모니터링합니다. 여기에는 CPU 사용률, 메모리 사용량, 처리량 및 대기 시간이 포함됩니다. AWS는 CloudWatch를 사용하여 EC2 리소스를 모니터링하고 크기 조정 메트릭을 제공합니다(그림 8). CloudWatch는 크기 조정 그룹의 모든 EC2 인스턴스에 대한 메트릭을 추적하고 지정된 메트릭이 임계값을 초과하는 경우(예: CPU 사용률이 70%를 초과하는 경우) 경보를 표시합니다. 그런 다음 AWS는 관리자가 구성한 크기 조정 정책을 기반으로 EC2 인스턴스 수를 늘리거나 줄입니다.
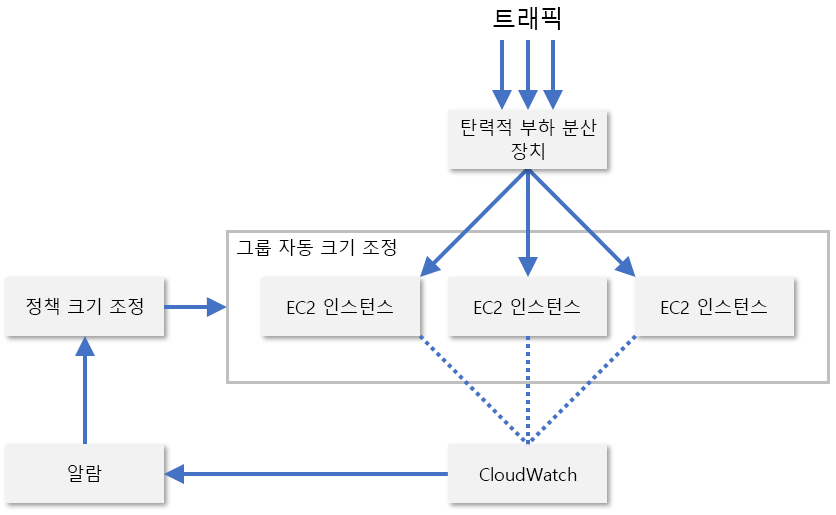
그림 8: AWS의 EC2 인스턴스 자동 크기 조정입니다.
AWS는 기계 학습을 사용하여 트래픽 패턴을 예상하고 그에 따라 인스턴스 수를 관리하는 예측 크기 조정도 지원합니다. 목표는 클라우드 관리자가 자동 크기 조정 규칙을 구성할 필요 없이 클라우드 리소스를 지능적으로 크기 조정하는 것입니다. 주요 클라우드 서비스 공급자는 기계 학습을 사용하여 플랫폼을 개선할 새로운 방법을 지속적으로 찾고 있습니다. 예를 들어 Microsoft는 이제 기계 학습을 사용하여 VM 오류를 사전에 예측하고 완화함으로써 Azure Virtual Machines의 복원력을 개선합니다.1
참고 자료
- Microsoft (2018). Improving Azure Virtual Machine resiliency with predictive ML and live migration. https://azure.microsoft.com/blog/improving-azure-virtual-machine-resiliency-with-predictive-ml-and-live-migration/.