연습: 쿼리를 사용하여 추세 탐색
생소한 기상 데이터 세트의 원시 데이터 및 범위를 살펴보았습니다. 이 단원에서는 시각화를 사용하여 데이터가 분산되는 방식을 확인합니다.
Timechart
마지막 단원에서 본 일부 데이터 열 중 일부는 DateTime 형식이며 Storm 이벤트의 시작 및 종료 시간을 나타냅니다. Storm 데이터 이벤트가 있는 날짜를 확인하기 위해 항목 수와 시간을 플롯할 수 있습니다.
이전 단원에서는 50개의 데이터 행 하위 집합을 사용했지만 이 단원에서는 전체 데이터 세트를 사용합니다.
다음 쿼리는 시간 함수로 8시간 bin당 Storm 이벤트 수의 시간 차트를 만듭니다.
다음 쿼리를 실행합니다.
StormEvents | summarize Count = count() by bin (StartTime, 8h) | render timechart다음 이미지와 같은 결과가 표시됩니다.
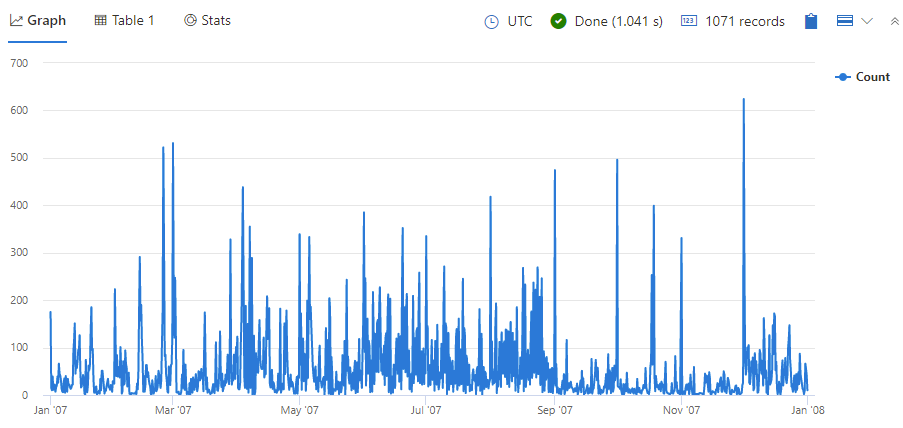
결과 그래프를 살펴보세요. 명백한 간격이나 변칙이 보이나요?
상태별 이벤트
데이터 배포를 확인하는 또 다른 방법은 이벤트 위치(이 경우 상태)를 기준으로 그룹화하여 배포에서 이해할 수 있는 경향을 확인하는 것입니다.
다음 쿼리를 실행합니다.
StormEvents | summarize event = count() by State | sort by event | render barchart다음 이미지와 같은 결과가 표시됩니다.
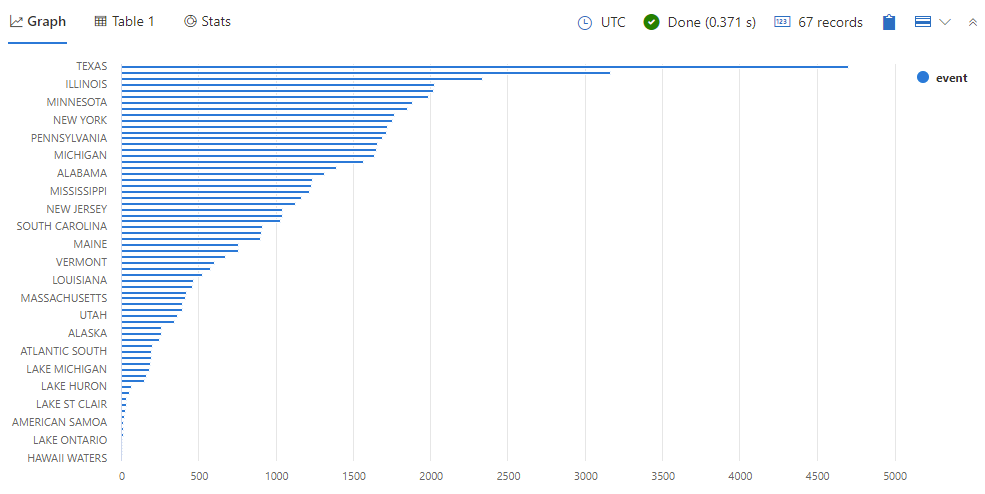
결과 그래프를 살펴보세요. 목록에는 "아메리칸 사모아" 및 "하와이 해역"과 같이 미국의 공식 주가 아닌 주를 포함하여 67개 주가 있습니다. 이러한 유형의 지리적 storm 분포가 의미가 있나요?
차트 위의 테이블 탭을 선택하면 기본 데이터를 볼 수 있습니다. 실제 숫자가 데이터 분포를 더 잘 이해하는 데 도움이 되나요?
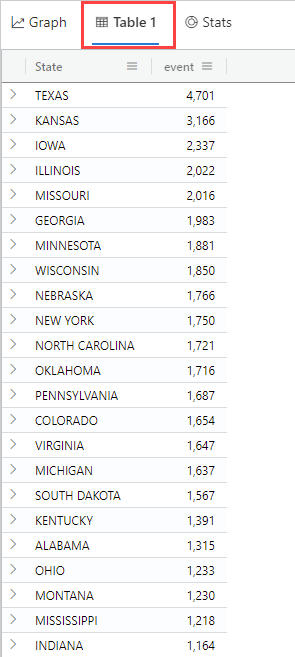
지리적 위치별 이벤트
이벤트 수가 시간과 상태에 따라 어떻게 달라지는지 살펴보았습니다. 스키마 매핑은 각 Storm 이벤트 항목에 위도 및 경도 정보가 포함되어 있음을 보여 줍니다. 데이터 클러스터가 맵에서 어떻게 표시되는지 살펴보겠습니다.
다음 쿼리는 지리적 셀별로 이벤트를 그룹화하고 각 셀의 이벤트 수를 계산합니다. 이러한 결과는 맵에 표시됩니다. 여기서 원 크기는 해당 셀의 이벤트 수에 해당합니다. 다음 쿼리를 실행합니다.
StormEvents | project BeginLon, BeginLat | where isnotnull(BeginLat) and isnotnull(BeginLon) | summarize count_summary=count() by hash = geo_point_to_s2cell(BeginLon, BeginLat,6) | project geo_s2cell_to_central_point(hash), count_summary | extend Events = "count" | render piechart with (kind = map)다음 이미지와 같은 결과가 표시됩니다.
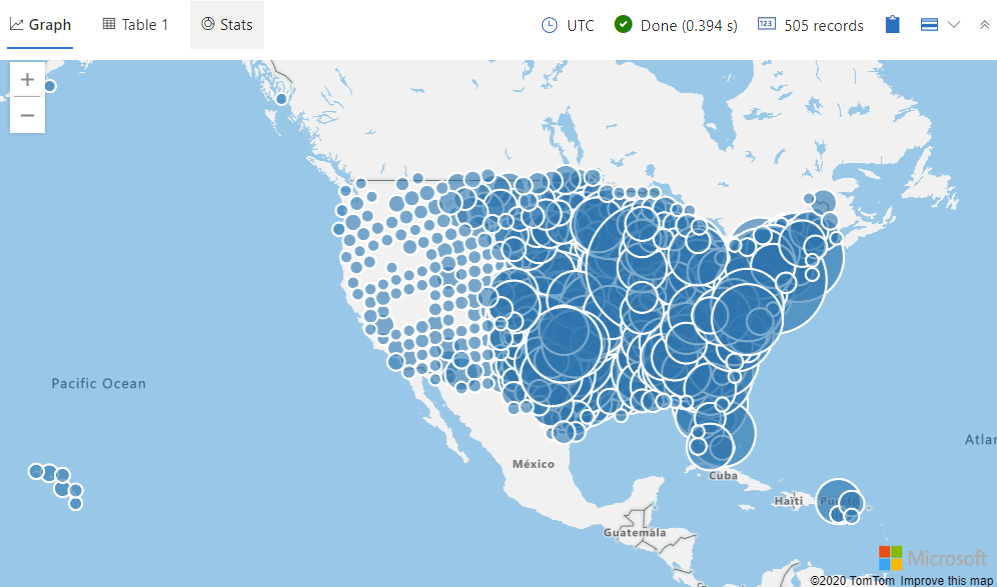
Ctrl +를 눌러 확대해 보세요. 이제 폭풍의 유형을 보았으므로 미국 북동부 지역과 멕시코 만에 이러한 유형의 폭풍이 더 있다는 것이 이해가 되나요?