연습 - 신경망 구축 및 학습
이 단원에서는 Keras를 사용하여 감정 텍스트를 분석하는 신경망을 구축하고 학습합니다. 신경망을 학습시키려면 데이터를 사용하여 학습해야 합니다. 외부 데이터 세트를 다운로드하는 대신, Keras에 포함된 IMDB 영화 리뷰 감정 분류 데이터 세트를 사용합니다. IMDB 데이터 세트에는 개별적으로 양수(1) 또는 음수(0)로 채점된 50,000개의 영화 리뷰가 포함되어 있습니다. 이 데이터 세트는 학습을 위한 25,000개의 학습용 리뷰과 25,000개의 테스트용 리뷰로 나뉩니다. 이러한 리뷰에서 표현된 감정은 신경망에서 제공된 텍스트를 분석하여 감정에 대한 점수를 매기는 기초입니다.
IMDB 데이터 세트는 Keras에 포함된 몇 가지 유용한 데이터 세트 중 하나입니다. 기본 제공 데이터 세트의 전체 목록은 https://keras.io/datasets/.를 참조하세요.
Notebook의 첫 번째 셀에 다음 코드를 입력하거나 붙여넣고, 실행 단추를 클릭하거나 Shift+Enter를 눌러 코드를 실행하고, 그 아래에 새 셀을 추가합니다.
from keras.datasets import imdb top_words = 10000 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=top_words)이 코드는 Keras에 포함된 IMDB 데이터 세트를 로드하고, 50,000개 리뷰 모두의 단어를 해당 단어의 상대적 발생 빈도를 나타내는 정수에 매핑하는 사전을 만듭니다. 각 단어에는 고유한 정수가 할당됩니다. 가장 일반적인 단어에는 숫자 1, 두 번째로 가장 일반적인 단어에는 숫자 2 등으로 할당됩니다. 또한
load_data는 영화 리뷰(이 예제에서는x_train및x_test)가 포함된 튜플 쌍 및 이러한 리뷰를 긍정과 부정(y_train및y_test)으로 분류하는 1과 0도 반환합니다.Keras에서 TensorFlow를 백 엔드로 사용하고 있음을 나타내는 "TensorFlow 백 엔드 사용 중" 메시지가 표시되는지 확인합니다.
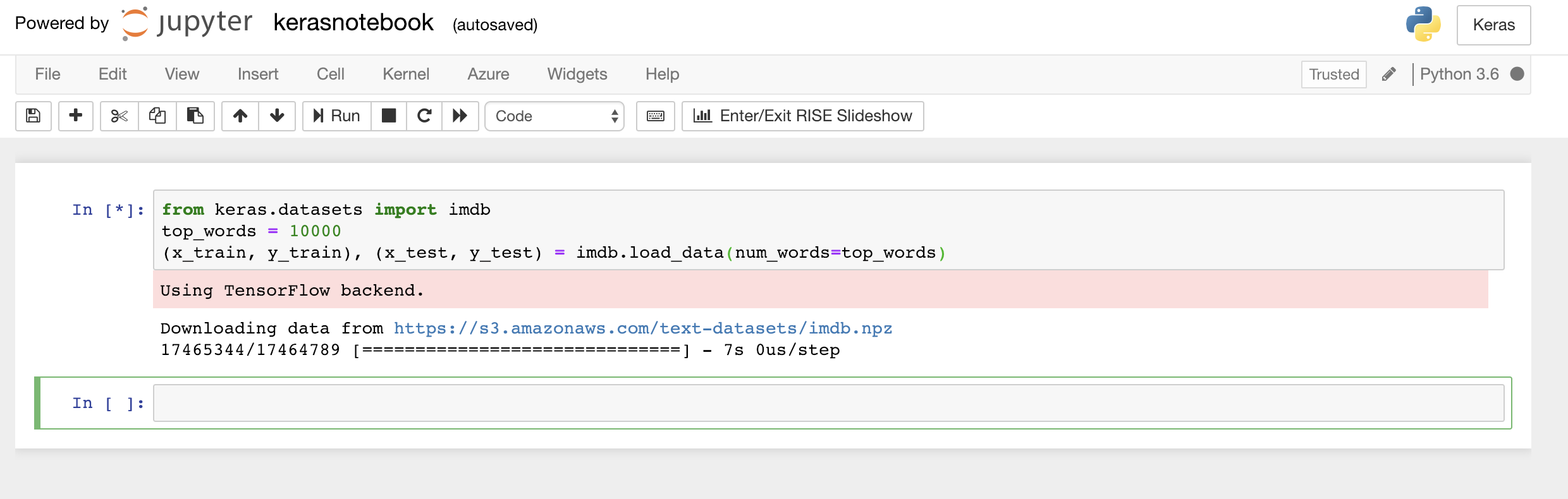
IMDB 데이터 세트 로드
Keras에서 Microsoft Cognitive Toolkit(CNTK라고도 함)를 백 엔드로 사용하도록 하려면 Notebook 시작 부분에 몇 줄의 코드를 추가하면 됩니다. 예제는 Azure Notebooks의 CNTK 및 Keras를 참조하세요.
결과적으로
load_data함수는 정확히 무엇을 로드했을까요?x_train이라는 변수는 25,000개의 목록이며, 각각 하나의 영화 리뷰를 나타냅니다. (x_test도 25,000개의 리뷰를 나타내는 25,000개의 목록으로 구성된 목록입니다.x_train은 학습용이지만,x_test는 테스트용입니다.) 그러나 영화 리뷰를 대표하는 내부 목록에는 단어가 아니라 정수가 포함되어 있습니다. Keras 설명서에서 설명하는 방법은 다음과 같습니다.
내부 목록에 텍스트가 아닌 숫자가 포함되는 이유는 신경망에서 텍스트가 아니라 숫자를 사용하여 학습하기 때문입니다. 특히 텐서(tensor)를 사용하여 학습합니다. 이 경우 각 리뷰는 해당 리뷰에 포함된 단어를 식별하는 정수를 포함하는 1차원 텐서(1차원 배열로 간주됨)입니다. 이를 시연하려면 다음 Python 문을 빈 셀에 입력하고 실행하여 학습 집합의 첫 번째 리뷰를 나타내는 정수를 확인합니다.
x_train[0]
IMDB 학습 집합의 첫 번째 리뷰를 구성하는 정수
목록의 첫 번째 숫자인 1은 단어를 전혀 나타내지 않습니다. 이는 리뷰의 시작을 표시하며, 데이터 세트의 모든 리뷰에 대해 동일합니다. 숫자 0과 2도 예약되어 있으며, 다른 숫자에서 3을 빼서 리뷰의 정수를 사전의 해당 정수에 매핑합니다. 두 번째 숫자 14는 사전의 숫자 11에 해당하는 단어를 참조하고, 세 번째 숫자는 사전의 숫자 19에 할당된 단어를 나타내는 등의 방식입니다.
사전이 어떻게 표시되는지 궁금한가요? 새 Notebook 셀에서 다음 명령문을 실행합니다.
imdb.get_word_index()사전 항목의 하위 집합만 표시되지만, 사전에는 88,000개가 넘는 단어와 해당 항목에 해당하는 정수가 포함되어 있습니다.
load_data를 호출할 때마다 사전이 새로 생성되므로 표시되는 출력이 스크린샷의 출력과 일치하지 않을 수 있습니다.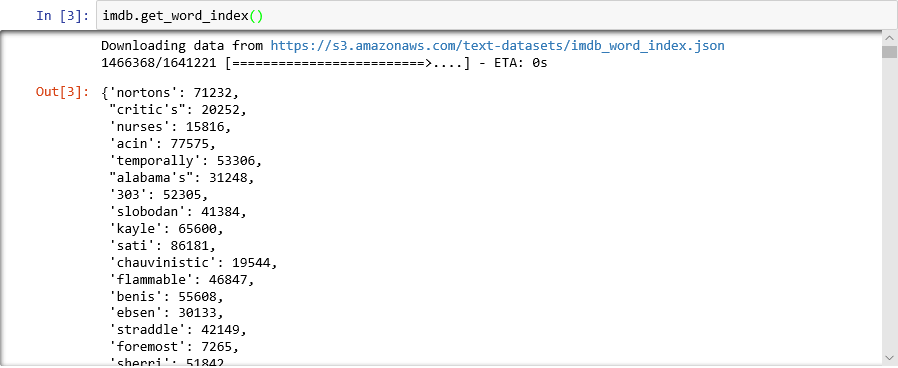
단어를 정수에 매핑하는 사전
앞에서 설명한 대로 데이터 세트의 각 리뷰는 단어가 아닌 정수의 컬렉션으로 인코딩됩니다. 리뷰를 역방향 인코딩하여 구성된 원본 텍스트를 볼 수 있을까요? 다음 명령문을 새 셀에 입력하고 실행하여
x_train의 첫 번째 리뷰를 텍스트 형식으로 표시합니다.word_dict = imdb.get_word_index() word_dict = { key:(value + 3) for key, value in word_dict.items() } word_dict[''] = 0 # Padding word_dict['>'] = 1 # Start word_dict['?'] = 2 # Unknown word reverse_word_dict = { value:key for key, value in word_dict.items() } print(' '.join(reverse_word_dict[id] for id in x_train[0]))출력에서 ">"는 리뷰의 시작을 표시하고, "?"는 데이터 세트에서 가장 일반적인 10,000개 단어에 속하지 않는 아닌 단어를 표시합니다. 이러한 "알 수 없는" 단어는 리뷰를 나타내는 정수 목록에서 2로 표시됩니다.
load_data에 전달한num_words매개 변수를 기억하는가요? 이 매개 변수는 작동을 시작하는 위치입니다. 사전의 크기는 줄이지 않지만, 리뷰를 인코딩하는 데 사용되는 정수의 범위를 제한합니다.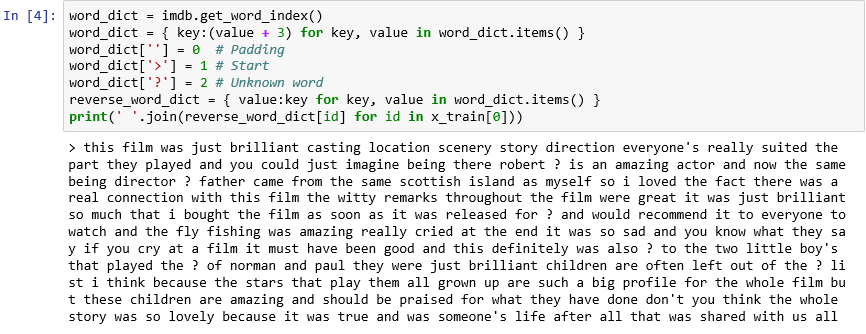
텍스트 형식의 첫 번째 리뷰
문자가 소문자로 변환되고 문장 부호가 제거되었다는 점에서 리뷰는 "깨끗이 정리된" 상태입니다. 하지만 리뷰는 감정 텍스트를 분석할 신경망을 학습시킬 준비가 되어 있지 않습니다. 텐서 컬렉션을 사용하여 신경망을 학습시킬 때 각 텐서의 길이는 동일해야 합니다. 현재
x_train및x_test의 리뷰를 나타내는 목록의 길이는 다양합니다.다행히도 Keras에는 목록의 목록을 입력으로 사용하고, 필요한 경우 잘라내거나 0으로 채워 내부 목록을 지정된 길이로 변환하는 함수가 포함되어 있습니다. 다음 코드를 Notebook에 입력하고 실행하여
x_train및x_test의 영화 리뷰를 나타내는 모든 목록의 길이를 500개 정수로 강제 적용합니다.from keras.preprocessing import sequence max_review_length = 500 x_train = sequence.pad_sequences(x_train, maxlen=max_review_length) x_test = sequence.pad_sequences(x_test, maxlen=max_review_length)이제 학습 및 테스트 데이터가 준비되었으므로 모델을 작성할 시간입니다! Notebook에서 다음 코드를 실행하여 감정 분석을 수행하는 신경망을 만듭니다.
from keras.models import Sequential from keras.layers import Dense from keras.layers.embeddings import Embedding from keras.layers import Flatten embedding_vector_length = 32 model = Sequential() model.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length)) model.add(Flatten()) model.add(Dense(16, activation='relu')) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy']) print(model.summary())출력이 다음과 같이 표시되는지 확인합니다.
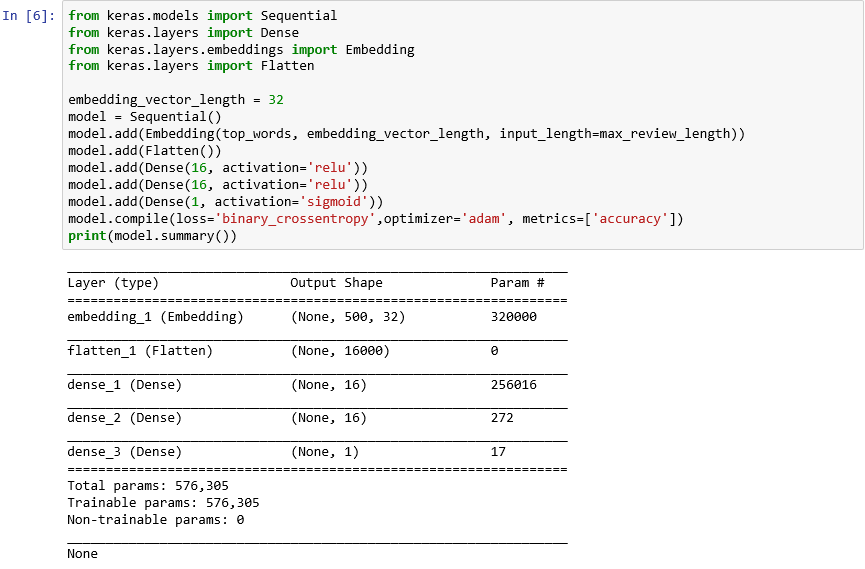
Keras를 사용하여 신경망 만들기
이 코드는 Keras와 신경망을 구성하는 방법의 핵심입니다. 먼저 한 계층의 출력에서 다른 계층의 입력을 제공하는 엔드투엔드 계층 스택으로 구성된 "순차적" 모델을 나타내는
Sequential개체를 인스턴스화합니다.다음 몇 가지 명령문에서 계층을 모델에 추가합니다. 첫 번째 계층은 단어를 처리하는 신경망에 매우 중요한 포함 계층입니다. 포함 계층은 기본적으로 정수 단어 인덱스가 포함된 다차원 배열을 더 적은 차원이 포함된 부동 소수점 배열에 매핑합니다. 또한 비슷한 의미를 가진 단어도 동일하게 처리할 수 있습니다. 단어 포함을 완전히 처리하는 것은 이 랩의 범위를 벗어나지만, 포함 계층을 사용하여 시작해야 하는 이유를 참조하여 자세히 알아볼 수 있습니다. 좀 더 학술적인 설명을 원하는 경우 벡터 공간의 단어 표현에 대한 효율적인 추정을 참조하세요. 포함 계층 추가 이후의 Flatten 호출은 다음 계층의 입력을 위한 출력을 다시 구성합니다.
모델에 추가되는 다음 세 개의 계층은 밀집(dense) 계층이며, 완전히 연결된 계층이라고도 합니다. 이러한 계층은 신경망에서 일반적인 기존 계층입니다. 각 계층에는 n개 노드 또는 뉴런이 포함되며, 각 뉴런은 이전 계층의 모든 뉴런에서 입력을 받으므로 "완전히 연결됨"이라는 표현을 사용합니다. 이러한 계층은 신경망이 출력을 반복적으로 추측하고, 결과를 확인하고, 연결을 미세 튜닝하여 더 나은 결과를 생성하여 입력 데이터를 통해 "학습"할 수 있게 합니다. 이 네트워크에서 처음 두 개의 밀집 계층에는 각각 16개의 뉴런이 있습니다. 이 숫자는 임의로 선택되었습니다. 다른 크기로 실험하여 모델의 정확도를 향상시킬 수 있습니다. 네트워크의 궁극적인 목표는 하나의 출력, 즉 0.0~1.0의 감정 점수를 예측하는 것이므로 최종 밀집 계층은 하나의 뉴런만 포함합니다.
결과는 아래 그림과 같은 신경망입니다. 네트워크에는 입력 계층, 출력 계층 및 두 개의 숨겨진 계층(각각 16개의 뉴런이 포함된 밀집 계층)이 있습니다. 비교를 위해 오늘날의 더 정교한 신경망 중 일부에는 100개가 넘는 계층이 있습니다. 한 가지 예로 사진에서 개체를 식별하는 정확도가 때로는 사람의 정확도보다 더 높은 Microsoft Research의 ResNet-152가 있습니다. Keras를 사용하여 ResNet-152를 구축할 수는 있지만, 처음부터 학습하려면 GPU가 장착된 컴퓨터 클러스터가 필요합니다.
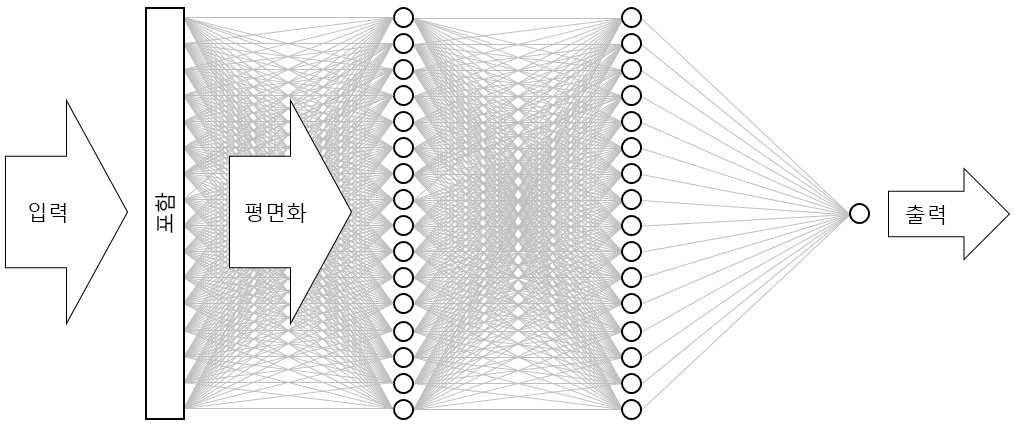
신경망 시각화
compile 함수 호출은 각 학습 단계에서 모델의 정확도를 판단하는 데 사용할 optimizer 및 metrics와 같은 중요한 매개 변수를 지정하여 모델을 "컴파일"합니다. 모델의
fit함수를 호출해야 학습이 시작되므로 일반적으로compile호출이 빠르게 실행됩니다.이제 fit 함수를 호출하여 신경망을 학습시킵니다.
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=5, batch_size=128)학습에는 약 6분 또는 Epoch당 1분을 약간 초과하는 시간이 걸립니다.
epochs=5는 모델을 통해 앞뒤로 5번 전달하도록 Keras에 지시합니다. 각 전달에서 모델은 학습 데이터에서 학습하고 테스트 데이터를 사용하여 학습한 정도를 측정("유효성 검사")합니다. 그런 다음, 조정하고 다음 전달 또는 Epoch로 돌아갑니다. 이는 각 Epoch에 대한 학습 정확도(acc) 및 유효성 검사 정확도(val_acc)를 보여 주는fit함수의 출력에 반영됩니다.batch_size=128은 한 번에 128개의 학습 샘플을 사용하여 네트워크를 학습시키도록 Keras에 지시합니다. 일괄 처리 크기가 클수록 학습 시간이 단축되지만(각 Epoch에서 모든 학습 데이터를 사용하는 데 필요한 전달 횟수가 줄어듦), 일괄 처리 크기가 작을수록 정확도가 높아지는 경우가 있습니다. 이 랩이 완료되면 일괄 처리 크기가 32인 모델로 돌아가고 재학습하여 모델의 정확도에 미친 영향을 확인하는 것이 좋습니다. 학습 시간이 대략 두 배 정도 걸립니다.
모델 학습
이 모델은 단지 몇 개의 Epoch를 사용하여 적절하게 학습한다는 점에서 특이합니다. 학습 정확도는 거의 100%로 빠르게 확대되는 반면, 유효성 검사 정확도는 한두 개의 Epoch로 올라간 후에 평면화됩니다. 일반적으로 이러한 정확도를 안정화하는 데 필요한 시간보다 더 오랫동안 모델을 학습시키지 않으려고 합니다. 위험은 과잉 맞춤에 있습니다. 이 경우 모델은 테스트 데이터에서 효율적으로 수행되지만 실제 데이터에서는 그렇지 않습니다. 과잉 맞춤된 모델임을 나타내는 한 가지 징후는 학습 정확도와 유효성 검사 정확도 사이의 불일치가 증가하고 있다는 것입니다. 과잉 맞춤(Overfitting)에 대한 훌륭한 소개는 Machine Learning의 과잉 맞춤: 정의 및 방지하는 방법을 참조하세요.
학습 진행에 따른 학습 및 유효성 검사 정확도의 변화를 시각화하려면 새 Notebook 셀에서 다음 명령문을 실행합니다.
import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline sns.set() acc = hist.history['acc'] val = hist.history['val_acc'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, '-', label='Training accuracy') plt.plot(epochs, val, ':', label='Validation accuracy') plt.title('Training and Validation Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend(loc='upper left') plt.plot()정확도 데이터는 모델의
fit함수에서 반환된history개체에서 가져옵니다. 표시된 차트에 따라 학습 Epoch의 수를 늘리거나 줄이거나 그대로 유지하는 것이 좋을까요?과잉 맞춤을 확인하는 또 다른 방법은 학습 진행 과정에서 학습 손실과 유효성 검사 손실을 비교하는 것입니다. 이와 같은 최적화 문제는 손실 함수를 최소화하려고 합니다. 자세한 내용은 여기를 참조하세요. 지정된 Epoch에서 유효성 검사 손실보다 훨씬 큰 학습 손실은 과잉 맞춤의 증거가 될 수 있습니다. 이전 단계에서는
history개체의history속성의acc및val_acc속성을 사용하여 학습 및 유효성 검사 정확도를 계산했습니다. 또한 동일한 속성에는 각각 학습 손실과 유효성 검사 손실을 나타내는loss및val_loss값도 포함되어 있습니다. 이러한 값을 계산하여 아래와 같은 차트를 생성하려면 위의 코드를 어떻게 수정해야 할까요?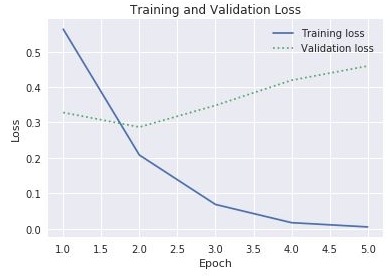
학습 손실 및 유효성 검사 손실
학습 손실과 유효성 검사 손실의 차이가 3번째 Epoch에서 커지기 시작한다는 점을 고려할 때 누군가가 Epoch의 수를 10 또는 20개로 늘리도록 제안하면 어떻게 해야 할까요?
마지막으로, 모델의
evaluate메서드를 호출하여 모델에서x_test(리뷰) 및y_test(0 및 1, 또는 긍정 또는 부정적인 리뷰를 나타내는 "레이블")의 테스트 데이터에 기반하여 텍스트로 표현된 감정을 정량화할 수 있는 정확도를 결정합니다.scores = model.evaluate(x_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1] * 100))모델에 대해 계산된 정확도는 얼마일까요?
아마도 85~90%의 정확도를 달성했을 것입니다. 미리 학습된 신경망을 사용하는 것과는 달리 모델을 처음부터 작성했으며 GPU를 사용하지 않더라도 학습 시간이 짧다는 점을 고려할 때 이 정확도는 적합합니다. 대체 신경망 아키텍처, 특히 LSTM(장단기 메모리) 계층을 활용하는 RNN(순환 신경망)을 통해 95% 이상의 정확도를 달성할 수 있습니다. Keras를 사용하면 이러한 네트워크를 쉽게 구축할 수 있지만 학습 시간은 기하급수적으로 늘어날 수 있습니다. 작성한 모델은 정확도와 학습 시간 간에 적절한 균형을 유지합니다. 그러나 Keras를 사용하여 RNN을 구축하는 방법에 대한 자세한 내용은 감정 분석을 위한 LSTM 및 Keras에서의 빠른 구현 이해를 참조하세요.