Microsoft Purview 데이터 맵 분류 모범 사례
Microsoft Purview 데이터 맵 데이터 분류는 데이터 자산에 고유한 논리 레이블 또는 클래스를 할당하여 데이터 자산을 분류하는 방법입니다. 분류는 데이터의 비즈니스 컨텍스트를 기반으로 합니다. 예를 들어 여권 번호, 운전 면허증 번호, 신용 카드 번호, SWIFT 코드, 사람의 이름 등을 기준으로 자산을 분류할 수 있습니다. 분류 자체에 대한 자세한 내용은 분류 문서를 참조하세요.
이 문서에서는 데이터 자산을 분류할 때 채택하는 모범 사례를 설명하여 검사가 더 효과적이고 전체 데이터 자산에 대해 가능한 가장 완전한 정보를 갖도록 합니다.
검사 규칙 집합
검사 규칙 집합을 사용하여 데이터 원본에 대한 특정 검사에 적용해야 하는 관련 분류를 구성할 수 있습니다. 관련 시스템 분류를 선택하거나 검사 중인 데이터에 대해 사용자 지정 분류를 만든 경우 사용자 지정 분류를 선택합니다.
예를 들어 다음 이미지에서는 검사하는 데이터 원본(예: 재무 데이터)에 대해 선택한 특정 시스템 및 사용자 지정 분류만 적용됩니다.

주석 관리
적용할 분류를 결정하는 동안 다음을 수행하는 것이 좋습니다.
데이터 맵>주석 관리>분류 창으로 이동합니다.
검사하는 데이터 자산에 적용할 사용 가능한 시스템 분류를 검토합니다. 시스템 분류의 정식 이름에는 MICROSOFT 접두사가 있습니다.
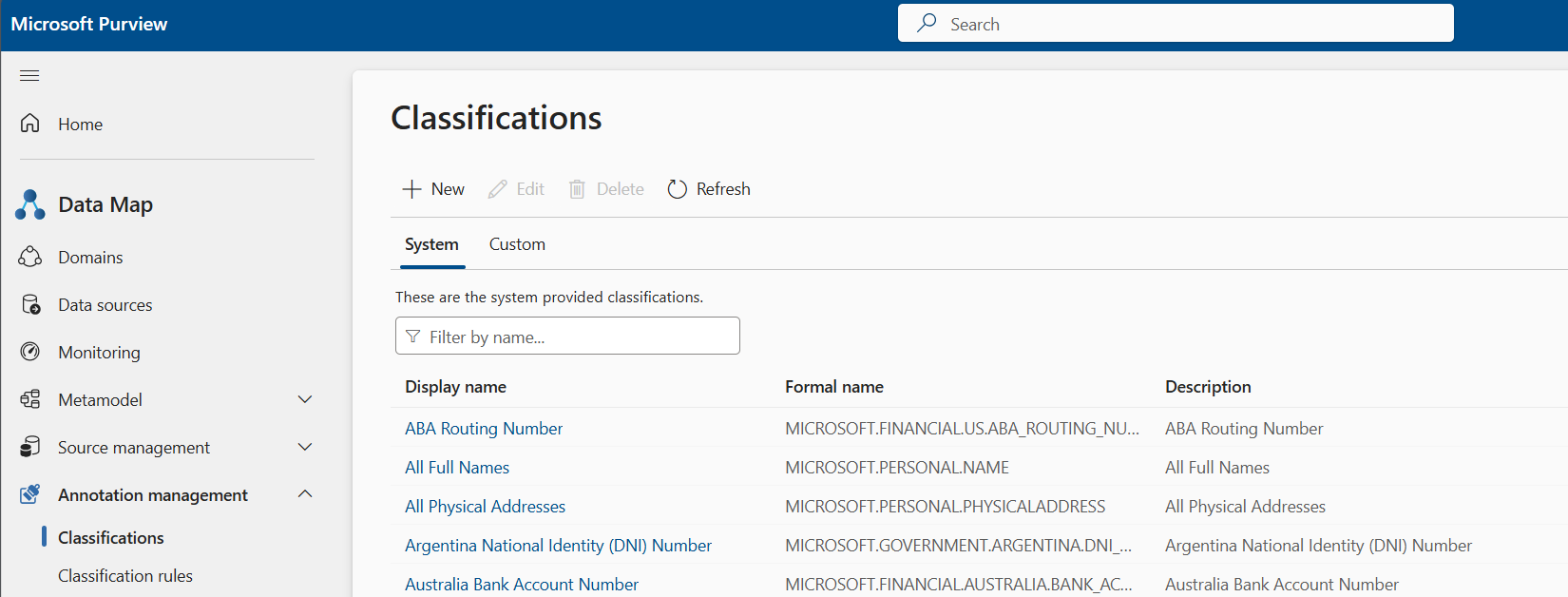
필요한 경우 사용자 지정 분류를 만듭니다. 사용자 지정 탭을 선택한 다음+ 새로 만들기를 선택합니다. 사용자 지정 분류를 만드는 방법에 대한 자세한 내용은 사용자 지정 분류 문서를 참조하세요.
이전 단계에서 만든 사용자 지정 분류에 대한 분류 규칙을 만듭니다. 데이터 맵>주석 관리>분류 규칙으로 이동합니다. 여기서는 이전 단계에서 만든 사용자 지정 분류 이름에 대한 분류 규칙을 만들 수 있습니다.


사용자 지정 분류
사용 가능한 시스템 분류가 요구 사항을 충족하지 않는 경우에만 사용자 지정 분류를 만듭니다.
사용자 지정 분류의 이름에 대해 네임스페이스 규칙(예<: 회사 이름>)을 사용하는 것이 좋습니다.<>사업부.<사용자 지정 분류 이름>).
예를 들어 가상 회사 Contoso에 대한 사용자 지정 EMPLOYEE_ID 분류의 경우 사용자 지정 분류의 이름은 CONTOSO.HR. EMPLOYEE_ID 식별 이름은 시스템에 HR로 저장됩니다. 직원 ID입니다.

사용자 지정 분류에 대한 분류 규칙을 만들고 구성할 때 다음을 수행합니다.
분류 규칙을 만들 적절한 분류 이름을 선택합니다.
Microsoft Purview 데이터 맵 사용자 지정 분류 규칙을 만드는 다음 두 가지 방법을 지원합니다.
정규 식 패턴을 사용하여 데이터 요소를 일관되게 표현할 수 있거나 데이터 파일을 사용하여 패턴을 생성할 수 있는 경우 정규식(regex) 메서드를 사용합니다. 샘플 데이터가 모집단을 반영하는지 확인합니다.
사전 파일의 값 목록이 분류할 데이터의 가능한 모든 값을 나타내고 지정된 데이터 집합(향후 값도 고려)을 준수해야 하는 경우에만 Dictionary 메서드를 사용합니다.
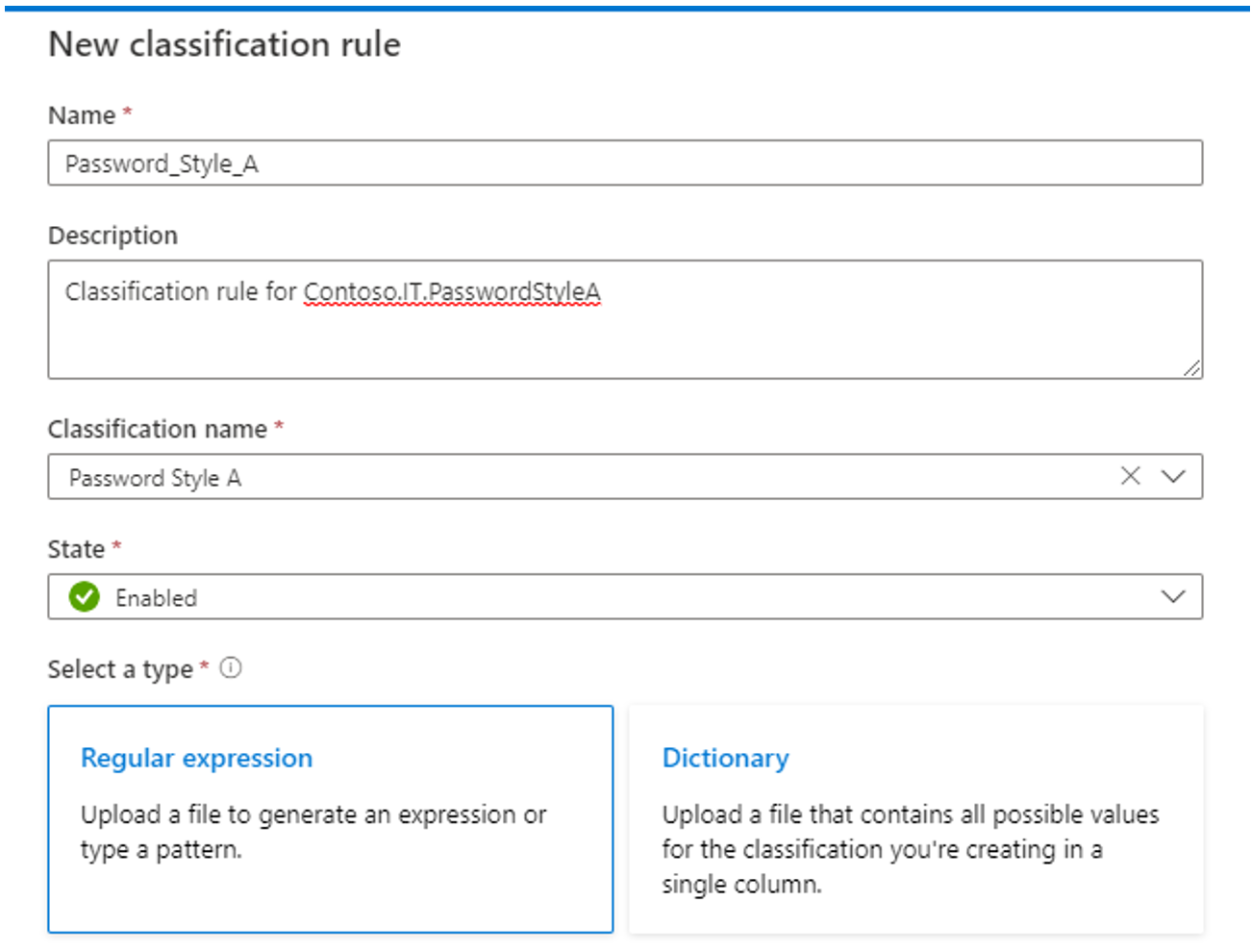
정규식 메서드 사용:
분류할 데이터에 대한 정규식 패턴을 구성합니다. 정규식 패턴이 분류되는 데이터에 맞게 충분히 일반적인지 확인합니다.
Microsoft Purview는 제안된 정규식 패턴을 생성하는 기능도 제공합니다. 샘플 데이터 파일을 업로드한 후 제안된 패턴 중 하나를 선택한 다음 패턴 에 추가를 선택하여 제안된 데이터 및 열 패턴을 사용합니다. 제안된 패턴을 수정하거나 파일을 업로드하지 않고도 고유한 패턴을 입력할 수 있습니다.
가양성 최소화를 위해 열을 분류할 열 이름 패턴을 구성할 수도 있습니다.
데이터 패턴과 일치하는 데이터에 허용되는 최소 일치 임계값 매개 변수를 구성하여 분류를 적용합니다. 임계값은 1%에서 100%로 설정할 수 있습니다. 가양성 방지를 위한 임계값으로 최소 60%의 값을 권장합니다. 그러나 특정 분류 시나리오에 필요한 대로 구성할 수 있습니다. 예를 들어 패턴과 일치하는 경우 데이터의 모든 값에 대한 분류를 검색하고 적용하려는 경우 임계값이 1%로 낮을 수 있습니다.
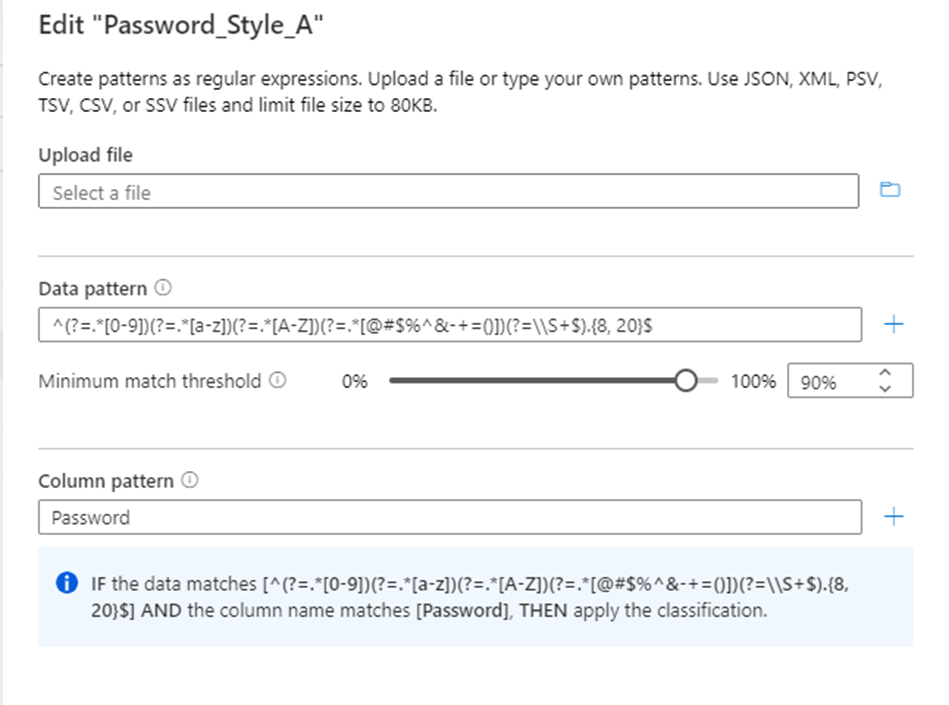
둘 이상의 데이터 패턴이 분류 규칙에 추가되면 최소 일치 규칙을 설정하는 옵션이 자동으로 비활성화됩니다.
테스트 분류 규칙을 사용하고 샘플 데이터로 테스트하여 분류 규칙이 예상대로 작동하는지 확인합니다. 샘플 데이터(예: .csv 파일)에 분류를 적용할 열을 포함하여 세 개 이상의 열이 있는지 확인합니다. 테스트에 성공하면 다음 이미지와 같이 열에 분류 레이블이 표시됩니다.
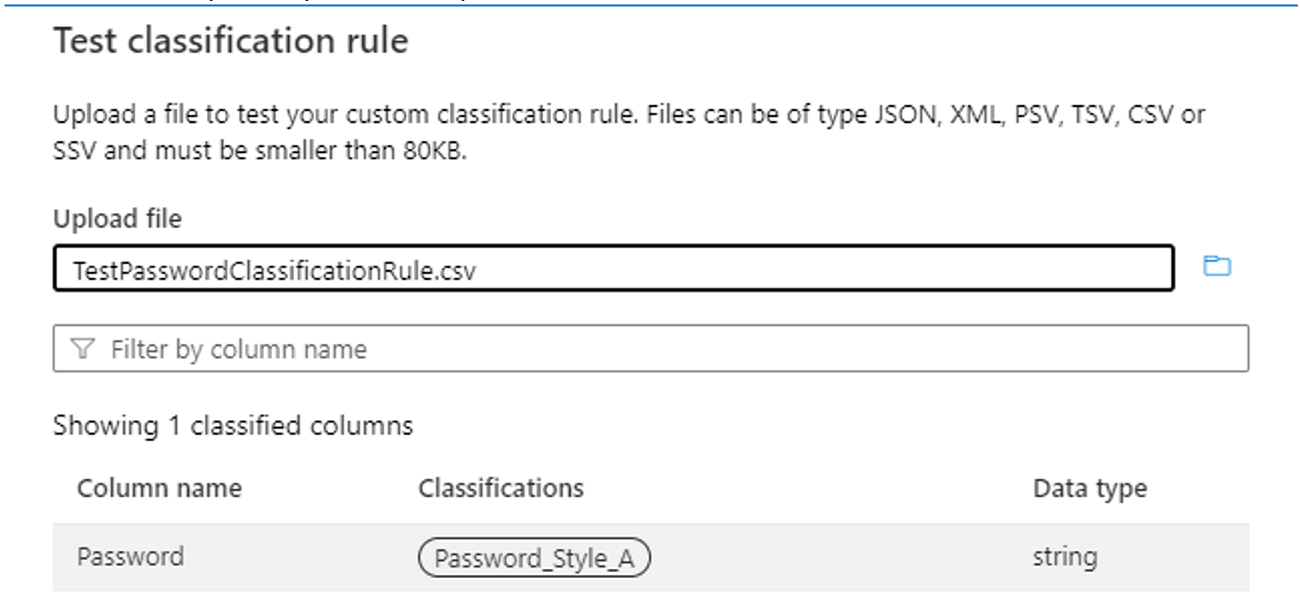
Dictionary 메서드 사용:
Dictionary 메서드를 사용하여 열거형 데이터를 맞추거나 가능한 값의 사전 목록을 사용할 수 있는 경우 사용할 수 있습니다.
이 메서드는 파일 크기 제한이 30MB(MB)인 .csv 및 .tsv 파일을 지원합니다.



사용자 지정 분류 원형
정규식에서 "임계값" 매개 변수의 작동 방식
다음 이미지에서 샘플 원본 데이터를 고려합니다. 5개의 열이 있으며 데이터 패턴 N{Digit}{Digit}{Digit}{Digit}AN에 대한 Sample_col1,Sample_col2 및 Sample_col3 열에 사용자 지정 분류 규칙을 적용해야 합니다.
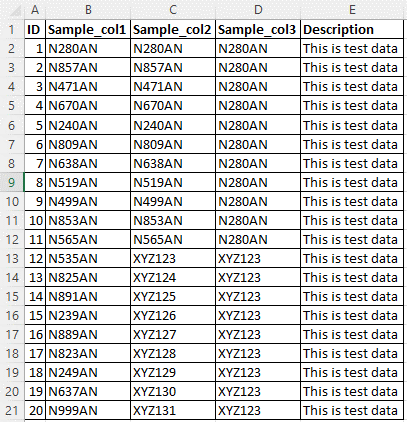
사용자 지정 분류의 이름은 NDDDAN입니다.
분류 규칙(데이터 패턴의 정규식)은 ^N[0-9]{3}AN$입니다.

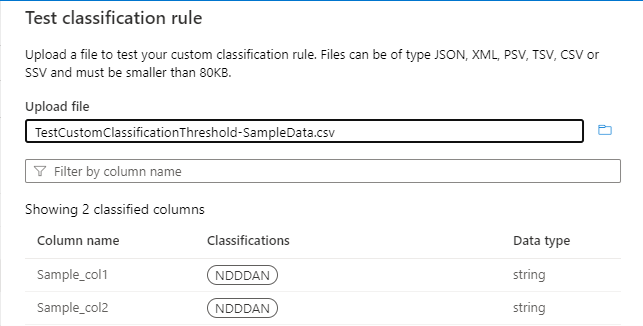
임계값은 다음 이미지와 같이 "^N[0-9]{3}AN$" 패턴에 대해 계산됩니다.

임계값이 55%인 경우 Sample_col1 및 Sample_col2 열만 분류됩니다. Sample_col3 55% 임계값 조건을 충족하지 않으므로 분류되지 않습니다.




데이터 및 열 패턴을 모두 사용하는 방법
B 열과 C 열의 데이터 패턴이 비슷한 지정된 샘플 데이터의 경우 데이터 패턴 "^P[0-9]{3}[A-Z]{2}$"에 따라 B열을 분류할 수 있습니다.
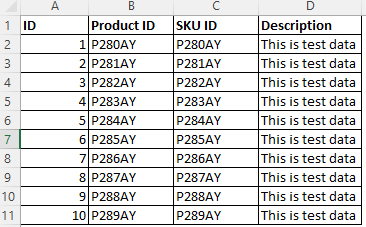
데이터 패턴과 함께 열 패턴을 사용하여 제품 ID 열만 분류되도록 합니다.
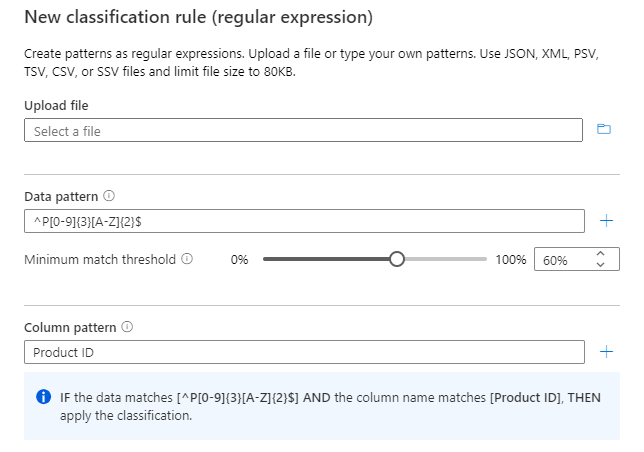
참고
열 패턴은 데이터 패턴이 있는 AND 조건으로 확인됩니다.
테스트 분류 규칙을 사용하고 샘플 데이터로 테스트하여 분류 규칙이 예상대로 작동하는지 확인합니다.




여러 열 패턴을 사용하는 방법
동일한 분류 규칙에 대해 분류할 여러 열 패턴이 있는 경우 파이프(|) 문자로 구분된 열 이름을 사용합니다. 예를 들어 제품 ID, Product_ID, ProductID 등의 열에 대해 다음 이미지와 같이 열 패턴을 작성합니다.

자세한 내용은 regex alternation 구문을 참조하세요.
분류 고려 사항
분류를 정의할 때 고려해야 할 몇 가지 고려 사항은 다음과 같습니다.
검사하기 전에 자산에 적용해야 하는 분류를 결정하려면 분류를 사용하는 방법을 고려합니다. 불필요한 분류 레이블은 시끄럽고 데이터 소비자에게 오해의 소지가 있을 수 있습니다. 분류를 사용하여 다음을 수행할 수 있습니다.
- 검사 중인 데이터 자산 또는 스키마에 있는 데이터의 특성을 설명합니다. 즉, 분류를 사용하면 고객이 카탈로그를 검색할 때 분류 레이블에서 데이터 자산 또는 스키마의 콘텐츠를 식별할 수 있습니다.
- 우선 순위를 설정하고 organization 보안 및 규정 준수 요구 사항을 달성하기 위한 계획을 개발합니다.
- 데이터 준비 프로세스의 단계(원시 영역, 랜딩 존 등)를 설명하고 특정 자산에 분류를 할당하여 프로세스의 단계를 표시합니다.
검사 규칙에 관련 분류를 포함하여 자산 또는 열 수준에서 분류를 자동으로 할당하거나 메타데이터를 Microsoft Purview 데이터 맵 수집한 후 수동으로 할당할 수 있습니다.
Microsoft Purview 데이터 맵 데이터 원본을 검사하기 전에 데이터를 이해하고 적절한 검사 규칙 집합(예: 관련 시스템 분류, 사용자 지정 분류 또는 둘의 조합을 선택)을 구성하는 것이 중요합니다. 이는 검사 성능에 영향을 줄 수 있기 때문입니다. 자세한 내용은 Microsoft Purview 데이터 맵 지원되는 분류를 참조하세요.
Microsoft Purview 스캐너는 시스템 및 사용자 지정 분류 모두에 대해 심층 검사(분류에 따라 다됨)에 대한 데이터 샘플링 규칙을 적용합니다. 샘플링 규칙은 데이터 원본의 형식을 기반으로 합니다. 자세한 내용은 Microsoft Purview에서 지원되는 데이터 원본 및 파일 형식의 "파일 내 샘플링" 섹션을 참조하세요.
참고
고유 데이터 임계값: 스캐너가 데이터 패턴을 실행하기 전에 열에서 찾아야 하는 총 고유 데이터 값 수입니다. 고유 데이터 임계값은 패턴 일치와는 아무 상관이 없지만 패턴 일치를 위한 필수 구성 요소입니다. 시스템 분류 규칙에 따라 분류를 적용하려면 각 열에 8개 이상의 고유 값이 있어야 합니다. 시스템에는 스캐너가 정확하게 분류할 수 있는 충분한 데이터가 열에 포함되어 있는지 확인하기 위해 이 값이 필요합니다. 예를 들어 값 1이 모두 포함된 여러 행이 포함된 열은 분류되지 않습니다. 한 행에 값이 있고 나머지 행에 null 값이 있는 열도 분류되지 않습니다. 여러 패턴을 지정하는 경우 이 값은 각 패턴에 적용됩니다.
샘플링 규칙은 리소스 집합에도 적용됩니다. 자세한 내용은 Microsoft Purview 데이터 맵 지원되는 데이터 원본 및 파일 형식의 "리소스 집합 파일 샘플링" 섹션을 참조하세요.
사용자 지정 분류 규칙을 사용하여 문서 형식 자산에 사용자 지정 분류를 적용할 수 없습니다. 이러한 형식에 대한 분류는 수동으로만 적용할 수 있습니다.
사용자 지정 분류는 기본 검사 규칙에 포함되지 않습니다. 따라서 사용자 지정 분류의 자동 할당이 필요한 경우 사용자 지정 분류를 포함하는 사용자 지정 검사 규칙을 배포하고 사용하여 검사를 실행해야 합니다.
Microsoft Purview 거버넌스 포털에서 수동으로 분류를 적용하는 경우 이러한 분류는 후속 검사에서 유지됩니다.
후속 검사는 분류 규칙을 적용할 수 없는 경우에도 이전에 검색된 경우 자산에서 분류를 제거하지 않습니다.
암호화된 원본 데이터 자산의 경우 Microsoft Purview는 파일 이름, 정규화된 이름, 구조화된 파일 형식에 대한 스키마 세부 정보 및 데이터베이스 테이블만 선택합니다. 분류가 작동하려면 검사를 실행하기 전에 암호화된 데이터의 암호를 해독합니다.