다른 저장소에서 데이터 모델 직렬화(미리 보기)
데이터 모델을 데이터베이스에 저장하려면 데이터베이스에서 이해할 수 있는 형식으로 변환해야 합니다. 다른 데이터베이스에는 서로 다른 스토리지 스키마와 형식이 필요합니다. 일부 스키마에는 준수해야 하는 엄격한 스키마가 있는 반면, 다른 스키마는 사용자가 스키마를 정의할 수 있도록 허용합니다.
매핑 옵션
의미 체계 커널에서 제공하는 벡터 저장소 커넥터는 이 매핑을 달성하는 여러 가지 방법을 제공합니다.
기본 제공 매퍼
의미 체계 커널에서 제공하는 벡터 저장소 커넥터에는 데이터베이스 스키마와 데이터 모델을 매핑하는 기본 제공 매퍼가 포함되어 있습니다. 기본 제공 매퍼가 각 데이터베이스에 대한 데이터를 매핑하는 방법에 대한 자세한 내용은 각 커넥터 대한
사용자 지정 매퍼
의미 체계 커널에서 제공하는 벡터 저장소 커넥터는 VectorStoreRecordDefinition와 함께 사용자 지정 매퍼를 제공할 수 있는 기능을 지원합니다. 이 경우 VectorStoreRecordDefinition 제공된 데이터 모델과 다를 수 있습니다.
VectorStoreRecordDefinition 데이터베이스 스키마를 정의하는 데 사용되며, 개발자는 데이터 모델을 사용하여 벡터 저장소와 상호 작용합니다.
이 경우 데이터 모델에서 VectorStoreRecordDefinition정의된 사용자 지정 데이터베이스 스키마로 매핑하려면 사용자 지정 매퍼가 필요합니다.
팁
사용자 지정 매퍼를 만드는 방법에 대한 예제로는 Vector Store 커넥터에 대한 사용자 지정 매퍼를 만드는 방법을 참조하세요.
클래스 또는 정의로 정의된 데이터 모델을 데이터베이스에 저장하려면 데이터베이스에서 이해할 수 있는 형식으로 직렬화해야 합니다.
의미 체계 커널에서 제공하는 기본 제공 serialization을 사용하거나 고유한 serialization 논리를 제공하여 두 가지 방법으로 수행할 수 있습니다.
다음 두 다이어그램은 저장소 모델 간 데이터 모델의 직렬화 및 역직렬화에 대해 흐름이 표시되는 것을 보여 줍니다.
Serialization Flow(Upsert에서 사용됨)

역직렬화 흐름(가져오기 및 검색에 사용됨)
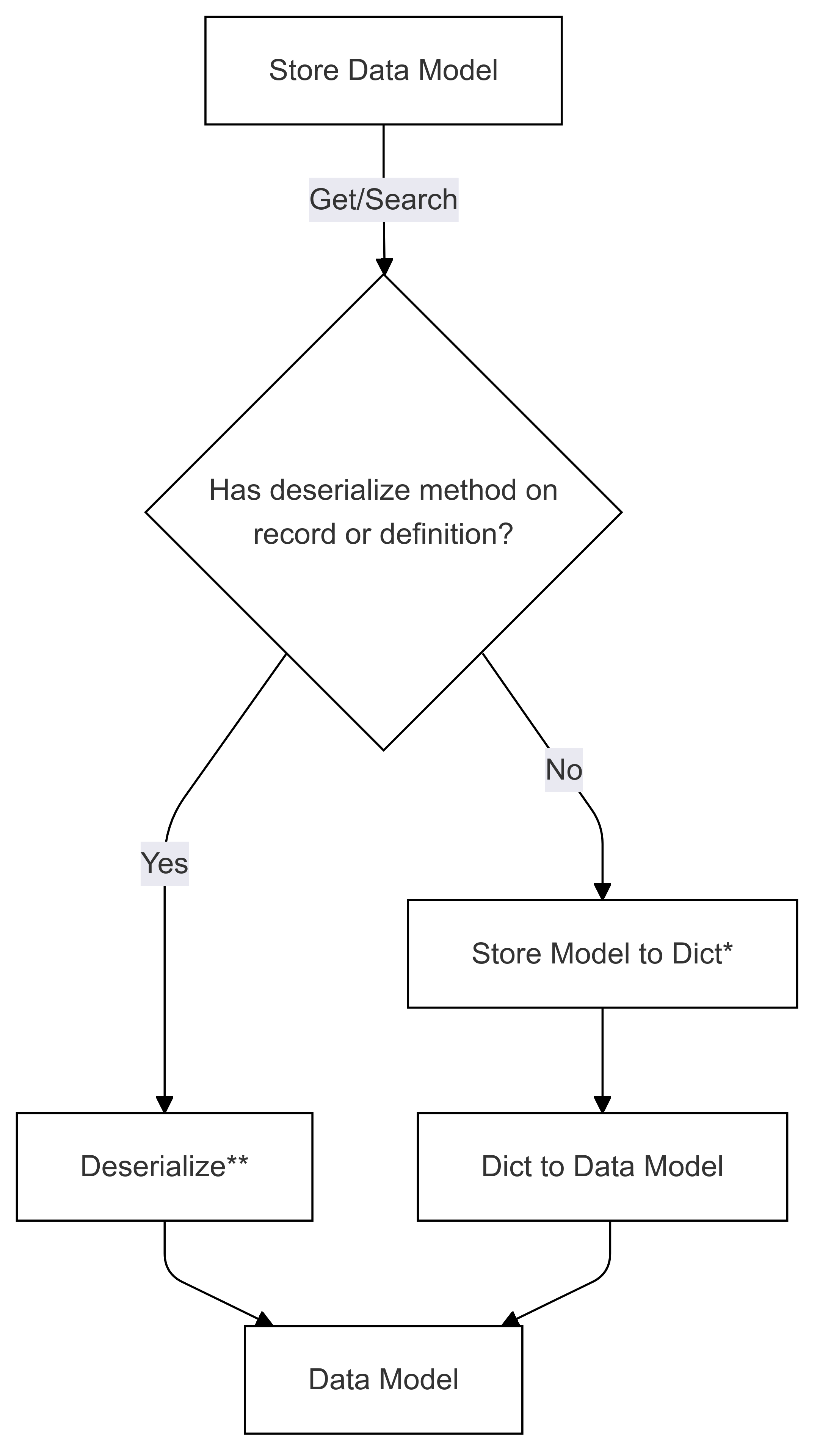
*(두 다이어그램 모두)로 표시된 단계는 특정 커넥터의 개발자가 구현하며 각 저장소마다 다릅니다. **로 표시된 단계(두 다이어그램 모두)는 레코드의 메서드 또는 레코드 정의의 일부로 제공되며, 이는 항상 사용자가 제공합니다. 자세한 내용은 직접 직렬화 참조하세요.
직렬화 및 역직렬화 접근 방식
데이터 모델에서 저장 모델로의 직접 직렬화
직접 직렬화는 모델이 직렬화되는 방법을 완전히 제어하고 성능을 최적화하는 가장 좋은 방법입니다. 단점은 데이터 저장소와 관련이 있으므로 이를 사용하는 경우 동일한 데이터 모델을 사용하는 다른 저장소 간에 전환하기가 쉽지 않다는 것입니다.
데이터 모델에서 SerializeMethodProtocol 프로토콜을 따르는 메서드를 구현하거나 SerializeFunctionProtocol 따르는 함수를 레코드 정의에 추가하여 이를 사용할 수 있습니다. 둘 다 semantic_kernel/data/vector_store_model_protocols.py찾을 수 있습니다.
이러한 함수 중 하나가 있으면 데이터 모델을 저장소 모델로 직접 직렬화하는 데 사용됩니다.
둘 중 하나만 구현하고 다른 방향으로는 기본 제공 직렬화 또는 역직렬화를 사용할 수 있습니다. 예를 들어, 제어할 수 없는 외부에서 생성된 컬렉션을 처리해야 할 때 이것이 유용할 수 있습니다. 이 경우 역직렬화 방식을 사용자 지정해야 할 수도 있고, 어쨌든 upsert는 수행할 수 없습니다.
기본 제공 (디)시리얼라이제이션 기능(데이터 모델을 Dict로, Dict를 Store 모델로, 및 그 반대로 변환 가능)
기본 제공 serialization은 먼저 데이터 모델을 사전으로 변환한 다음, 기본 제공 커넥터의 일부로 서로 다르고 정의된 각 저장소에 대해 저장소가 이해하는 모델로 직렬화하여 수행됩니다. 역직렬화는 역순으로 수행됩니다.
직렬화 단계 1: 데이터 모델을 딕셔너리로 변환
데이터 모델의 종류에 따라 단계가 서로 다른 방식으로 수행됩니다. 데이터 모델을 사전으로 직렬화하는 네 가지 방법이 있습니다.
- 정의에 따른
to_dict메서드(이것은ToDictFunctionProtocol을 따라 데이터 모델의 to_dict 특성에 맞춥니다.) - 레코드가
ToDictMethodProtocol있는지 확인하고to_dict메서드를 사용합니다. - 레코드가 Pydantic 모델인지 확인한 후 모델의
model_dump을 사용하세요. 자세한 내용은 아래 주석을 참조하세요. - 정의의 필드를 반복 처리하고 사전을 생성합니다.
모델을 저장할 딕셔너리: 직렬화 2단계
사전을 저장소 모델로 변환하기 위해 커넥터에서 메서드를 제공해야 합니다. 이 작업은 커넥터 개발자가 수행하며 각 저장소마다 다릅니다.
역직렬화 1단계: Dict에 모델 저장
저장소 모델을 사전으로 변환하기 위해 커넥터에서 메서드를 제공해야 합니다. 이 작업은 커넥터 개발자가 수행하며 각 저장소마다 다릅니다.
역직렬화 2단계: Dict를 데이터 모델로 변환
역직렬화는 역순으로 수행되며 다음 옵션을 시도합니다.
- 데이터 모델의 from_dict 속성에 맞춰 정의된
from_dict메서드(FromDictFunctionProtocol을 따름) - 레코드가
FromDictMethodProtocol있는지 확인하고from_dict메서드를 사용합니다. - 레코드가 Pydantic 모델인지 확인하고 모델의
model_validate을 사용하십시오. 자세한 내용은 아래 주석을 참조하세요. - 정의의 필드를 반복하여 값을 설정한 후, 이 딕셔너리는 명명된 인수로서 데이터 모델의 생성자에 전달됩니다. 만약 데이터 모델 자체가 딕셔너리라면, 그대로 반환됩니다.
메모
기본 제공 serialization 기능과 함께 Pydantic 사용
Pydantic BaseModel을 사용하여 모델을 정의하면 데이터 모델을 직렬화하고 받아쓰기에서 역직렬화하는 데 해당 모델과 model_dump 메서드를 사용합니다model_validate. 이 작업은 매개 변수를 사용하지 않고 model_dump 메서드를 사용하여 수행됩니다. 이 동작을 제어하고 싶다면, 데이터 모델에서 ToDictMethodProtocol을 구현하는 것을 고려하십시오. 이는 가장 먼저 검토되기 때문입니다.
벡터 직렬화
데이터 모델에 벡터가 있는 경우 대부분의 저장소에 필요한 항목이므로 부동 소수점 목록이나 ints 목록이어야 합니다. 클래스에서 벡터를 다른 형식으로 저장하려는 경우 주석에 serialize_function 정의하고 deserialize_function 사용할 VectorStoreRecordVectorField 수 있습니다. 예를 들어 numpy 배열의 경우 다음 주석을 사용할 수 있습니다.
import numpy as np
vector: Annotated[
np.ndarray | None,
VectorStoreRecordVectorField(
dimensions=1536,
serialize_function=np.ndarray.tolist,
deserialize_function=np.array,
),
] = None
네이티브 numpy 배열을 처리할 수 있는 벡터 저장소를 사용하고 그 배열이 계속 변환되지 않도록 하려면, 모델과 저장소에 대한 직접 직렬화 및 역직렬화 메서드를 설정해야 합니다.
메모
이는 기본 제공 serialization을 사용하는 경우에만 사용되며 직접 serialization을 사용하는 경우 원하는 방식으로 벡터를 처리할 수 있습니다.
서비스 예정
추가 정보는 곧 제공될 예정입니다.