Python 자습서: SQL 기계 학습을 사용하여 선형 회귀 모델 배포
적용 대상: ![]() SQL Server 2017(14.x) 이상
SQL Server 2017(14.x) 이상 ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
4부로 구성된 이 자습서 시리즈의 4부에서는 Machine Learning Services 또는 빅 데이터 클러스터를 사용하여 Python으로 개발된 선형 회귀 모델을 SQL Server 데이터베이스에 배포합니다.
4부로 구성된 이 자습서 시리즈의 4부에서는 Machine Learning Services를 사용하여 Python으로 개발된 선형 회귀 모델을 SQL Server 데이터베이스에 배포합니다.
4부로 구성된 이 자습서 시리즈의 4부에서는 Machine Learning Services를 사용하여 Python에서 개발된 선형 회귀 모델을 Azure SQL Managed Instance 데이터베이스에 배포합니다.
이 문서에서는 다음을 수행하는 방법을 알아봅니다.
- 기계 학습 모델을 생성하는 저장 프로시저 만들기
- 모델을 데이터베이스 테이블에 저장
- 모델을 사용하여 예측을 수행하는 저장 프로시저 만들기
- 새 데이터를 사용하여 모델 실행
1부에서는 샘플 데이터베이스를 복원하는 방법을 알아보았습니다.
2부에서는 데이터베이스의 데이터를 Python 데이터 프레임에 로드하고, Python에서 데이터를 준비하는 방법을 알아보았습니다.
3부에서는 Python에서 선형 회귀 기계 학습 모델을 학습하는 방법을 알아보았습니다.
필수 조건
- 이 자습서의 4부에서는 1부와 해당 사전 요구 사항을 완료했다고 가정합니다.
모델을 생성하는 저장 프로시저 만들기
이제 개발한 Python 스크립트를 사용하여 scikit-learn에서 LinearRegression을 사용하여 선형 회귀 모델을 학습하고 생성하는 저장 프로시저인 generate_rental_py_model을 만듭니다.
Azure Data Studio에서 다음 T-SQL 문을 실행하여 모델을 학습시키는 저장 프로시저를 만듭니다.
-- Stored procedure that trains and generates a Python model using the rental_data and a linear regression algorithm
DROP PROCEDURE IF EXISTS generate_rental_py_model;
go
CREATE PROCEDURE generate_rental_py_model (@trained_model varbinary(max) OUTPUT)
AS
BEGIN
EXECUTE sp_execute_external_script
@language = N'Python'
, @script = N'
from sklearn.linear_model import LinearRegression
import pickle
df = rental_train_data
# Get all the columns from the dataframe.
columns = df.columns.tolist()
# Store the variable well be predicting on.
target = "RentalCount"
# Initialize the model class.
lin_model = LinearRegression()
# Fit the model to the training data.
lin_model.fit(df[columns], df[target])
# Before saving the model to the DB table, convert it to a binary object
trained_model = pickle.dumps(lin_model)'
, @input_data_1 = N'select "RentalCount", "Year", "Month", "Day", "WeekDay", "Snow", "Holiday" from dbo.rental_data where Year < 2015'
, @input_data_1_name = N'rental_train_data'
, @params = N'@trained_model varbinary(max) OUTPUT'
, @trained_model = @trained_model OUTPUT;
END;
GO
모델을 데이터베이스 테이블에 저장
TutorialDB 데이터베이스에 테이블을 만든 다음, 모델을 테이블에 저장합니다.
Azure Data Studio에서 다음 T-SQL 문을 실행하여 모델을 저장하는 데 사용되는 dbo.rental_py_models 테이블을 만듭니다.
USE TutorialDB; DROP TABLE IF EXISTS dbo.rental_py_models; GO CREATE TABLE dbo.rental_py_models ( model_name VARCHAR(30) NOT NULL DEFAULT('default model') PRIMARY KEY, model VARBINARY(MAX) NOT NULL ); GO모델 이름을 linear_model로 모델을 이진 개체로 테이블에 저장합니다.
DECLARE @model VARBINARY(MAX); EXECUTE generate_rental_py_model @model OUTPUT; INSERT INTO rental_py_models (model_name, model) VALUES('linear_model', @model);
예측을 수행하는 저장 프로시저 만들기
학습된 모델 및 새 데이터 세트를 사용하여 예측하는 저장 프로시저 py_predict_rentalcount를 만듭니다. Azure Data Studio에서 아래 T-SQL을 실행합니다.
DROP PROCEDURE IF EXISTS py_predict_rentalcount; GO CREATE PROCEDURE py_predict_rentalcount (@model varchar(100)) AS BEGIN DECLARE @py_model varbinary(max) = (select model from rental_py_models where model_name = @model); EXECUTE sp_execute_external_script @language = N'Python', @script = N' # Import the scikit-learn function to compute error. from sklearn.metrics import mean_squared_error import pickle import pandas rental_model = pickle.loads(py_model) df = rental_score_data # Get all the columns from the dataframe. columns = df.columns.tolist() # Variable you will be predicting on. target = "RentalCount" # Generate the predictions for the test set. lin_predictions = rental_model.predict(df[columns]) print(lin_predictions) # Compute error between the test predictions and the actual values. lin_mse = mean_squared_error(lin_predictions, df[target]) #print(lin_mse) predictions_df = pandas.DataFrame(lin_predictions) OutputDataSet = pandas.concat([predictions_df, df["RentalCount"], df["Month"], df["Day"], df["WeekDay"], df["Snow"], df["Holiday"], df["Year"]], axis=1) ' , @input_data_1 = N'Select "RentalCount", "Year" ,"Month", "Day", "WeekDay", "Snow", "Holiday" from rental_data where Year = 2015' , @input_data_1_name = N'rental_score_data' , @params = N'@py_model varbinary(max)' , @py_model = @py_model with result sets (("RentalCount_Predicted" float, "RentalCount" float, "Month" float,"Day" float,"WeekDay" float,"Snow" float,"Holiday" float, "Year" float)); END; GO예측을 저장하기 위한 테이블을 만듭니다.
DROP TABLE IF EXISTS [dbo].[py_rental_predictions]; GO CREATE TABLE [dbo].[py_rental_predictions]( [RentalCount_Predicted] [int] NULL, [RentalCount_Actual] [int] NULL, [Month] [int] NULL, [Day] [int] NULL, [WeekDay] [int] NULL, [Snow] [int] NULL, [Holiday] [int] NULL, [Year] [int] NULL ) ON [PRIMARY] GO저장 프로시저를 실행하여 임대 횟수 예측
--Insert the results of the predictions for test set into a table INSERT INTO py_rental_predictions EXEC py_predict_rentalcount 'linear_model'; -- Select contents of the table SELECT * FROM py_rental_predictions;다음과 유사한 결과가 표시되어야 합니다.
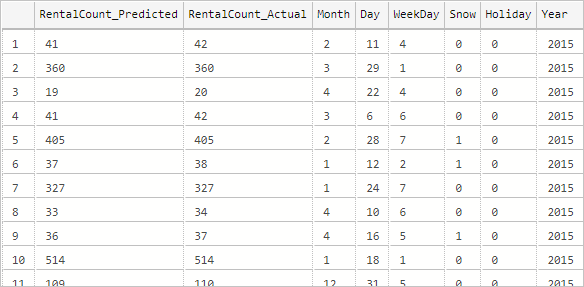
성공적으로 모델을 만들고, 학습하고, 배포했습니다. 그런 다음 저장 프로시저에서 해당 모델을 사용하여 새 데이터를 기반으로 값을 예측했습니다.
다음 단계
이 자습서 시리즈의 4부에서는 다음 단계를 완료했습니다.
- 기계 학습 모델을 생성하는 저장 프로시저 만들기
- 모델을 데이터베이스 테이블에 저장
- 모델을 사용하여 예측을 수행하는 저장 프로시저 만들기
- 새 데이터를 사용하여 모델 실행
SQL 기계 학습을 통해 Python을 사용하는 방법에 대한 자세한 정보는 다음을 참조하세요.