데이터 품질 규칙에 대해 알아보고 만들기
데이터 품질은 organization 데이터의 무결성을 측정하는 것이며 데이터 품질 점수를 사용하여 평가됩니다. Microsoft Purview 통합 카탈로그 정의된 규칙에 대한 데이터 평가에 따라 생성된 점수입니다.
데이터 품질 규칙은 조직이 데이터의 정확성, 일관성 및 완전성을 보장하기 위해 설정하는 필수 지침입니다. 이러한 규칙은 데이터 무결성 및 안정성을 유지하는 데 도움이 됩니다.
다음은 데이터 품질 규칙의 몇 가지 주요 측면입니다.
정확도 - 데이터는 실제 엔터티를 정확하게 나타내야 합니다. 컨텍스트가 중요합니다! 예를 들어 고객 주소를 저장하는 경우 실제 위치와 일치하는지 확인합니다.
완전성 - 이 규칙의 목적은 빈 데이터, null 또는 누락된 데이터를 식별하는 것입니다. 이 규칙은 모든 값이 있는지 확인합니다(반드시 올바르지는 않지만).
적합성 - 이 규칙은 데이터가 날짜, 주소 및 허용되는 값의 표현과 같은 데이터 서식 표준을 따르도록 합니다.
일관성 - 이 규칙은 동일한 레코드의 다른 값이 지정된 규칙에 부합하고 모순이 없는지 확인합니다. 데이터 일관성을 통해 동일한 정보가 서로 다른 레코드에서 균일하게 표현됩니다. instance 제품 카탈로그가 있는 경우 일관된 제품 이름과 설명이 중요합니다.
타임라인 - 이 규칙은 가능한 한 짧은 시간 안에 데이터에 액세스할 수 있도록 하는 것을 목표로 합니다. 데이터가 최신 상태인지 확인합니다.
고유성 - 이 규칙은 값이 중복되지 않는지 확인합니다. 예를 들어 고객당 하나의 레코드만 있어야 하는 경우 동일한 고객에 대한 레코드가 여러 개 없는 경우입니다. 각 고객, 제품 또는 트랜잭션에는 고유한 식별자가 있어야 합니다.
데이터 품질 수명 주기
데이터 품질 규칙을 만드는 것은 데이터 품질 수명 주기의 여섯 번째 단계입니다. 이전 단계는 다음과 같습니다.
- 통합 카탈로그 사용자 데이터 품질 관리자 권한을 할당하여 모든 데이터 품질 기능을 사용합니다.
- Microsoft Purview 데이터 맵 데이터 원본을 등록하고 검사합니다.
- 데이터 제품에 데이터 자산 추가
- 데이터 품질 평가를 위해 원본을 준비하도록 데이터 원본 연결을 설정합니다.
- 데이터 원본의 자산에 대한 데이터 프로파일링을 구성하고 실행합니다.
필수 역할
- 데이터 품질 규칙을 만들고 관리하려면 사용자가 데이터 품질 관리자 역할에 있어야 합니다.
- 기존 품질 규칙을 보려면 사용자가 데이터 품질 판독기 역할에 있어야 합니다.
기존 데이터 품질 규칙 보기
Microsoft Purview 통합 카탈로그 상태 관리 메뉴 및 데이터 품질 하위 메뉴를 선택합니다.
데이터 품질 하위 메뉴에서 거버넌스 도메인을 선택합니다.
데이터 제품을 선택합니다.
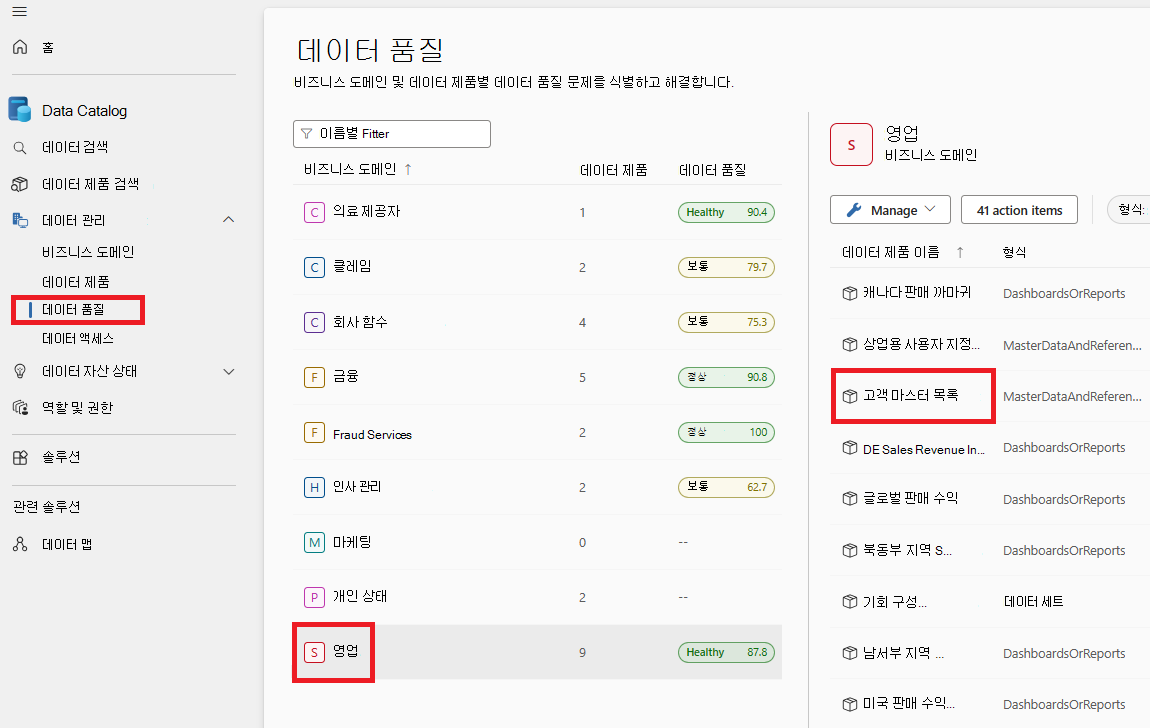
선택한 데이터 제품의 자산 목록에서 데이터 자산을 선택합니다.
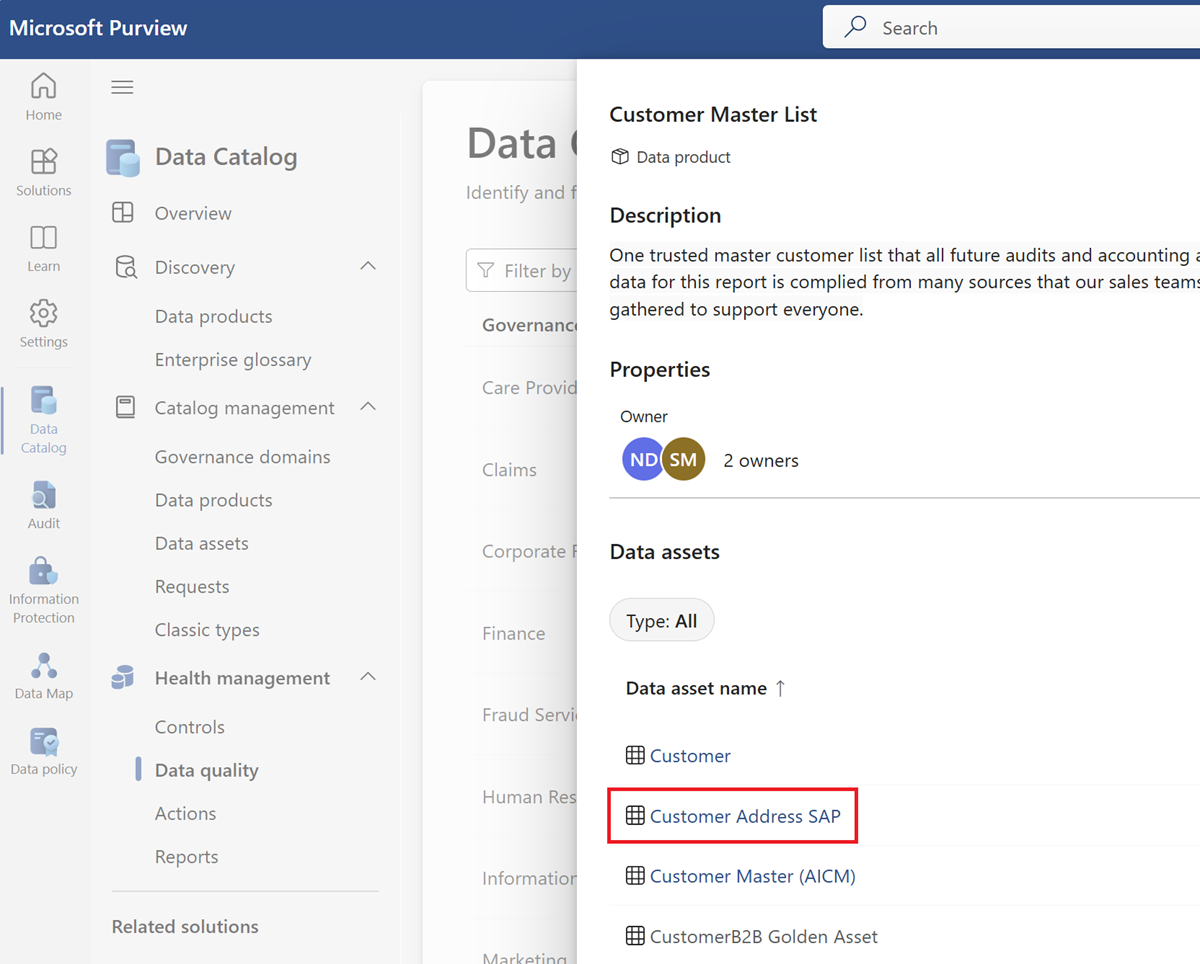
규칙 메뉴 탭을 선택하여 자산에 적용된 기존 규칙을 확인합니다.

규칙을 선택하여 적용된 규칙의 성능 기록을 선택한 데이터 자산으로 찾습니다.





사용 가능한 데이터 품질 규칙
Microsoft Purview 데이터 품질 아래 규칙을 구성할 수 있습니다. 이러한 규칙은 데이터 품질을 측정하는 코드 없는 방법으로 낮은 코드를 제공하는 기본 규칙입니다.
| 규칙 | 정의 |
|---|---|
| 신선도 | 모든 값이 최신 상태임을 확인합니다. |
| 고유 값 | 열의 값이 고유한지 확인합니다. |
| 문자열 형식 일치 | 열의 값이 특정 형식 또는 다른 조건과 일치하는지 확인합니다. |
| 데이터 형식 일치 | 열의 값이 해당 데이터 형식 요구 사항과 일치하는지 확인합니다. |
| 행 중복 | 두 개 이상의 열에서 동일한 값을 가진 중복 행을 확인합니다. |
| 빈/빈 필드 | 값이 있어야 하는 열에서 빈 필드와 빈 필드를 찾습니다. |
| 테이블 조회 | 한 테이블의 값을 다른 테이블의 특정 열에서 찾을 수 있음을 확인합니다. |
| 사용자 지정 | 시각적 식 작성기를 사용하여 사용자 지정 규칙을 만듭니다. |
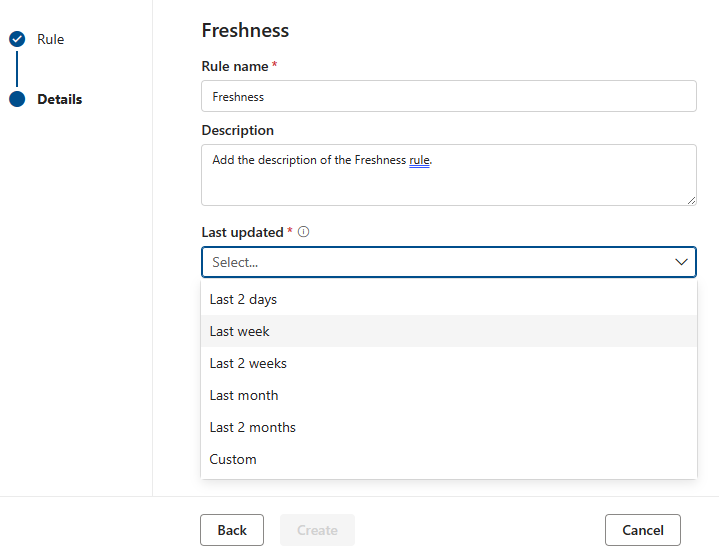
신선도
새로 고침 규칙의 목적은 자산이 예상 시간 내에 업데이트되었는지 여부를 결정하는 것입니다. Microsoft Purview는 현재 마지막으로 수정된 날짜를 확인하여 새로 고침 확인을 지원합니다.
참고
새로 고침 규칙에 대한 점수는 100(통과됨) 또는 0(실패)입니다. Snowflake, Azure Databricks UC, Google BigQuery, Synapes 및 Azure SQL 대한 신선도 규칙은 지원되지 않습니다.
고유 값
고유 값 규칙은 지정된 열의 모든 값이 고유해야 한다고 명시합니다. 고유한 'pass'인 모든 값과 실패로 처리되지 않는 값입니다. 빈/빈 필드 규칙이 열에 정의되어 있지 않으면 이 규칙의 용도로 null/empty 값이 무시됩니다.

문자열 형식 일치
형식 일치 규칙은 열의 모든 값이 유효한지 확인합니다. 빈/빈 필드 규칙이 열에 정의되어 있지 않으면 이 규칙의 용도로 null/empty 값이 무시됩니다.
이 규칙은 세 가지 방법을 사용하여 열의 각 값의 유효성을 검사할 수 있습니다.
열거형 – 쉼표로 구분된 값 목록입니다. 평가되는 값을 나열된 값 중 하나와 비교할 수 없는 경우 검사 실패합니다. 백슬래시 를
\사용하여 쉼표 및 백슬래시를 이스케이프할 수 있습니다. 따라서a \, b, c첫 번째 값은 2개, 두 번째 값은a , b입니다c.
유사 패턴 -
like(<string> : string, <pattern match> : string) => boolean
패턴은 문자 그대로 일치하는 문자열입니다. 예외는 다음과 같은 특수 기호입니다. _ 는 입력의 한 문자(정규식과 유사)와 일치합니다.posix%는 입력에서 0개 이상의 문자(정규식의 경우 .*posix와 유사)와 일치합니다. 이스케이프 문자는 ''입니다. 이스케이프 문자가 특수 기호 또는 다른 이스케이프 문자 앞에 오는 경우 다음 문자는 문자 그대로 일치합니다. 다른 문자를 이스케이프하는 것은 유효하지 않습니다.like('icecream', 'ice%') -> true

정규식 –
regexMatch(<string> : string, <regex to match> : string) => boolean
문자열이 지정된 정규식 패턴과 일치하는지 확인합니다. 이스케이프하지 않고 문자열을 일치하려면 (따옴표)를 사용합니다<regex>.regexMatch('200.50', '(\\d+).(\\d+)') -> trueregexMatch('200.50', `(\d+).(\d+)`) -> true

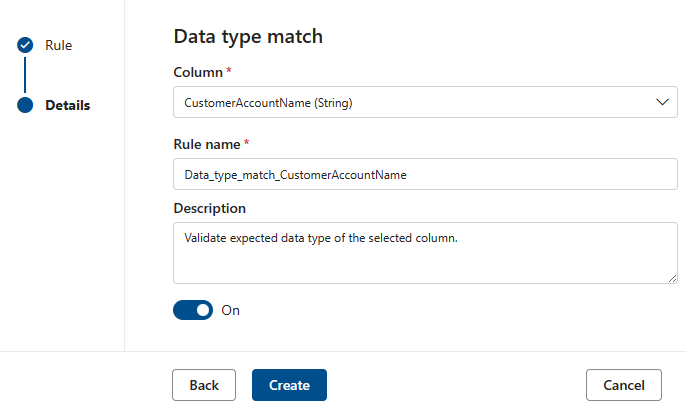
데이터 형식 일치
데이터 형식 일치 규칙은 연결된 열에 포함될 것으로 예상되는 데이터 형식을 지정합니다. 규칙 엔진은 다양한 데이터 원본에서 실행해야 하므로 BIGINT 또는 VARCHAR와 같은 네이티브 형식을 사용할 수 없습니다. 대신 네이티브 형식을 변환하는 고유한 형식 시스템이 있습니다. 이 규칙은 네이티브 형식을 변환해야 하는 기본 제공 형식 중 품질 검사 엔진에 지시합니다. 데이터 형식 시스템은 Azure Data Factory 사용되는 Azure Data Flow 형식 시스템에서 가져옵니다.
품질 검사 중에는 모두 네이티브 형식이 데이터 형식 일치 형식에 대해 테스트되고 네이티브 형식을 데이터 형식 일치 형식으로 변환할 수 없는 경우 해당 행이 오류로 처리됩니다.
행 중복
중복 행 규칙은 열의 값 조합이 테이블의 모든 행에 대해 고유한지 확인합니다.
아래 예제에서는 _CompanyName, CustomerID, EmailAddress, FirstName 및 LastName 의 연결이 테이블의 모든 행에 대해 고유한 값을 생성할 것으로 예상합니다.
각 자산은 이 규칙의 instance 0개 또는 1개를 가질 수 있습니다.

빈/빈 필드
빈/빈 필드 규칙은 식별된 열에 null 값이 포함되어서는 안 되며 특정 문자열의 경우 빈 값이나 공백만 있으면 안 된다고 어설션합니다. 품질 검사 중에 null이 아닌 이 열의 모든 값이 올바른 것으로 처리됩니다. 이 규칙은 고유 값 또는 서식 일치 규칙과 같은 다른 규칙에 영향을 미칩니다. 이 규칙이 열에 정의되지 않은 경우 해당 열에서 실행할 때 해당 규칙은 null 값을 자동으로 무시합니다. 이 규칙이 열에 정의된 경우 해당 규칙은 해당 열에서 null/빈 값을 검사하고 점수 용도로 고려합니다.
테이블 조회
테이블 조회 규칙은 규칙이 정의된 열의 각 값을 검사하고 참조 테이블과 비교합니다. 예를 들어 기본 테이블에는 "city, state zip" 형식의 도시, 주 및 우편 번호가 포함된 "location"이라는 열이 있습니다. 미국 지원되는 도시, 주 및 우편 번호의 모든 법적 조합을 포함하는 citystate라는 참조 테이블이 있습니다. 목표는 현재 열의 모든 위치를 해당 참조 목록과 비교하여 법적 조합만 사용되고 있는지 확인하는 것입니다.
이렇게 하려면 먼저 "citystatezip의 이름을 검색 자산 대화 상자에 입력합니다. 그런 다음 원하는 자산을 선택한 다음 비교할 열을 선택합니다.
참고
참조 테이블 또는 데이터 자산은 동일한 거버넌스 도메인에 속해야 합니다. 여러 거버넌스 도메인에서 데이터 자산을 비교할 수 없습니다.
사용자 지정 규칙
사용자 지정 규칙을 사용하면 해당 행에서 하나 이상의 값을 기반으로 행의 유효성을 검사하는 규칙을 지정할 수 있습니다. 사용자 지정 규칙에는 다음 두 부분이 있습니다.
- 첫 번째 부분은 선택 사항이며 "필터 식 사용"으로 검사 상자를 선택하여 활성화되는 필터 식입니다. 부울 값을 반환하는 식입니다. 필터 식이 행에 적용되고 true를 반환하면 해당 행이 규칙에 대해 고려됩니다. 필터 식이 해당 행에 대해 false를 반환하는 경우 이 규칙의 용도로 행이 무시됨을 의미합니다. 필터 식의 기본 동작은 모든 행을 전달하는 것입니다. 따라서 필터 식이 지정되지 않고 하나도 필요하지 않은 경우 모든 행이 고려됩니다.
- 두 번째 부분은 행 식입니다. 필터 식에 의해 승인되는 각 행에 적용되는 부울 식입니다. 이 식이 true를 반환하면 행이 통과하고 false이면 실패로 표시됩니다.

사용자 지정 규칙의 예
| 시나리오 | 행 식 |
|---|---|
| state_id 캘리포니아와 같고 aba_Routing_Number 특정 정규식 패턴과 일치하는지 확인하고 생년월일은 특정 범위에 속합니다. | state_id=='California' && regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| VendorID가 124와 같은지 확인 | {VendorID}=='124' |
| fare_amount 같거나 100보다 큰지 확인합니다. | {fare_amount} >= "100" |
| fare_amount 100보다 크고 tolls_amount 100이 아닌지 확인합니다. | {fare_amount} >= "100" || {tolls_amount} != "400" |
| 등급이 5보다 작은지 확인 | Rating < 5 |
| 연도의 숫자 수가 4인지 확인합니다. | length(toString(year)) == 4 |
| 두 열 bbToLoanRatio 및 bankBalance를 비교하여 값이 같은 경우 검사 | compare(variance(toLong(bbToLoanRatio)),variance(toLong(bankBalance)))<0 |
| firstName, lastName, LoanID, uuid의 자른 문자 수와 연결된 문자 수가 20보다 큰지 확인합니다. | length(trim(concat(firstName,lastName,LoanID,uuid())))>20 |
| aba_Routing_Number 특정 정규식 패턴과 일치하고 초기 거래 날짜가 2022-11-12보다 크고 Disallow-Listed가 false이고 평균 bankBalance가 50000보다 크고 state_id '매사추세츠', '테네시', '노스 다코타' 또는 '알바마'와 같은지 확인합니다. | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && toDate(addDays(toTimestamp(initialTransaction, 'yyyy-MM-dd\'T\'HH:mm:ss'),15))>toDate('2022-11-12') && ({Disallow-Listed}=='false') && avg(toLong(bankBalance))>50000 && (state_id=='Massachuse' || state_id=='Tennessee ' || state_id=='North Dakota' || state_id=='Albama') |
| aba_Routing_Number 특정 정규식 패턴과 일치하는지 확인하고 dateOfBirth가 1968-12-13에서 2020-12-13 사이인지 확인합니다. | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| aba_Routing_Number 고유 값 수가 1,000,000과 같고 EMAIL_ADDR 고유 값 수가 1,000,000과 같은지 확인합니다. | approxDistinctCount({aba_Routing_Number})==1000000 && approxDistinctCount({EMAIL_ADDR})==1000000 |
필터 식과 행 식은 여기에 정의된 언어와 함께 여기에 도입된 Azure Data Factory 식 언어를 사용하여 정의됩니다. 그러나 제네릭 ADF 식 언어에 대해 정의된 모든 함수를 사용할 수 있는 것은 아닙니다. 사용 가능한 함수의 전체 목록은 식 대화 상자에서 사용할 수 있는 함수 목록에 있습니다. 여기에 정의된 다음 함수는 지원되지 않습니다. isDelete, isError, isIgnore, isInsert, isMatch, isUpdate, isUpsert, partitionId, 캐시된 조회 및 Window 함수.
참고
<regex> (백쿼트)는 특수 문자를 이스케이프하지 않고 문자열과 일치하도록 사용자 지정 규칙에 포함된 정규식에 사용할 수 있습니다. 정규식 언어는 Java를 기반으로 하며 여기에 지정된 대로 작동합니다.
이 페이지에서 는 이스케이프해야 하는 문자를 식별합니다.
AI 지원 자동 생성 규칙
데이터 품질 측정을 위한 AI 지원 자동화된 규칙 생성에는 AI(인공 지능) 기술을 사용하여 데이터 품질을 평가하고 개선하기 위한 규칙을 자동으로 만드는 작업이 포함됩니다. 자동 생성된 규칙은 콘텐츠별로 다릅니다. 사용자가 사용자 지정 규칙을 만드는 데 많은 노력을 기울일 필요가 없도록 대부분의 일반적인 규칙이 자동으로 생성됩니다.
자동 생성된 규칙을 찾아보고 적용하려면 다음을 수행합니다.
- 규칙 페이지에서 규칙 제안 을 선택합니다.
- 제안된 규칙 목록을 찾아봅니다.

- 데이터 자산에 적용할 제안된 규칙 목록에서 규칙을 선택합니다.

다음 단계
- 데이터 제품에서 데이터 품질 검사를 구성하고 실행 하여 데이터 제품의 지원되는 모든 자산의 품질을 평가합니다.
- 검사 결과를 검토 하여 데이터 제품의 현재 데이터 품질을 평가합니다.