Python 자습서: SQL 기계 학습을 사용하여 고객을 분류하는 모델 빌드
적용 대상: ![]() SQL Server 2017(14.x) 이상
SQL Server 2017(14.x) 이상 ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
4부로 구성된 자습서 시리즈의 3부에서는 Python에서 K-평균 모델을 빌드하여 클러스터링을 수행합니다. 이 시리즈의 다음 파트에서는 SQL Server Machine Learning Services를 사용하는 데이터베이스 또는 빅 데이터 클러스터에 이 모델을 배포합니다.
4부로 구성된 자습서 시리즈의 3부에서는 Python에서 K-평균 모델을 빌드하여 클러스터링을 수행합니다. 이 시리즈의 다음 파트에서는 SQL Server Machine Learning Services를 사용하여 이 모델을 데이터베이스에 배포합니다.
4부로 구성된 자습서 시리즈의 3부에서는 Python에서 K-평균 모델을 빌드하여 클러스터링을 수행합니다. 이 시리즈의 다음 부분에서는 Azure SQL Managed Instance Machine Learning Services를 사용하여 데이터베이스에 이 모델을 배포합니다.
이 문서에서는 다음을 수행하는 방법을 알아봅니다.
- KI-평균 알고리즘에 대한 클러스터 수 정의
- 클러스터링 수행
- 결과 분석
1부에서는 필수 구성 요소를 설치하고 샘플 데이터베이스를 복원했습니다.
2부에서는 클러스터링을 수행하기 위해 데이터베이스의 데이터를 준비하는 방법을 배웠습니다.
4부에서는 새 데이터를 기준으로 Python에서 클러스터링을 수행할 수 있는 저장 프로시저를 데이터베이스에서 만드는 방법을 알아봅니다.
필수 조건
클러스터 수 정의
고객 데이터를 클러스터링하기 위해서는 데이터 그룹화를 위해 가장 잘 알려져 있고 가장 간단한 방법 중 하나인 K-평균 클러스터링 알고리즘을 사용합니다. K-평균 클러스터링 알고리즘에 대한 전체 가이드에서 K-평균에 대해 자세히 읽을 수 있습니다.
알고리즘은 데이터 자체와 생성할 클러스터 수를 나타내는 미리 정의된 숫자 "k"의 두 가지 입력을 허용합니다. 출력은 클러스터 간에 분할된 입력 데이터가 있는 k 클러스터입니다.
K-평균의 목표는 동일한 클러스터의 모든 항목이 서로 유사하고 가능한 한 다른 클러스터의 항목과 다르도록 항목을 k 클러스터로 그룹화하는 것입니다.
알고리즘에서 사용할 클러스터 수를 확인하려면 그룹 내의 제곱 합계(추출된 클러스터 수)의 플롯을 사용합니다. 사용할 적절한 클러스터 수는 플롯의 굽은 지점 또는 "elbow"에 있습니다.
################################################################################################
## Determine number of clusters using the Elbow method
################################################################################################
cdata = customer_data
K = range(1, 20)
KM = (sk_cluster.KMeans(n_clusters=k).fit(cdata) for k in K)
centroids = (k.cluster_centers_ for k in KM)
D_k = (sci_distance.cdist(cdata, cent, 'euclidean') for cent in centroids)
dist = (np.min(D, axis=1) for D in D_k)
avgWithinSS = [sum(d) / cdata.shape[0] for d in dist]
plt.plot(K, avgWithinSS, 'b*-')
plt.grid(True)
plt.xlabel('Number of clusters')
plt.ylabel('Average within-cluster sum of squares')
plt.title('Elbow for KMeans clustering')
plt.show()
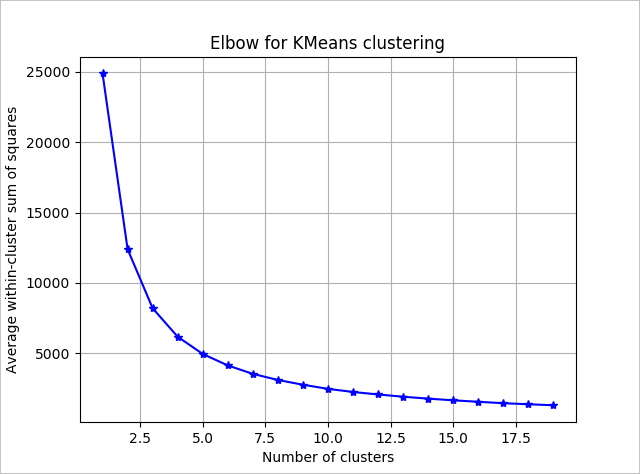
그래프에 따르면 k = 4가 적합한 값으로 보입니다. 해당 k 값은 고객을 4개의 클러스터로 그룹화합니다.
클러스터링 수행
다음 Python 스크립트에서는 sklearn 패키지의 KMeans 함수를 사용합니다.
################################################################################################
## Perform clustering using Kmeans
################################################################################################
# It looks like k=4 is a good number to use based on the elbow graph.
n_clusters = 4
means_cluster = sk_cluster.KMeans(n_clusters=n_clusters, random_state=111)
columns = ["orderRatio", "itemsRatio", "monetaryRatio", "frequency"]
est = means_cluster.fit(customer_data[columns])
clusters = est.labels_
customer_data['cluster'] = clusters
# Print some data about the clusters:
# For each cluster, count the members.
for c in range(n_clusters):
cluster_members=customer_data[customer_data['cluster'] == c][:]
print('Cluster{}(n={}):'.format(c, len(cluster_members)))
print('-'* 17)
print(customer_data.groupby(['cluster']).mean())
결과 분석
이제 K-평균을 사용하여 클러스터링을 수행했으므로 다음 단계는 결과를 분석하고 실행 가능한 정보를 찾을 수 있는지 확인하는 것입니다.
이전 스크립트에서 인쇄된 클러스터링 평균 값 및 클러스터링 크기를 살펴봅니다.
Cluster0(n=31675):
-------------------
Cluster1(n=4989):
-------------------
Cluster2(n=1):
-------------------
Cluster3(n=671):
-------------------
customer orderRatio itemsRatio monetaryRatio frequency
cluster
0 50854.809882 0.000000 0.000000 0.000000 0.000000
1 51332.535779 0.721604 0.453365 0.307721 1.097815
2 57044.000000 1.000000 2.000000 108.719154 1.000000
3 48516.023845 0.136277 0.078346 0.044497 4.271237
1부에 정의된 변수를 사용하여 4개의 클러스터 평균이 제공되었습니다.
- orderRatio = 반품 주문 비율(총 주문 수 대비 부분적으로 또는 완전히 반환된 총 주문 수)
- itemsRatio = 반품 항목 비율(구입한 항목 수 대비 반품된 총 항목 수)
- monetaryRatio = 반품 금액 비율(반환된 항목의 총 금액과 구매한 금액)
- frequency = 반품 빈도
K-평균을 사용한 데이터 마이닝에는 결과에 대한 추가 분석과 각 클러스터를 더 잘 이해하기 위한 추가 단계가 필요한 경우가 많지만 몇 가지 좋은 단서를 제공할 수 있습니다. 이러한 결과를 해석할 수 있는 몇 가지 방법은 다음과 같습니다.
- 클러스터 0은 활성화되지 않은 고객 그룹인 것 같습니다(모든 값은 0).
- 클러스터 3은 반품 비중이 높은 그룹으로 보입니다.
클러스터 0은 확실히 활성 상태가 아닌 고객 집합입니다. 아마도 이 그룹에 대한 마케팅 활동을 목표로 하여 구매에 대한 관심을 트리거할 수 있습니다. 다음 단계에서는 클러스터 0에 있는 고객의 이메일 주소에 대한 데이터베이스를 쿼리하여 마케팅 전자 메일을 보낼 수 있습니다.
리소스 정리
이 자습서를 계속 진행하지 않으려면 tpcxbb_1gb 데이터베이스를 삭제하세요.
다음 단계
이 자습서 시리즈의 3부에서는 다음 단계를 완료했습니다.
- KI-평균 알고리즘에 대한 클러스터 수 정의
- 클러스터링 수행
- 결과 분석
만든 기계 학습 모델을 배포하려면 다음 자습서 시리즈의 4부를 따르세요.