Visual Studio Code에서 SQL Server 빅 데이터 클러스터에 대한 Spark 작업 제출
중요
Microsoft SQL Server 2019 빅 데이터 클러스터 추가 기능이 사용 중지됩니다. SQL Server 2019 빅 데이터 클러스터에 대한 지원은 2025년 2월 28일에 종료됩니다. Software Assurance를 사용하는 SQL Server 2019의 모든 기존 사용자는 플랫폼에서 완전히 지원되며, 소프트웨어는 지원 종료 시점까지 SQL Server 누적 업데이트를 통해 계속 유지 관리됩니다. 자세한 내용은 공지 블로그 게시물 및 Microsoft SQL Server 플랫폼의 빅 데이터 옵션을 참조하세요.
Visual Studio Code용 Spark & Hive Tools를 사용하여 Apache Spark용 PySpark 스크립트를 만들고 제출하는 방법을 알아봅니다. 먼저 Visual Studio Code에서 Spark & Hive Tools를 설치하는 방법을 설명한 다음 Spark에 작업을 제출하는 방법을 안내합니다.
Windows, Linux 및 macOS를 비롯한 Visual Studio Code에서 지원하는 플랫폼에 Spark & Hive Tools를 설치할 수 있습니다. 아래에서 다양한 플랫폼의 필수 조건을 확인할 수 있습니다.
사전 요구 사항
이 문서의 단계를 완료하려면 다음 항목이 필요합니다.
- SQL Server 빅 데이터 클러스터. SQL Server 빅 데이터 클러스터을 참조하세요.
- Visual Studio Code
- Visual Studio Code Python 및 Python 확장
- Mono. Mono는 Linux 및 macOS에만 필요합니다.
- Visual Studio Code용 PySpark 대화형 환경 설정
- SQLBDCexample라는 로컬 디렉터리. 이 문서에서는 C:\SQLBDC\SQLBDCexample을 사용합니다.
Spark & Hive Tools 설치
필수 조건을 완료한 후에는 Visual Studio Code용 Spark & Hive Tools를 설치할 수 있습니다. Spark & Hive Tools를 설치하려면 다음 단계를 완료합니다.
Visual Studio Code를 엽니다.
메뉴 모음에서 보기>확장으로 이동합니다.
검색 상자에 Spark & Hive를 입력합니다.
검색 결과에서 Microsoft가 게시한 Spark & Hive Tools를 선택하고 설치를 선택합니다.
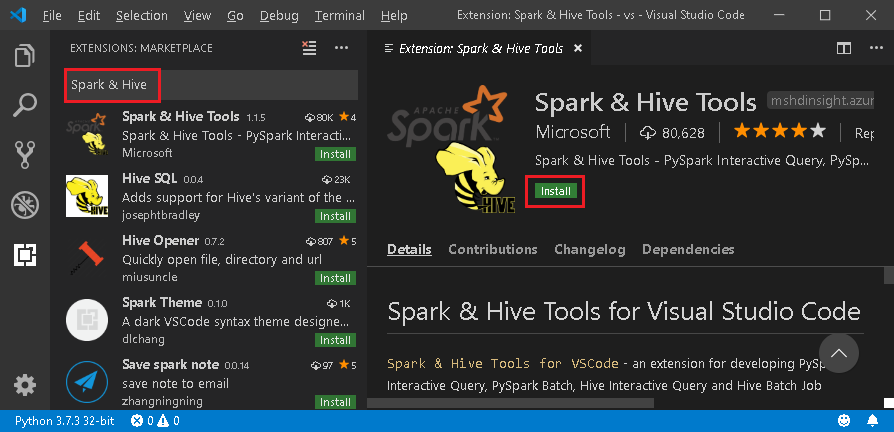
필요한 경우 다시 로드합니다.
작업 폴더 열기
작업 폴더를 열고 Visual Studio Code에서 파일을 만들려면 다음 단계를 완료합니다.
메뉴 모음에서 파일>폴더 열기...>C:\SQLBDC\SQLBDCexample로 이동한 다음, 폴더 선택 단추를 선택합니다. 왼쪽 탐색기 뷰에 폴더가 표시됩니다.
탐색기 뷰에서 폴더, SQLBDCexample을 차례로 선택하고 작업 폴더 옆에 있는 새 파일 아이콘을 선택합니다.
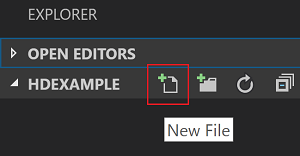
.py(Spark 스크립트) 파일 확장명을 사용하여 새 파일의 이름을 지정합니다. 이 예제에서는 HelloWorld.py를 사용합니다.다음 코드를 복사하여 스크립트 파일에 붙여넣습니다.
import sys from operator import add from pyspark.sql import SparkSession, Row spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() data = [Row(col1='pyspark and spark', col2=1), Row(col1='pyspark', col2=2), Row(col1='spark vs hadoop', col2=2), Row(col1='spark', col2=2), Row(col1='hadoop', col2=2)] df = spark.createDataFrame(data) lines = df.rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) output = counters.collect() sortedCollection = sorted(output, key = lambda r: r[1], reverse = True) for (word, count) in sortedCollection: print("%s: %i" % (word, count))
SQL Server 빅 데이터 클러스터 연결
Visual Studio Code에서 클러스터로 스크립트를 제출하려면 먼저 SQL Server 빅 데이터 클러스터를 연결해야 합니다.
메뉴 모음에서 보기>명령 팔레트... 로 이동한 다음, Spark / Hive: Link a Cluster를 입력합니다.

연결된 클러스터 유형인 SQL Server 빅 데이터를 선택합니다.
SQL Server 빅 데이터 엔드포인트를 입력합니다.
SQL Server 빅 데이터 클러스터 사용자 이름을 입력합니다.
사용자 관리자의 암호를 입력합니다.
빅 데이터 클러스터의 표시 이름을 설정합니다(선택 사항).
클러스터를 나열하고, 확인을 위해 출력 뷰를 검토합니다.
클러스터 나열
메뉴 모음에서 보기>명령 팔레트... 로 이동한 다음, Spark / Hive: List Cluster를 입력합니다.
출력 뷰를 검토합니다. 뷰에는 연결된 클러스터가 표시됩니다.

기본 클러스터 설정
앞서 만든 SQLBDCexample 폴더를 닫은 경우 다시 엽니다.
앞서 만든 HelloWorld.py 파일을 선택하면 스크립트 편집기에서 열립니다.
아직 클러스터를 연결하지 않은 경우 지금 연결합니다.
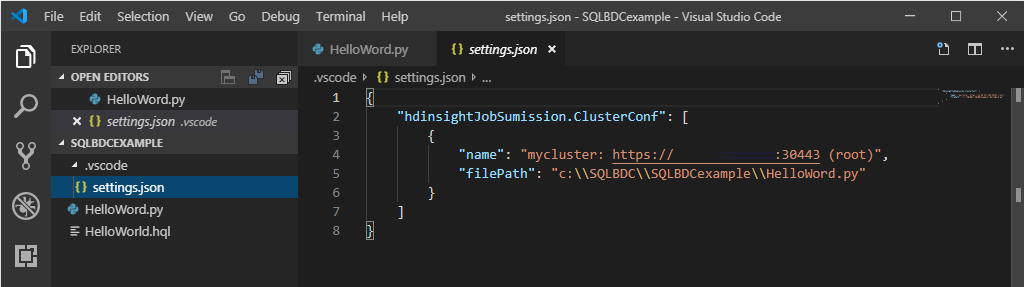
스크립트 편집기를 마우스 오른쪽 단추로 클릭하고 Spark / Hive: Set Default Cluster를 선택합니다.
현재 스크립트 파일의 기본 클러스터로 사용할 클러스터를 선택합니다. 도구가 구성 파일 .VSCode\settings.json을 자동으로 업데이트합니다.
대화형 PySpark 쿼리 제출
다음 단계를 수행하여 대화형 PySpark 쿼리를 제출할 수 있습니다.
앞서 만든 SQLBDCexample 폴더를 닫은 경우 다시 엽니다.
앞서 만든 HelloWorld.py 파일을 선택하면 스크립트 편집기에서 열립니다.
아직 클러스터를 연결하지 않은 경우 지금 연결합니다.
모든 코드를 선택하고 스크립트 편집기를 마우스 오른쪽 단추로 클릭한 다음 Spark: PySpark Interactive를 선택하여 쿼리를 제출하거나 Ctrl + Alt + I 바로 가기를 사용합니다.
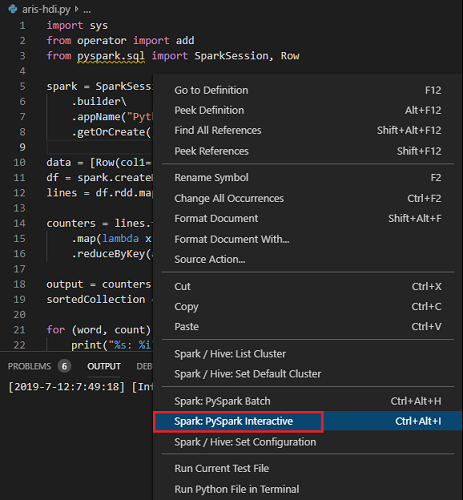
기본 클러스터를 지정하지 않은 경우 클러스터를 선택합니다. 몇 분 후 Python 대화형 결과가 새 탭에 나타납니다. 또한 이 도구를 사용하면 바로 가기 메뉴로 전체 스크립트 파일 대신 코드 블록을 제출할 수 있습니다.
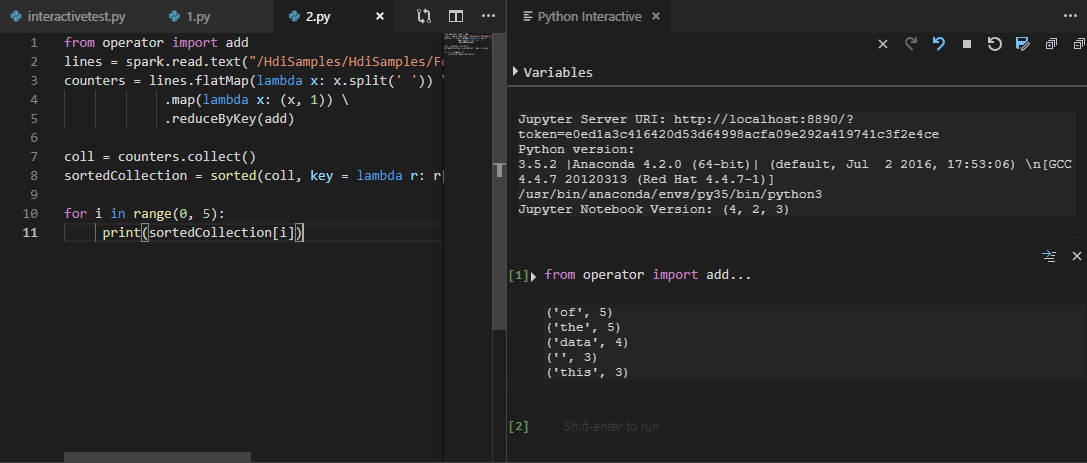
“%% Info”를 입력하고 Shift+Enter를 눌러 작업 정보를 봅니다. (선택 사항)
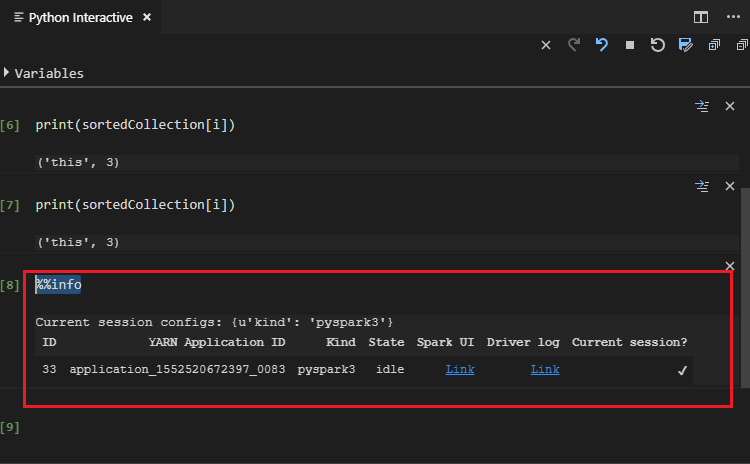
참고 항목
설정에서 Python 확장 사용의 선택을 취소하면(기본 설정은 선택됨), 제출한 pyspark 상호 작용 결과에서 이전 창을 사용합니다.
PySpark 일괄 작업 제출
앞서 만든 SQLBDCexample 폴더를 닫은 경우 다시 엽니다.
앞서 만든 HelloWorld.py 파일을 선택하면 스크립트 편집기에서 열립니다.
아직 클러스터를 연결하지 않은 경우 지금 연결합니다.
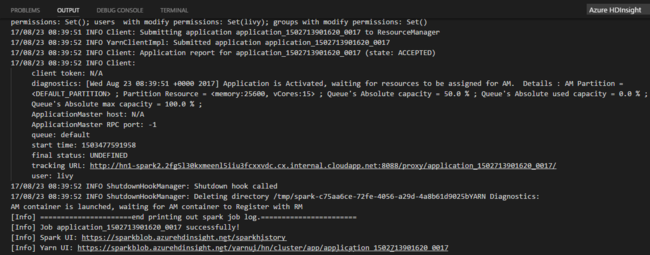
스크립트 편집기를 마우스 오른쪽 단추로 클릭한 후 Spark: PySpark Batch를 선택하거나, 바로 가기 Ctrl+Alt+H를 사용합니다.
기본 클러스터를 지정하지 않은 경우 클러스터를 선택합니다. Python 작업을 제출하면 Visual Studio Code의 출력 창에 제출 로그가 표시됩니다. Spark UI URL 및 Yarn UI URL도 표시됩니다. 웹 브라우저에서 URL을 열어 작업 상태를 추적할 수 있습니다.
Apache Livy 구성
Apache Livy 구성이 지원되며, 작업 영역 폴더에 있는 .VSCode\settings.json에서 설정할 수 있습니다. 현재, Livy 구성은 Python 스크립트만 지원합니다. 자세한 내용은 Livy 추가 정보를 참조하세요.
Livy 구성을 트리거하는 방법
방법 1
- 메뉴 모음에서 파일>기본 설정>설정으로 이동합니다.
- 검색 설정 텍스트 상자에 HDInsight 작업 제출: Livy Conf를 입력합니다.
- 관련 검색 결과에 대해 settings.json에서 편집을 선택합니다.
방법 2
파일을 제출하고, .vscode 폴더가 작업 폴더에 자동으로 추가되는 것을 확인합니다. .vscode 아래에서 settings.json을 클릭해 LIvy 구성을 찾을 수 있습니다.
프로젝트 설정:
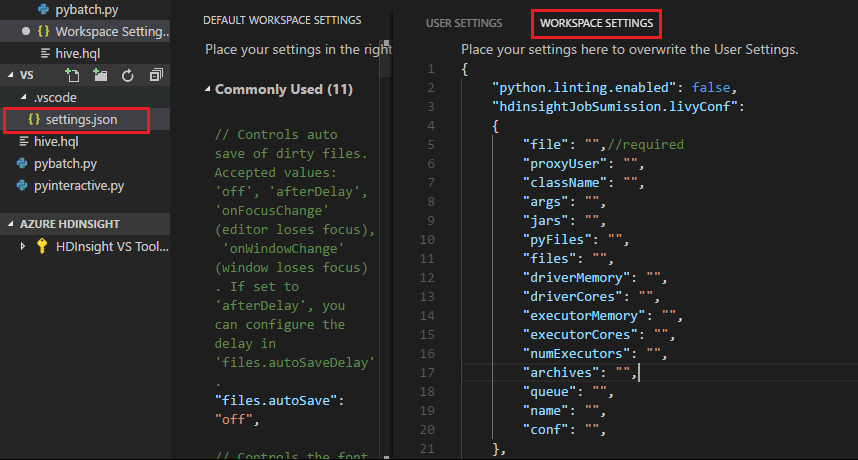
참고 항목
driverMemory 및 executorMemory 설정의 값을 단위와 함께 지정합니다(예:1GB 또는 1024MB).
지원되는 Livy 구성
POST/일괄 처리
요청 본문
| name | description | type |
|---|---|---|
| 파일 | 실행할 애플리케이션이 포함된 파일 | path(필수) |
| proxyUser | 작업을 실행할 때 가장할 사용자 | 문자열 |
| className | 애플리케이션 Java/Spark 주 클래스 | 문자열 |
| args | 애플리케이션의 명령줄 인수 | 문자열 목록 |
| jars | 이 세션에서 사용할 jar | 문자열 목록 |
| pyFiles | 이 세션에서 사용할 Python 파일 | 문자열 목록 |
| files | 이 세션에서 사용할 파일 | 문자열 목록 |
| driverMemory | 드라이버 프로세스에 사용할 메모리 크기 | 문자열 |
| driverCores | 드라이버 프로세스에 사용할 코어 수 | int |
| executorMemory | 실행기 프로세스당 사용할 메모리 크기 | 문자열 |
| executorCores | 각 실행기에 사용할 코어 수 | int |
| numExecutors | 이 세션에서 시작할 실행기 수 | int |
| archives | 이 세션에서 사용할 보관 파일 | 문자열 목록 |
| queue | 제출된 대상 YARN 큐의 이름 | 문자열 |
| name | 이 세션의 이름 | 문자열 |
| conf | Spark 구성 속성 | 키=값 맵 |
| :- | :- | :- |
응답 본문
만든 일괄 처리 개체입니다.
| name | description | type |
|---|---|---|
| id | 세션 ID | int |
| appId | 이 세션의 애플리케이션 ID | String |
| appInfo | 자세한 애플리케이션 정보 | 키=값 맵 |
| log | 로그 줄 | 문자열 목록 |
| state | 일괄 처리 상태 | 문자열 |
| :- | :- | :- |
참고
할당된 Livy 구성은 스크립트를 제출할 때 출력 창에 표시됩니다.
추가 기능
Visual Studio Code용 Spark & Hive는 다음과 같은 기능을 지원합니다.
IntelliSense 자동 완성. 키워드, 메서드, 변수 등에 대한 제안이 팝업됩니다. 아이콘마다 다른 형식의 개체를 나타냅니다.
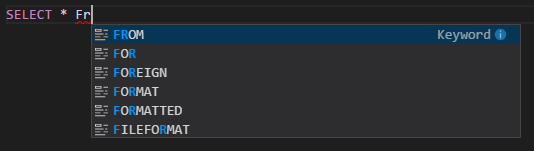
IntelliSense 오류 표식. 언어 서비스는 Hive 스크립트의 편집 오류에 밑줄을 긋습니다.
구문 강조 표시. 언어 서비스는 변수, 키워드, 데이터 형식, 함수 등을 구분하기 위해 각기 다른 색을 사용합니다.
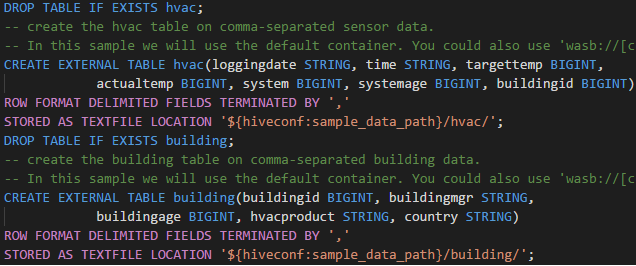
클러스터 연결 해제
메뉴 모음에서 보기>명령 팔레트로 이동한 다음, Spark / Hive: Unlink a Cluster를 입력합니다.
연결을 해제할 클러스터를 선택합니다.
확인을 위해 출력 뷰를 검토합니다.
다음 단계
SQL Server 빅 데이터 클러스터 및 관련 시나리오에 대한 자세한 내용은 SQL Server 빅 데이터 클러스터를 참조하세요.