말단 대기 시간을 처리하는 방법
대기 시간을 줄이기 위해 클라우드에서 사용되는 여러 최적화 기술을 이미 설명했습니다. 그 중에는 리소스를 수평 또는 수직 방향으로 확장하고 부하 분산 장치를 사용하여 요청을 가장 가까운 사용 가능 리소스로 라우팅하는 방법이 포함됩니다. 이 페이지에서는 대규모 데이터 센터 또는 클라우드 애플리케이션에서 일반적인 사례에만 최적화하지 말고 모든 요청의 대기 시간을 최소화하는 것이 중요한 이유를 자세히 다룹니다. 몇 개 안 되지만 대기 시간이 긴 이상값 때문에 대규모 시스템의 성능이 대폭 저하될 수 있다는 것도 살펴보겠습니다. 또한 이 페이지에서는 개별 구성 요소에서 보장하지 않더라도 예측 가능한 짧은 대기 시간 응답을 제공하는 서비스를 만드는 다양한 방법을 설명합니다. 이는 상호 작용에 원하는 대기 시간이 100밀리초 미만인 대화형 애플리케이션에서 특히 중요한 문제입니다.
말단 대기 시간(tail latency)이란 무엇일까요?
대부분의 클라우드 애플리케이션은 대규모 분산 시스템으로, 대기 시간을 줄이기 위해 병렬 처리를 자주 사용합니다. 일반적인 방법은 루트 노드(예: 프런트 엔드 웹 서버)에서 수신된 요청을 여러 리프 노드(백 엔드 컴퓨팅 서버)로 팬 아웃하는 것입니다. 분산 컴퓨팅이 병렬 처리되고 막대한 비용이 드는 데이터 이동을 피할 수 있다는 측면에서 성능 향상이 이루어집니다. 여기서는 간단하게 데이터가 저장되는 위치로 컴퓨팅을 이동합니다. 물론 각 리프 노드는 수백 또는 수천 개의 병렬 요청에 대해 동시에 작동합니다.
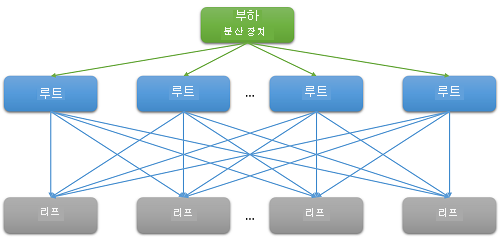
그림 7: 스케일 아웃으로 인한 대기 시간
Netflix에서 영화를 검색하는 경우를 예로 들겠습니다. 사용자가 검색 상자에 입력하기 시작하면 루트 웹 서버에서 여러 병렬 이벤트가 생성됩니다. 적어도 이러한 이벤트는 다음 요청을 포함합니다.
- 자동 완성 엔진 - 과거의 추세와 사용자 프로필을 기반으로 수행되는 검색을 실제로 예측합니다.
- 수정 엔진 - 지속적인 적응형 언어 모델을 기반으로 입력된 쿼리의 오류를 찾아냅니다.
- 다중 단어 쿼리를 구성하는 각 단어의 개별 검색 결과 - 영화의 순위와 관련성을 기반으로 결합되어야 합니다.
- 사용자의 "안전 검색" 기본 설정을 충족하기 위한 결과의 추가 사후 처리 및 필터링.
이러한 사례가 정말 많습니다. Facebook 요청 하나가 수천 개의 memcached 서버에 접촉하는 반면, Bing 검색 하나는 종종 만 개가 넘는 인덱스 서버를 통해 접촉하는 것으로 알려져 있습니다.
확장이 필요하기 때문에 프런트 엔드가 처리하는 각 개별 요청의 백 엔드에서 대규모 팬 아웃을 사용한 것이 분명합니다. 추론에 따르면 사용자 기반을 유지할 수 있도록 "응답"해야 하는 서비스는 100밀리초 내에 응답해야 합니다. 쿼리를 해결하는 데 필요한 서버 수가 늘어나면 리프 노드에서 루트 노드까지 걸리는 시간이 가장 긴 응답에 따라 전체 시간이 좌우되는 경우가 많습니다. 결과가 반환되려면 모든 리프 노드가 실행을 완료해야 한다는 전제 하에서, 전체 대기 시간은 가장 느린 단일 구성 요소의 대기 시간보다 길 수밖에 없습니다.
대부분의 추계 프로세스와 마찬가지로, 단일 리프 노드의 응답 시간을 분포로 표현할 수 있습니다. 수십 년의 경험에 비추어 볼 때, 일반적으로 잘 구성된 클라우드 시스템의 요청은 대부분(>99%) 매우 신속하게 실행됩니다. 하지만 시스템에서 매우 느리게 실행되는 이상값이 극소수 있는 경우가 종종 있습니다.
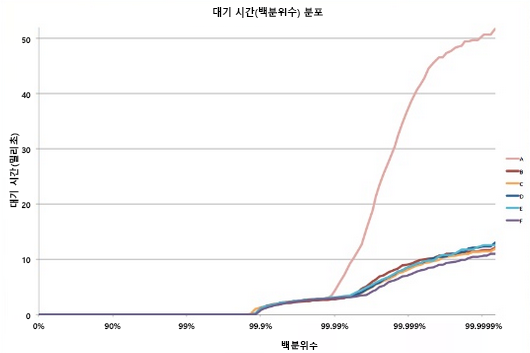
그림 8: 마지막 대기 시간 예시5
모든 리프 노드의 평균 응답 시간은 1밀리초이지만, 응답 시간이 1,000밀리초(1초)를 초과할 가능성이 1%인 시스템이 있다고 가정해 봅시다. 각 쿼리를 한 리프 노드에서만 처리한다면 쿼리가 1초 넘게 걸릴 확률도 1%입니다. 그러나 노드 수를 100개로 늘리면 쿼리가 1초 안에 완료될 확률이 36.6%로 낮아집니다. 즉, 쿼리 지속 시간이 대기 시간 분포의 말단(최하위 1%)에 의해 결정될 확률이 63.4%입니다.
$(.99^{100})$
다양한 사례에서 똑같이 시뮬레이션해 보면 서버 수가 늘어날수록 느린 쿼리 하나의 영향이 두드러지게 나타납니다(아래는 단조 증가하는 그래프). 또한 이러한 이상값의 확률이 1%에서 0.01%로 감소하면 시스템 안정성이 대폭 향상됩니다.
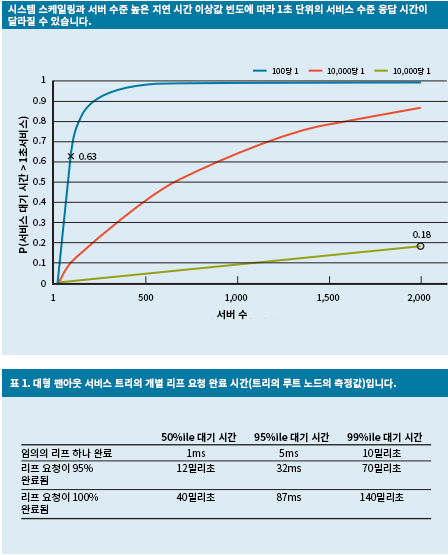
그림 9: 요청 대기 시간에 대한 50, 95, 99번째 백분율을 보여 주는 응답 시간 확률에 대한 최근 연구4
리소스 안정성 문제를 해결하기 위해 내결함성을 갖도록 애플리케이션을 설계했듯이, 이제는 애플리케이션의 "말단에 대한 내성(tail tolerant)"도 중요합니다. 말단에 대한 내성을 구현하려면 이처럼 장기적인 성능 가변성이 나타나는 원인을 이해하고, 완화 가능하면 완화 방법을, 완화 불가능하면 다른 해결 방법을 찾아야 합니다.
클라우드의 가변성: 원인 및 완화
말단 대기 시간 문제로 이어지는 응답 시간 가변성을 해결하려면 성능 변동의 원인을 파악해야 합니다.1
- 공유 리소스 사용: 여러 VM(그리고 해당 VM 내의 애플리케이션)이 공유 컴퓨팅 리소스 풀을 두고 경합합니다. 아주 드물게 이러한 경합으로 인해 일부 요청의 대기 시간이 짧아질 수 있습니다. 중요한 작업인 경우 전용 인스턴스를 사용하고 유휴 상태일 때 정기적으로 벤치마크를 실행하여 정상적으로 작동하는지 확인하는 하는 것도 좋습니다.
- 백그라운드 디먼 및 유지 관리: 백그라운드 프로세스에서 검사점을 만들고, 백업을 만들고, 로그를 업데이트하고, 가비지를 수집하고, 리소스 정리를 처리해야 한다고 이전에 이미 언급했습니다. 그러나 이로 인해 실행하는 동안 시스템의 성능이 저하될 수 있습니다. 이를 완화하려면 유지 관리 스레드로 인한 중단을 동기화하여 트래픽 흐름에 미치는 영향을 최소화해야 합니다. 이렇게 하면 모든 변형이 애플리케이션의 수명 동안 무작위로 발생하는 것이 아니라 잘 알려진 짧은 기간에 발생합니다.
- 큐: 가변성의 또 다른 근본 원인은 간헐적으로 발생하는 트래픽 도착 패턴입니다.1 OS에서 FIFO가 아닌 다른 예약 알고리즘을 사용하는 경우 이 가변성이 심해집니다. Linux 시스템은 전체 처리량을 최적화하고 서버 사용률을 최대화하기 위해 종종 순서를 벗어나서 스레드를 예약합니다. 연구 결과에 따르면, OS에서 FIFO 예약을 사용하면 시스템의 전체 처리량이 줄어드는 대신 말단 대기 시간이 감소합니다.
- 올투올(All-to-All) 인캐스트: 위의 그림 8에 표시된 패턴을 올투올(All-to-All) 통신이라고 합니다. 대부분의 네트워크 통신이 TCP를 통해 수행되므로 프런트 엔드 웹 서버와 모든 백 엔드 처리 노드 간에 수천 개의 동시 요청 및 응답이 발생합니다. 이는 통신이 폭증하는 패턴으로 종종 TCP 인캐스트 붕괴라고 하는 특수한 종류의 정체로 이어집니다.1, 2 수천 대의 서버에서 보내는 응답이 급증하면 여러 패킷이 삭제되거나 재전송되고, 결국 매우 작은 데이터 패킷에서 네트워크 트래픽 폭증이 발생합니다. 대규모 데이터 센터와 클라우드 애플리케이션은 종종 사용자 지정 네트워크 드라이버를 사용하여 TCP 수신 시간과 재전송 타이머를 동적으로 조정해야 합니다. 특정 속도를 초과하는 트래픽을 삭제하여 보내는 파일의 크기를 줄이도록 라우터를 구성할 수도 있습니다.
- 전원 및 온도 관리: 마지막으로, 가변성은 유휴 상태 또는 CPU 주파수 다운 스케일링 같은 기타 비용 절감 기술 사용으로 인한 부작용입니다. 프로세서가 유휴 상태에서 스케일 업하는데 적지 않은 시간을 소비하는 경우가 종종 있습니다. 이러한 비용 최적화 기능을 끄면 에너지 사용량과 비용이 증가하지만 가변성은 감소합니다. 가격 책정 모델에서 고객 리소스의 내부 사용률 메트릭을 거의 고려하지 않는 퍼블릭 클라우드에서는 이것이 그리 큰 문제가 되지 않습니다.
일부 실험 결과에 따르면, 이러한 시스템의 가변성은 퍼블릭 클라우드에서 훨씬 심각한데,3 이는 대부분 중요한 리소스와 공유 프로세서의 성능이 불완전하게 격리되기 때문입니다. 이러한 현상은 대기 시간이 중요한 여러 작업이 CPU를 많이 사용하는 작업과 동일한 물리적 노드에서 실행될 때 더욱 악화됩니다.
가변성 감수: 엔지니어링 솔루션
위에서 살펴본 가변성의 원인 중 상당수는 완벽한 솔루션이 없습니다. 따라서 대기 시간 말단을 늘리는 모든 소스를 해결하려고 시도하는 대신, 말단에 대한 내성을 갖도록 클라우드 애플리케이션을 디자인해야 합니다. 이는 가능성 있는 모든 오류를 해결할 수 없기 때문에 내결함성을 갖도록 애플리케이션을 디자인하는 방법과 비슷합니다. 다음은 이러한 가변성을 처리하는 일반적인 방법입니다.
- "충분히 좋은 결과": 종종 시스템이 수천 개의 노드에서 결과를 수신 대기할 때 단일 결과의 중요도가 매우 낮은 것으로 간주될 수 있습니다. 따라서 많은 애플리케이션에서는 간단하게 짧은 특정 대기 시간 내에 도착하는 결과로 사용자에게 응답하고 나머지는 삭제하도록 선택할 수 있습니다.
- 카나리아: 희귀한 코드 경로에 자주 사용되는 또 다른 대안은 작은 리프 노드의 하위 집합에서 요청을 테스트하여 전체 시스템에 영향을 줄 수 있는 크래시 또는 실패가 발생하는지 테스트하는 것입니다. 완전한 팬아웃 쿼리는 카나리아로 인해 오류가 발생하지 않는 경우에만 생성됩니다. 이것은 사람이 안전하게 작업할 수 있는지 테스트하기 위해 카나리아(새)를 석탄 광산에 보내는 것과 유사합니다.
- 대기 시간에 발생한 테스트 기간 및 상태 검사: 물론, 시스템에 대한 대량의 요청을 통해 카나리아를 사용하여 시스템을 테스트하는 것은 매우 일반적인 방법입니다. 리프 노드 중 하나의 성능이 저하되면 이러한 요청은 긴 말단을 만들 가능성이 높아집니다. 이에 대응하려면 시스템에서 각 리프 노드의 상태와 대기 시간을 주기적으로 모니터링해야 하며, 성능 저하를 보이는(유지 관리 또는 오류로 인해) 노드에 요청을 라우팅하면 안 됩니다.
- 차등 QoS: 대화형 요청에 대해 별도의 서비스 클래스를 만들어 큐에서 우선 순위를 지정할 수 있습니다. 대기 시간이 중요하지 않은 애플리케이션은 작업의 대기 시간을 더 길게 허용할 수 있습니다.
- 헤지 요청: 동일한 요청을 여러 복제본으로 전달한 후 먼저 도착하는 응답을 사용하여 가변성의 영향을 줄이는 간단한 솔루션입니다. 물론, 이로 인해 필요한 리소스 양이 두 배 또는 세 배로 늘어날 수도 있습니다. 헤지 요청 수를 줄이기 위해 첫 번째 응답이 해당 요청에 대해 예상되는 대기 시간의 95번째 백분위수보다 긴 경우에만 두 번째 요청을 전송할 수 있습니다. 이로 인해 늘어나는 추가 부하는 약 5%에 불과하지만 대기 시간 말단을 크게 줄일 수 있습니다. 그림 9를 보면 일반적으로 95번째 백분위수 대기 시간이 99번째 백분위수 대기 시간보다 훨씬 짧습니다.
- 추론 실행 및 선택적 복제: 부하가 많이 걸린 노드의 태스크를 사용률이 낮은 다른 리프 노드에서 추론적으로 시작할 수 있습니다. 이 방법은 특정 노드에서 오류가 발생하면 해당 노드가 과부하에 걸릴 수 있는 경우에 특히 효과적입니다.
- UX 기반 솔루션: 마지막으로, 사람이 느끼는 지연을 줄이도록 잘 설계된 사용자 인터페이스를 통해 지능적으로 대기 시간을 숨길 수 있습니다. 이렇게 하는 기술 중 하나는 애니메이션을 사용하여 초기 결과를 보여주거나, 또는 관련 메시지를 보내서 사용자와 접촉하는 것입니다.
이러한 기술을 사용하여 클라우드 애플리케이션의 최종 사용자 환경을 크게 개선하여 긴 말단의 고질적인 문제를 해결할 수 있습니다.
참조
- Li, J., Sharma, N. K., Ports, D. R., Gribble, S. D. 공저 (2014년). Tales of the Tail: Hardware, OS, and Application-Level Sources of Tail Latency from the Proceedings of the ACM Symposium on Cloud Computing, ACM
- Wu, Haitao and Feng, Zhenqian and Guo, Chuanxiong and Zhang, Yongguang (2013). ICTCP: Incast Congestion Control for TCP in Data-Center Networks, IEEE/ACM Transactions on Networking (TON), IEEE Press
- Xu, Yunjing and Musgrave, Zachary and Noble, Brian and Bailey, Michael (2013). Bobtail: Avoiding Long Tails in the Cloud, 10th USENIX Conference on Networked Systems Design and Implementation, USENIX Association
- Dean, Jeffrey and Barroso, Luiz André (2013). The tail at scale, Communications of the ACM, ACM
- Tene, Gil (2014). [Understanding Latency - Some Key Lessons and Tools](https://www.infoq.com/presentations/latency-lessons-tools/, QCon London