Azure Table Storage에 대한 확장 가능한 분할 전략 설계
이 문서에서는 Azure Table Storage에서 테이블을 분할하고 효율적인 확장성을 보장하는 데 사용할 수 있는 전략에 대해 설명합니다.
Azure는 고가용성 및 확장성이 뛰어난 클라우드 스토리지를 제공합니다. Azure용 기본 스토리지 시스템은 Azure Blob Storage, Azure Table Storage, Azure Queue Storage 및 Azure Files 비롯한 일련의 서비스를 통해 제공됩니다.
Azure Table Storage는 구조화된 데이터를 저장하도록 설계되었습니다. Azure Storage 서비스는 무제한의 테이블을 지원합니다. 각 테이블은 대규모 수준으로 스케일링하고 테라바이트의 물리적 스토리지를 제공할 수 있습니다. 테이블을 최대한 활용하려면 데이터를 최적으로 분할해야 합니다. 이 문서에서는 Azure Table Storage에 대한 데이터를 효율적으로 분할하는 데 사용할 수 있는 전략을 살펴봅니다.
테이블 엔터티
테이블 엔터티는 테이블에 저장된 데이터 단위를 나타냅니다. 테이블 엔터티는 일반적인 관계형 데이터베이스 테이블의 행과 비슷합니다. 각 엔터티는 속성의 컬렉션을 정의합니다. 각 속성은 이름, 값 및 값의 데이터 형식으로 키/값 쌍으로 정의됩니다. 엔터티는 속성 컬렉션의 일부로 다음과 같은 3개의 시스템 속성을 정의해야 합니다.
PartitionKey: PartitionKey 속성은 엔터티가 속한 파티션을 식별하는 문자열 값을 저장합니다. 나중에 설명한 것처럼 파티션은 테이블의 확장성에 필수적입니다. PartitionKey 값이 동일한 엔터티는 동일한 파티션에 저장됩니다.
RowKey: RowKey 속성은 각 파티션 내에서 엔터티를 고유하게 식별하는 문자열 값을 저장합니다. PartitionKey와 RowKey는 함께 엔터티의 기본 키를 형성합니다.
타임스탬프: Timestamp 속성은 엔터티에 대한 추적 기능을 제공합니다. 타임스탬프는 엔터티가 마지막으로 수정된 시간을 알려주는 날짜/시간 값입니다. 타임스탬프를 엔터티 의 버전이라고도 합니다. 테이블 서비스가 모든 삽입 및 업데이트 작업 중에 이 속성의 값을 유지 관리하므로 타임스탬프 수정은 무시됩니다.
테이블 기본 키
Azure 엔터티의 기본 키는 결합된 PartitionKey 및 RowKey 속성으로 구성됩니다. 두 속성은 테이블 내에서 단일 클러스터형 인덱스 형식입니다. PartitionKey 및 RowKey 값의 크기는 최대 1024자입니다. 빈 문자열도 허용됩니다. 그러나 null 값은 허용되지 않습니다.
클러스터형 인덱스 는 PartitionKey 를 오름차순으로 정렬한 다음 RowKey 를 오름차순으로 정렬합니다. 정렬 순서는 모든 쿼리 응답에서 유지됩니다. 정렬 작업 중 어휘 비교가 사용됩니다. 문자열 값 "111"이 문자열 값 "2" 앞에 나타납니다. 경우에 따라 정렬 순서를 숫자로 지정할 수 있습니다. 숫자 및 오름차순으로 정렬하려면 고정 길이인 0패딩 문자열을 사용해야 합니다. 앞의 예제에서는 "002"가 "111" 앞에 나타납니다.
테이블 파티션
파티션은 동일한 PartitionKey 값을 가진 엔터티의 컬렉션을 나타냅니다. 파티션은 항상 하나의 파티션 서버에서 제공됩니다. 각 파티션 서버는 하나 이상의 파티션을 제공할 수 있습니다. 분할 서버에는 시간 경과에 따라 한 분할에서 제공할 수 있는 엔터티의 수에 대한 비율 제한이 있습니다. 특히 파티션의 확장성 목표는 초당 2,000개 엔터티입니다. 이 처리량은 스토리지 노드에서 최소 로드 중에 더 높을 수 있지만 노드가 핫 또는 활성 상태가 되면 제한됩니다.
분할 개념을 더 잘 설명하기 위해 다음 그림에서는 풋 레이스 이벤트 등록을 위한 작은 데이터 하위 집합이 포함된 테이블을 보여 줍니다. 이 그림에서는 PartitionKey 에 세 개의 서로 다른 값이 포함된 분할의 개념적 보기를 제공합니다. 이벤트의 이름은 세 거리(전체 마라톤, 하프 마라톤 및 10km)와 결합됩니다. 이 예제에서는 두 개의 파티션 서버를 사용합니다. 서버 A에는 하프 마라톤 및 10km 거리에 대한 등록이 포함되어 있습니다. 서버 B에는 전체 마라톤 거리만 포함됩니다. RowKey 값은 컨텍스트를 제공하는 것으로 표시되지만 이 예제에서는 값이 의미가 없습니다.
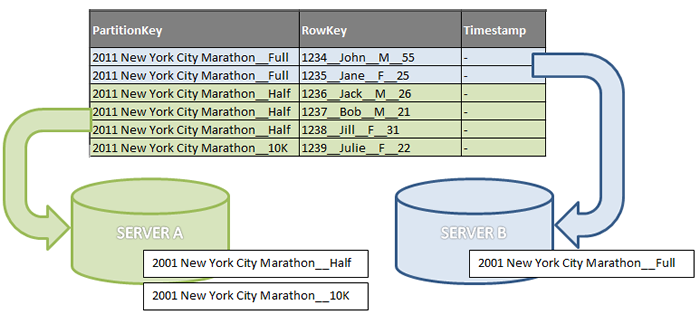
3개의 분할이 있는 테이블
확장성
분할은 항상 단일 분할 서버에서 제공되며 각 분할 서버는 하나 이상의 분할을 제공할 수 있으므로, 제공되는 엔터티의 효율성은 서버의 상태와 관련됩니다. 파티션에 대한 트래픽이 많은 서버는 높은 처리량을 유지하지 못할 수 있습니다. 예를 들어 앞의 그림에서 "2011 뉴욕시 Marathon__Half"에 대한 많은 요청이 수신되면 서버 A가 너무 뜨거워질 수 있습니다. 서버의 처리량을 늘리기 위해 저장소 시스템에서 분할의 부하를 다른 서버로 분산합니다. 그 결과, 트래픽이 다른 많은 서버에 분산됩니다. 트래픽 부하 분산을 최적화하려면 Azure Table Storage에서 파티션을 더 많은 파티션 서버에 배포할 수 있도록 더 많은 파티션을 사용해야 합니다.
엔터티 그룹 트랜잭션
엔터티 그룹 트랜잭션은 PartitionKey 값이 동일한 엔터티에서 원자성으로 구현되는 스토리지 작업 집합입니다. 엔터티 그룹의 스토리지 작업이 실패하면 엔터티의 모든 스토리지 작업이 롤백됩니다. 엔터티 그룹 트랜잭션은 100개 이하의 스토리지 작업으로 구성되며 크기가 4MiB 이하일 수 있습니다. 엔터티 그룹 트랜잭션은 관계형 데이터베이스에서 제공하는 ACID(원자성, 일관성, 격리 및 내구성) 의미 체계의 제한된 형식으로 Azure Table Storage를 제공합니다.
엔터티 그룹 트랜잭션은 Azure Table Storage에 제출해야 하는 개별 스토리지 작업의 수를 줄이기 때문에 처리량을 향상시킵니다. 엔터티 그룹 트랜잭션은 경제적 이익도 제공합니다. 엔터티 그룹 트랜잭션은 포함된 스토리지 작업 수에 관계없이 단일 스토리지 작업으로 청구됩니다. 엔터티 그룹 트랜잭션의 모든 스토리지 작업은 동일한 PartitionKey 값을 가진 엔터티에 영향을 주므로 엔터티 그룹 트랜잭션을 사용해야 하므로 PartitionKey 값을 선택할 수 있습니다.
범위 파티션
엔터티에 고유한 PartitionKey 값을 사용하는 경우 각 엔터티는 자체 파티션에 속합니다. 사용하는 고유 값이 값을 늘리거나 줄이면 Azure에서 범위 파티션을 만들 수 있습니다. 범위 파티션은 순차적인 고유한 PartitionKey 값이 있는 엔터티를 그룹화하여 범위 쿼리의 성능을 향상시킵니다. 범위 파티션이 없으면 범위 쿼리가 파티션 경계 또는 서버 경계를 넘어야 하므로 쿼리 성능이 저하됩니다. PartitionKey에 대한 시퀀스 값이 증가하는 다음 표를 사용하는 애플리케이션을 고려합니다.
| PartitionKey | RowKey |
|---|---|
| "0001" | - |
| "0002" | - |
| "0003" | - |
| "0004" | - |
| "0005" | - |
| "0006" | - |
Azure는 처음 세 엔터티를 범위 파티션으로 그룹화할 수 있습니다. PartitionKey를 조건으로 사용하고 엔터티를 "0001"에서 "0003"으로 요청하는 테이블에 범위 쿼리를 적용하면 엔터티가 단일 파티션 서버에서 제공되기 때문에 쿼리가 효율적으로 수행될 수 있습니다. 범위 파티션을 만드는 시기와 방법은 보장되지 않습니다.
PartitionKey 값이 증가하거나 감소하는 엔터티를 삽입하는 경우 테이블에 대한 범위 파티션이 있으면 삽입 작업의 성능에 영향을 줄 수 있습니다. PartitionKey 값이 증가하는 엔터티를 삽입하는 것을 추가 전용 패턴이라고 합니다. 값이 줄어드는 엔터티를 삽입하는 것을 앞에 추가 전용 패턴이라고 합니다. 삽입 요청의 전체 처리량이 단일 파티션 서버에 의해 제한되므로 이러한 종류의 패턴을 사용하지 않는 것이 좋습니다. 범위 파티션이 있는 경우 첫 번째 파티션과 마지막(범위) 파티션에는 각각 가장 적은 PartitionKey 값과 가장 큰 PartitionKey 값이 포함되어 있기 때문입니다. 따라서 PartitionKey 값이 순차적으로 낮거나 높은 새 엔터티의 삽입은 최종 파티션 중 하나를 대상으로 합니다. 다음 그림에서는 앞의 예제를 기반으로 하는 범위 파티션의 가능한 집합을 보여 줍니다. "0007", "0008" 및 "0009" 엔터티 집합이 삽입된 경우 마지막(주황색) 파티션에 할당됩니다.
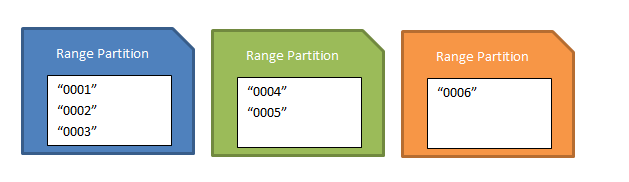
범위 파티션 집합
삽입 작업에서 더 분산된 PartitionKey 값을 사용하는 경우 성능에 부정적인 영향이 없다는 점에 유의해야 합니다.
데이터 분석
인덱스를 관리하는 데 사용할 수 있는 관계형 데이터베이스의 테이블과 달리 Azure Table Storage의 테이블에는 하나의 인덱스만 있을 수 있습니다. Azure Table Storage의 인덱스는 항상 PartitionKey 및 RowKey 속성으로 구성됩니다.
Azure 테이블에서는 인덱스를 더 추가하거나 롤아웃한 후 기존 테이블을 변경하여 테이블을 성능 튜닝할 필요가 없습니다. 테이블을 디자인할 때 데이터를 분석해야 합니다. 최적의 확장성과 쿼리 및 삽입 효율성을 위해 고려해야 할 가장 중요한 측면은 PartitionKey 및 RowKey 값입니다. 이 문서에서는 테이블 분할 방식과 직접 관련이 있으므로 PartitionKey 를 선택하는 방법을 강조합니다.
파티션 크기 조정
분할 크기 조정은 분할에 포함된 엔터티 수를 나타냅니다. 확장성에서 설명한 대로 파티션이 더 많으면 부하 분산이 향상됩니다. PartitionKey 값의 세분성은 파티션의 크기에 영향을 줍니다. 가장 거친 수준에서 단일 값이 PartitionKey로 사용되는 경우 모든 엔터티는 매우 큰 단일 파티션에 있습니다. 가장 세분성 수준에서 PartitionKey 는 각 엔터티에 대한 고유 값을 포함할 수 있습니다. 결과적으로 각 엔터티에 대한 파티션이 있습니다. 다음 표에서는 세분성 범위의 장점과 단점을 보여 줍니다.
| PartitionKey 세분성 | 파티션 크기 | 장점 | 단점 |
|---|---|---|---|
| 단일 값 | 적은 엔터티 수 | 일괄 처리 트랜잭션은 모든 엔터티에서 가능합니다. 모든 엔터티는 로컬이며 동일한 스토리지 노드에서 제공됩니다. |
|
| 단일 값 | 많은 엔터티 수 | 엔터티 그룹 트랜잭션은 모든 엔터티에서 가능할 수 있습니다. 엔터티 그룹 트랜잭션의 제한에 대한 자세한 내용은 엔터티 그룹 트랜잭션 수행을 참조하세요. | 크기 조정은 제한됩니다. 처리량은 단일 서버의 성능으로 제한됩니다. |
| 다중 값 | 여러 파티션 파티션 크기는 엔터티 배포에 따라 달라집니다. |
일괄 처리 트랜잭션은 일부 엔터티에서 가능합니다. 동적 분할이 가능합니다. 단일 요청 쿼리가 가능합니다(연속 토큰 없음). 더 많은 파티션 서버에서 부하 분산이 가능합니다. |
파티션 간에 엔터티를 고르지 않게 분산하면 더 크고 더 많은 활성 파티션의 성능이 제한될 수 있습니다. |
| 고유한 값 | 많은 작은 파티션 | 테이블은 확장성이 높습니다. 범위 파티션은 파티션 간 범위 쿼리의 성능을 향상시킬 수 있습니다. |
범위가 포함된 쿼리에는 둘 이상의 서버를 방문해야 할 수 있습니다. 일괄 처리 트랜잭션이 가능하지 않습니다. 추가 전용 또는 추가 전용 패턴은 삽입 처리량에 영향을 줄 수 있습니다. |
이 표에서는 PartitionKey 값의 크기 조정에 영향을 미치는 방법을 보여줍니다. 더 나은 부하 분산을 제공하기 때문에 더 작은 파티션을 선호하는 것이 가장 좋습니다. 일부 시나리오에서는 큰 파티션이 적절할 수 있으며 반드시 불리한 것은 아닙니다. 예를 들어 애플리케이션에 확장성이 필요하지 않은 경우 단일 큰 파티션이 적절할 수 있습니다.
쿼리 확인
쿼리는 테이블에서 데이터를 검색합니다. Azure Table Storage의 테이블에 대한 데이터를 분석하는 경우 애플리케이션에서 사용할 쿼리를 고려하는 것이 중요합니다. 애플리케이션에 여러 쿼리가 있는 경우 의사 결정이 주관적일 수 있지만 우선 순위를 지정해야 할 수 있습니다. 대부분의 경우 주요 쿼리는 다른 쿼리에서 식별할 수 있습니다. 성능의 측면에서 쿼리는 여러 범주로 나뉩니다. 테이블에 인덱스가 하나만 있으므로 쿼리 성능은 일반적으로 PartitionKey 및 RowKey 속성과 관련이 있습니다. 다음 표에서는 다양한 유형의 쿼리와 해당 성능 등급을 보여 줍니다.
| 쿼리 유형 | PartitionKey 일치 | RowKey 일치 | 성능 등급 |
|---|---|---|---|
| 행 범위 검색 | Exact | Partial | 더 작은 크기의 파티션을 사용하는 것이 좋습니다. 파티션이 매우 큰 경우 잘못되었습니다. |
| 분할 범위 검색 | Partial | Partial | 적은 수의 파티션 서버가 터치되는 것이 좋습니다. 더 많은 서버가 터치되는 더 나쁜. |
| 전체 테이블 검색 | 부분적으로 일치, 없음 | 부분적으로 일치, 없음 | 더 나쁜 것은 파티션의 하위 집합이 검사되는 경우입니다. 모든 파티션이 검사되는 최악의 경우. |
참고
테이블은 서로 상대적인 성능 등급을 정의합니다. 파티션의 수와 크기는 궁극적으로 쿼리의 성능을 결정할 수 있습니다. 예를 들어 큰 파티션이 많은 테이블에 대한 파티션 범위 검색은 몇 개의 작은 파티션이 있는 테이블에 대한 전체 테이블 검색에 비해 성능이 저하될 수 있습니다.
앞의 표에 나열된 쿼리 형식은 성능 등급에 따라 사용할 최상의 쿼리 유형에서 최악의 형식으로의 진행률을 보여 줍니다. 지점 쿼리는 테이블의 클러스터형 인덱스를 완벽하게 사용하므로, 사용할 수 있는 최상의 쿼리 유형입니다. 다음 지점 쿼리는 Foot races 등록 테이블의 데이터를 사용합니다.
http://<account>.windows.core.net/registrations(PartitionKey=”2011 New York City Marathon__Full”,RowKey=”1234__John__M__55”)
응용 프로그램에서 여러 쿼리를 사용하는 경우 일부는 지점 쿼리가 될 수 있습니다. 성능의 측면에서 범위 쿼리는 지점 쿼리보다 낮습니다. 범위 쿼리에는 행 범위 검색과 파티션 범위 검색의 두 가지 유형이 있습니다. 행 범위 검색은 단일 분할을 지정합니다. 작업은 단일 파티션 서버에서 발생하기 때문에 행 범위 검사는 일반적으로 파티션 범위 검사보다 더 효율적입니다. 그러나 행 범위 검색 성능의 핵심 요소는 쿼리가 얼마나 선택적인지입니다. 쿼리 선택도는 일치하는 행을 찾기 위해 반복해야 하는 행 수를 지정합니다. 선택적인 쿼리가 많아질수록 행 범위 검색 중 효율성이 높아집니다.
쿼리의 우선 순위를 평가하려면 각 쿼리에 대한 빈도 및 응답 시간 요구 사항을 고려합니다. 자주 실행되는 쿼리의 우선 순위는 더 높을 수 있습니다. 그러나 중요하지만 거의 사용되지 않는 쿼리에는 대기 시간이 짧아 우선 순위 목록에서 더 높은 순위가 지정될 수 있습니다.
PartitionKey 값 선택
테이블 디자인의 핵심은 확장성, 액세스에 사용되는 쿼리 및 스토리지 작업 요구 사항입니다. 선택한 PartitionKey 값은 테이블이 분할되는 방식과 사용할 수 있는 쿼리 유형을 나타냅니다. 스토리지 작업, 특히 삽입은 PartitionKey 값 선택에 영향을 줄 수도 있습니다. PartitionKey 값은 단일 값에서 고유 값까지 다양할 수 있습니다. 여러 값을 사용하여 만들 수도 있습니다. 엔터티 속성을 사용하여 PartitionKey 값을 형성할 수 있습니다. 또는 애플리케이션에서 값을 계산할 수 있습니다. 다음 섹션에서는 중요한 고려 사항에 대해 설명합니다.
엔터티 그룹 트랜잭션
개발자는 먼저 애플리케이션이 엔터티 그룹 트랜잭션(일괄 업데이트)을 사용할지 여부를 고려해야 합니다. 엔터티 그룹 트랜잭션을 사용하려면 엔터티에 동일한 PartitionKey 값이 있어야 합니다. 또한 일괄 업데이트는 전체 그룹에 대한 업데이트이므로 PartitionKey 값 선택 항목이 제한될 수 있습니다. 예를 들어 현금 거래를 유지 관리하는 은행 응용 프로그램은 테이블에 현금 거래를 자동으로 삽입해야 합니다. 현금 거래는 직불 및 신용 측면을 모두 나타내며 0으로 순매수해야 합니다. 이 요구 사항은 트랜잭션의 각 쪽이 서로 다른 계정 번호를 사용하기 때문에 계정 번호를 PartitionKey 값의 일부로 사용할 수 없음을 의미합니다. 대신 트랜잭션 ID가 더 나은 선택일 수 있습니다.
파티션
파티션 번호와 크기는 로드 중인 테이블의 확장성에 영향을 줍니다. 또한 PartitionKey 값이 얼마나 세분화되었는지에 따라 제어됩니다. 파티션 크기에 따라 PartitionKey 를 결정하는 것은 어려울 수 있습니다. 특히 값의 분포를 예측하기 어려운 경우 그렇습니다. 가장 좋은 방법은 작은 분할을 여러 개 사용하는 것입니다. 많은 테이블 파티션을 사용하면 Azure Table Storage에서 파티션이 제공되는 스토리지 노드를 더 쉽게 관리할 수 있습니다.
PartitionKey에 대해 고유하거나 더 미세한 값을 선택하면 파티션이 더 작지만 더 많이 생성됩니다. 시스템이 많은 파티션의 부하를 분산하여 많은 파티션에 부하를 분산할 수 있기 때문에 일반적으로 유리합니다. 그러나 많은 분할이 분할 간 범위 쿼리에 미치는 영향을 고려해야 합니다. 이러한 유형의 쿼리는 쿼리를 충족하려면 여러 파티션을 방문해야 합니다. 파티션이 여러 파티션 서버에 분산될 수 있습니다. 쿼리가 서버 경계에 걸쳐 있는 경우 연속 토큰이 반환되어야 합니다. 연속 토큰은 다음 PartitionKey 또는 RowKey 값을 지정하여 쿼리에 대한 다음 데이터 집합을 검색합니다. 즉, 연속 토큰은 서비스에 대한 요청을 하나 이상 나타내며 이는 쿼리의 전반적인 성능을 저하시킬 수 있습니다.
쿼리 선택도는 쿼리의 성능에 영향을 줄 수 있는 또 다른 요인입니다. 쿼리 선택도는 각 분할에 대해 반복해야 하는 행 수의 측정치입니다. 쿼리가 선택적일수록 쿼리가 원하는 행을 반환하는 데 더 효율적입니다. 범위 쿼리의 전반적인 성능은 터치해야 하는 파티션 서버의 수 또는 쿼리가 얼마나 선택적인지에 따라 달라질 수 있습니다. 또한 테이블에 데이터를 삽입할 때는 추가 전용 또는 추가 전용 패턴을 사용하지 않아야 합니다. 이러한 패턴을 사용하는 경우 작은 파티션과 많은 파티션을 만들더라도 삽입 작업의 처리량을 제한할 수 있습니다. 추가 전용 및 추가 전용 패턴은 범위 파티션에서 설명합니다.
쿼리
사용할 쿼리를 알면 PartitionKey 값에 대해 고려해야 할 속성을 결정하는 데 도움이 될 수 있습니다. 쿼리에서 사용하는 속성은 PartitionKey 값의 후보입니다. 다음 표에서는 PartitionKey 값을 확인하는 방법에 대한 일반적인 지침을 제공합니다.
| 엔터티가 다음과 같은 경우 | 작업 |
|---|---|
| 키 속성을 하나 포함 | PartitionKey로 사용합니다. |
| 키 속성을 두 개 포함 | 하나를 PartitionKey 로 사용하고 다른 하나는 RowKey로 사용합니다. |
| 키 속성을 두 개 이상 포함 | 연결된 값의 복합 키를 사용합니다. |
동일한 기준 쿼리가 두 개 이상 있는 경우 필요한 다른 RowKey 값을 사용하여 정보를 여러 번 삽입할 수 있습니다. 애플리케이션은 보조(또는 3차 등) 행을 관리합니다. 이러한 유형의 패턴을 사용하여 쿼리의 성능 요구 사항을 충족할 수 있습니다. 다음 예제에서는 풋 레이스 등록 예제의 데이터를 사용합니다. 다음과 같은 두 가지 주요 쿼리가 있습니다.
- 참가번호로 쿼리
- 연령으로 쿼리
두 가지 중요 쿼리를 모두 제공하려면 두 행을 엔터티 그룹 트랜잭션으로 삽입하세요. 다음 표에서는 이 시나리오에 대한 PartitionKey 및 RowKey 속성을 보여줍니다. RowKey 값은 애플리케이션이 두 값을 구분할 수 있도록 턱받이와 나이의 접두사를 제공합니다.
| PartitionKey | RowKey |
|---|---|
| 2011 New York City Marathon__Full | BIB:01234__John__M__55 |
| 2011 New York City Marathon__Full | AGE:055__1234__John__M |
이 예제에서는 PartitionKey 값이 동일하기 때문에 엔터티 그룹 트랜잭션이 가능합니다. 그룹 트랜잭션은 삽입 작업의 원자성을 제공합니다. 이 패턴을 다른 PartitionKey 값과 함께 사용할 수 있지만 동일한 값을 사용하여 이 이점을 얻는 것이 좋습니다. 그렇지 않으면 다른 PartitionKey 값을 사용하는 원자성 트랜잭션을 보장하기 위해 추가 논리를 작성해야 할 수 있습니다.
스토리지 작업
Azure Table Storage의 테이블은 쿼리에서뿐만 아니라 부하가 발생할 수 있습니다. 또한 삽입, 업데이트 및 삭제와 같은 스토리지 작업에서 부하가 발생할 수 있습니다. 테이블에서 수행할 스토리지 작업의 유형과 속도를 고려합니다. 이러한 작업을 자주 수행하는 경우 걱정할 필요가 없습니다. 그러나 짧은 시간에 많은 삽입을 수행하는 것과 같은 빈번한 작업의 경우 선택한 PartitionKey 값의 결과로 이러한 작업이 어떻게 제공되는지 고려해야 합니다. 중요한 예는 추가 전용 및 추가 전용 패턴입니다. 추가 전용 및 추가 전용 패턴은 범위 파티션에서 설명합니다.
추가 전용 또는 추가 전용 패턴을 사용하는 경우 후속 삽입 시 PartitionKey 에 고유한 오름차순 또는 내림차순 값을 사용합니다. 이 패턴을 빈번한 삽입 작업과 결합하면 테이블이 뛰어난 확장성으로 삽입 작업을 처리할 수 없습니다. Azure는 작업 요청을 다른 파티션 서버로 부하 분산할 수 없으므로 테이블의 확장성에 영향을 줍니다. 이 경우 GUID 값과 같이 임의 값을 사용하는 것이 좋습니다. 그런 다음 파티션 크기는 작게 유지되고 스토리지 작업 중에 부하 분산을 유지할 수 있습니다.
테이블 파티션 스트레스 테스트
PartitionKey 값이 복잡하거나 다른 PartitionKey 매핑과 비교해야 하는 경우 테이블의 성능을 테스트해야 할 수 있습니다. 이 테스트에서는 최대 부하 시 분할의 성능을 검사합니다.
스트레스 테스트를 수행하려면
- 테이블을 만듭니다.
- 대상으로 지정할 PartitionKey 값이 있는 엔터티를 포함할 수 있도록 데이터와 함께 테스트 테이블을 로드합니다.
- 애플리케이션을 사용하여 테이블에 대한 최대 부하를 시뮬레이션합니다. 2단계의 PartitionKey 값을 사용하여 단일 파티션 을 대상으로 지정합니다. 이 단계는 모든 애플리케이션에 대해 다르지만 시뮬레이션에는 필요한 모든 쿼리 및 스토리지 작업이 포함되어야 합니다. 단일 파티션을 대상으로 하려면 애플리케이션을 조정해야 할 수 있습니다.
- 테이블에 대한 GET 또는 PUT 작업의 처리량을 확인합니다.
처리량을 확인하려면 단일 서버의 단일 분할에 대한 지정된 제한과 실제 값을 비교하세요. 파티션은 초당 2000개의 엔터티로 제한됩니다. 파티션에 대한 처리량이 초당 2000개 엔터티를 초과하는 경우 프로덕션 설정에서 서버가 너무 뜨거워서 실행될 수 있습니다. 이 경우 PartitionKey 값이 너무 거칠어 파티션이 부족하거나 파티션이 너무 클 수 있습니다. 파티션이 더 많은 서버 간에 분산되도록 PartitionKey 값을 수정해야 할 수 있습니다.
부하 분산
파티션 계층의 부하 분산은 파티션이 너무 뜨거워지면 발생합니다. 파티션이 너무 뜨거운 경우 파티션, 특히 파티션 서버는 대상 확장성을 초과하여 작동합니다. Azure Storage의 경우 각 파티션의 확장성 목표는 초당 2,000개의 엔터티입니다. 부하 분산은 DFS(분산 파일 시스템) 계층에서도 발생합니다.
DFS 계층의 부하 분산은 I/O 부하를 처리하며 이 문서의 scope 외부에 있습니다. 확장성 목표를 초과한 후에는 파티션 계층의 부하 분산이 즉시 발생하지 않습니다. 대신 시스템은 부하 분산 프로세스를 시작하기 전에 몇 분 정도 기다립니다. 따라서 분할의 부하가 실제로 심해집니다. 시스템이 자동으로 작업을 수행하기 때문에 부하 분산을 트리거하는 생성된 부하로 파티션을 소수로 지정할 필요는 없습니다.
특정 부하로 테이블을 준비한 경우 시스템은 실제 부하에 따라 파티션의 균형을 유지할 수 있으므로 파티션의 분포가 크게 다를 수 있습니다. 파티션을 초기화하는 대신 시간 제한 및 서버 사용 중 오류를 처리하는 코드를 작성하는 것이 좋습니다. 시스템이 부하 분산 중일 때 오류가 반환됩니다. 재시도 전략을 사용하여 이러한 오류를 처리하면 애플리케이션에서 최대 부하를 더 잘 처리할 수 있습니다. 다시 시도 전략은 다음 섹션에서 자세히 논의합니다.
부하 분산이 발생하면 파티션이 몇 초 동안 오프라인 상태가 됩니다. 오프라인 기간 동안 시스템은 파티션을 다른 파티션 서버에 다시 할당합니다. 데이터가 파티션 서버에 의해 저장되지 않는다는 점에 유의해야 합니다. 대신 분할 서버는 DFS 계층의 엔터티를 제공합니다. 데이터가 파티션 계층에 저장되지 않으므로 파티션을 다른 서버로 이동하는 것은 빠른 프로세스입니다. 이러한 유연성은 애플리케이션에 발생할 수 있는 가동 중지 시간(있는 경우)을 크게 제한합니다.
재시도 전략
데이터 업데이트가 손실되지 않도록 하려면 애플리케이션에서 스토리지 작업 오류를 처리하는 것이 중요합니다. 일부 오류에는 재시도 전략이 필요하지 않습니다. 예를 들어 401 권한 없음 오류를 반환하는 업데이트는 401 오류를 resolve 재시도 간에 애플리케이션 상태가 변경되지 않을 가능성이 있으므로 작업을 다시 시도해도 도움이 되지 않습니다. 그러나 서버 사용 중 또는 시간 제한과 같은 오류는 테이블 확장성을 제공하는 Azure의 부하 분산 기능과 관련이 있습니다. 엔터티를 제공하는 스토리지 노드가 뜨거워지면 Azure는 파티션을 다른 노드로 이동하여 부하를 분산합니다. 이 시간 동안 파티션에 액세스할 수 없으므로 서버 사용 중 또는 시간 제한 오류가 발생할 수 있습니다. 결국 파티션을 다시 활성화하고 업데이트가 다시 시작됩니다.
재시도 전략은 서버 사용 중 또는 시간 제한 오류에 적합합니다. 대부분의 경우 재시도 논리에서 400 수준 오류와 500개 수준 오류를 제외할 수 있습니다. 제외할 수 있는 오류에는 501 구현되지 않음 및 505 HTTP 버전이 지원되지 않음이 포함됩니다. 그런 다음 서버 사용 중(503) 및 시간 제한(504)과 같은 최대 500 수준 오류에 대한 재시도 전략을 구현할 수 있습니다.
애플리케이션에 대한 세 가지 일반적인 재시도 전략 중에서 선택할 수 있습니다.
- 재시도 안 함: 다시 시도하지 않습니다.
- 백오프 수정: 작업이 상수 백오프 값으로 N번 다시 시도됩니다.
- 지수 백오프: 작업은 지수 백오프 값으로 N번 다시 시도됩니다.
다시 시도 안 함 전략은 작업 오류를 처리하는 간단한(그리고 회피적인) 방법입니다. 그러나 재시도 없음 전략은 별로 유용하지 않습니다. 다시 시도하지 않으면 작업 실패 후 데이터를 올바르게 저장하지 못하게 되는 위험이 생깁니다. 더 나은 전략은 고정 백오프 전략을 사용하는 것입니다. 동일한 백오프 기간으로 작업을 다시 시도하는 기능을 제공합니다.
그러나 이 전략은 확장성이 뛰어난 테이블을 처리하기 위해 최적화되지 않습니다. 많은 스레드 또는 프로세스가 동일한 기간을 기다리는 경우 충돌이 발생할 수 있습니다. 권장 재시도 전략은 각 재시도가 마지막 시도보다 긴 지수 백오프를 사용하는 전략입니다. 이더넷과 같은 컴퓨터 네트워크에서 사용되는 충돌 방지 알고리즘과 비슷합니다. 지수 백오프는 임의 요인을 사용하여 결과적인 간격에 추가 차이를 제공합니다. 그런 다음 백오프 값이 최소 및 최대 한계로 제한됩니다. 지수 알고리즘을 사용하여 다음 백오프 값을 계산하는 데 아래 수식을 사용할 수 있습니다.
y = Rand(0.8z, 1.2z)(2x-1
y = Min(zmin + y, zmax
위치:
z = 기본 백오프(밀리초)
zmin = 기본 최소 백오프(밀리초)
zmax = 기본 최대 백오프(밀리초)
x = 최대 다시 시도 수
y = 백오프 값(밀리초)
Rand(임의) 함수에 사용되는 0.8 및 1.2 승수는 원래 값의 ±20% 내에서 기본 백오프의 임의 분산을 생성합니다. ±20% 범위는 대부분의 재시도 전략에 허용되며 추가 충돌을 방지합니다. 다음 코드를 사용하여 수식을 구현할 수 있습니다.
int retries = 1;
// Initialize variables with default values
var defaultBackoff = TimeSpan.FromSeconds(30);
var backoffMin = TimeSpan.FromSeconds(3);
var backoffMax = TimeSpan.FromSeconds(90);
var random = new Random();
double backoff = random.Next(
(int)(0.8D * defaultBackoff.TotalMilliseconds),
(int)(1.2D * defaultBackoff.TotalMilliseconds));
backoff *= (Math.Pow(2, retries) - 1);
backoff = Math.Min(
backoffMin.TotalMilliseconds + backoff,
backoffMax.TotalMilliseconds);
요약
Table Storage는 여러 스토리지 노드에서 파티션을 관리하고 다시 할당하기 때문에 Azure Table Storage의 애플리케이션은 대량의 데이터를 저장할 수 있습니다. 데이터 분할을 사용하여 테이블의 확장성을 제어할 수 있습니다. 효율적인 분할 전략을 구현하도록 테이블 스키마를 정의할 때 미리 계획합니다. 특히 PartitionKey 값을 선택하기 전에 애플리케이션의 요구 사항, 데이터 및 쿼리를 분석합니다. 시스템이 트래픽에 응답할 때 각 파티션을 다른 스토리지 노드에 다시 할당할 수 있습니다. 파티션 스트레스 테스트를 사용하여 테이블에 올바른 PartitionKey 값이 있는지 확인합니다. 이 테스트는 파티션이 너무 뜨거웠는지 확인하는 데 도움이 되며 필요한 파티션을 조정하는 데 도움이 됩니다.
애플리케이션이 일시적인 오류를 처리하고 데이터가 유지되도록 하려면 백오프와 함께 재시도 전략을 사용합니다. Azure Storage 클라이언트 라이브러리에서 사용하는 기본 재시도 정책에는 충돌을 방지하고 애플리케이션의 처리량을 최대화하는 지수 백오프가 있습니다.