빠른 R-CNN을 사용한 개체 감지
목차
요약


이 자습서에서는 BrainScript 및 cntk.exe CNTK Fast R-CNN을 사용하는 방법을 설명합니다. CNTK Python API를 사용하는 빠른 R-CNN은 여기에 설명되어 있습니다.
위의 예제는 이 자습서에서 사용되는 식료품 데이터 집합(첫 번째 이미지) 및 Pascal VOC 데이터 집합(두 번째 이미지)에 대한 이미지 및 개체 주석입니다.
빠른 R-CNN 은 2015년 Ross Girshick 이 제안한 개체 감지 알고리즘입니다. 이 논문은 ICCV 2015에 허용되고 보관됩니다 https://arxiv.org/abs/1504.08083. 빠른 R-CNN은 심층 나선형 네트워크를 사용하여 개체 제안을 효율적으로 분류하기 위해 이전 작업을 기반으로 합니다. 이전 작업과 비교하여 Fast R-CNN은 나선형 계층에서 계산 을 다시 사용할 수 있는 관심 풀링 구성표를 사용합니다.
추가 자료: BrainScript에서 CNTK Fast R-CNN을 사용하는 개체 감지에 대한 자세한 자습서(선택적 SVM 학습 및 학습된 모델을 Rest API로 게시 포함)는 여기에서 찾을 수 있습니다.
설치 프로그램
이 예제에서 코드를 실행하려면 CNTK Python 환경이 필요합니다(설치 도움말은 여기 참조). 또한 몇 가지 추가 패키지를 설치해야 합니다. FastRCNN 폴더로 이동하여 다음을 실행합니다.
pip install -r requirements.txt
알려진 문제: scikit-learn을 설치하려면 Anaconda Python을 사용하는 경우 실행 conda install scikit-learn 해야 할 수 있습니다.
이러한 예제를 실행하려면 Scikit-Image 및 OpenCV가 추가로 필요합니다.
해당 휠 패키지를 다운로드하고 수동으로 설치하세요. Linux에서 다음을 수행할 수 있습니다 conda install scikit-image opencv.
Windows 사용자의 경우 다음을 방문하여 http://www.lfd.uci.edu/~gohlke/pythonlibs/다운로드합니다.
- Python 3.5
- scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
- opencv_python-3.2.0-cp35-cp35m-win_amd64.whl
해당 휠 이진 파일을 다운로드한 후 다음을 사용하여 설치합니다.
pip install your_download_folder/scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
[! 참고]: 스크립트를 실행할 때 이름이 과거로 명명되지 않은 모듈 이 없다는 메시지가 표시되면 실행 pip install future하세요.
이 자습서 코드에서는 64비트 버전의 Python 3.5 또는 3.6을 사용한다고 가정합니다. 유틸리티 아래의 필수 빠른 R-CNN DLL 파일은 해당 버전에 대해 미리 빌드되어 있기 때문이다. 작업에 다른 Python 버전을 사용해야 하는 경우 올바른 환경에서 이러한 DLL 파일을 직접 다시 컴파일하세요( 아래 참조).
이 자습서에서는 cntk.exe 있는 폴더가 PATH 환경 변수에 있다고 가정합니다. (PATH에 폴더를 추가하려면 명령줄에서 다음 명령을 실행할 수 있습니다(컴퓨터에 cntk.exe 있는 폴더가 C:\src\CNTK\x64\Release set PATH=C:\src\CNTK\x64\Release;%PATH%라고 가정). .)
경계 상자 회귀 및 최대값이 아닌 억제를 위해 미리 컴파일된 이진 파일
폴더 Examples\Image\Detection\FastRCNN\BrainScript\fastRCNN\utils 에는 빠른 R-CNN을 실행하는 데 필요한 미리 컴파일된 이진 파일이 포함되어 있습니다. 현재 리포지토리에 포함된 버전은 모두 64비트인 Python 3.5 및 3.6입니다. 다른 버전이 필요한 경우 다음 단계에 따라 컴파일할 수 있습니다.
git clone --recursive https://github.com/rbgirshick/fast-rcnn.gitcd $FRCN_ROOT/libmake- 대신
make동일한 폴더에서 실행할python setup.py build_ext --inplace수 있습니다. Windows에서는 lib/setup.py에서 추가 컴파일 인수를 주석으로 처리해야 할 수 있습니다.
ext_modules = [ Extension( "utils.cython_bbox", ["utils/bbox.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ), Extension( "utils.cython_nms", ["utils/nms.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ) ]- 대신
생성된
cython_bbox이진 파일과cython_nms이진 파일을$FRCN_ROOT/lib/utils복사합니다$CNTK_ROOT/Examples/Image/Detection/fastRCNN/utils.
예제 데이터 및 기준 모델
Fast-R-CNN 학습의 기초로 미리 학습된 AlexNet 모델을 사용합니다. 미리 학습된 AlexNet은 .에서 https://www.cntk.ai/Models/AlexNet/AlexNet.model사용할 수 있습니다. 에 모델을 $CNTK_ROOT/PretrainedModels저장하세요. 데이터를 다운로드하려면 를 실행하세요.
python install_grocery.py
폴더에서 Examples/Image/DataSets/Grocery
토이 예제 실행
토이 예제에서는 CNTK Fast R-CNN 모델을 학습하여 냉장고에서 식료품 항목을 검색합니다.
모든 필수 스크립트가 있습니다 $CNTK_ROOT/Examples/Image/Detection/FastRCNN/BrainScript.
빠른 가이드
토이 예제를 실행하려면 in이 PARAMETERS.pydataset .로 설정되어 있는지 확인합니다 "Grocery".
- 실행
A1_GenerateInputROIs.py하여 학습 및 테스트에 대한 입력 ROI를 생성합니다. - 실행
A2_RunWithBSModel.py하여 cntk.exe 및 BrainScript를 사용하여 학습하고 테스트합니다. - 실행
A3_ParseAndEvaluateOutput.py하여 학습된 모델의 mAP(평균 평균 정밀도)를 계산합니다.
스크립트 A3의 출력에는 다음이 포함되어야 합니다.
Evaluating detections
AP for avocado = 1.0000
AP for orange = 1.0000
AP for butter = 1.0000
AP for champagne = 1.0000
AP for eggBox = 0.7500
AP for gerkin = 1.0000
AP for joghurt = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
AP for onion = 1.0000
AP for pepper = 1.0000
AP for tomato = 0.7600
AP for water = 0.5000
AP for milk = 1.0000
AP for tabasco = 1.0000
AP for mustard = 1.0000
Mean AP = 0.9173
DONE.
실행할 B3_VisualizeOutputROIs.py 수 있는 경계 상자 및 예측 레이블을 시각화하려면(확대할 이미지를 클릭)





단계 세부 정보
A1: 스크립트 A1_GenerateInputROIs.py 는 먼저 선택적 검색을 사용하여 각 이미지에 대한 ROI 후보를 생성합니다.
그런 다음 CNTK 텍스트 형식 에 대한 입력 cntk.exe으로 저장합니다.
또한 이미지 및 접지 진리 레이블에 필요한 CNTK 입력 파일이 생성됩니다.
스크립트는 폴더 아래에 FastRCNN 다음 폴더 및 파일을 생성합니다.
proc- 생성된 콘텐츠의 루트 폴더입니다.grocery_2000- ROI를 사용하는2000예제에 대해grocery생성된 모든 폴더와 파일을 포함합니다. 다른 수의 ROI로 다시 실행하면 폴더 이름이 그에 따라 변경됩니다.rois- 텍스트 파일에 저장된 각 이미지에 대한 원시 ROI 좌표를 포함합니다.cntkFiles- 이미지(및), ROI 좌표(train.txt) 및test.txtROI 레이블xx.roilabels.txt(xx.rois.txt)에 대한traintest형식이 지정된 CNTK 입력 파일을 포함합니다. (서식 세부 정보는 아래에 나와 있습니다.)
모든 매개 변수가 포함 PARAMETERS.py됩니다( 예: 학습 및 테스트에 사용되는 ROI 수를 설정하기 위한 변경 cntk_nrRois = 2000 ). 아래 매개 변수 섹션의 매개 변수 에 대해 설명합니다.
A2: 스크립트 A2_RunWithBSModel.py 는 cntk.exe 및 BrainScript 구성 파일(구성 세부 정보)을 사용하여 cntk를 실행합니다.
학습된 모델은 해당 proc 하위 폴더의 폴더 cntkFiles/Output 에 저장됩니다.
학습된 모델은 학습 집합과 테스트 집합 모두에서 개별적으로 테스트됩니다.
각 이미지 및 해당 ROI에 대해 테스트하는 동안 레이블이 예측되고 파일 test.z 및 train.z 폴더에 cntkFiles 저장됩니다.
A3: 평가 단계에서는 CNTK 출력을 구문 분석하고 예측 결과를 지상 진리 주석과 비교하여 mAP 를 계산합니다.
최대값이 아닌 표시 안 함 은 겹치는 ROI를 병합하는 데 사용됩니다. 최대 PARAMETERS.py 값이 아닌 억제에 대한 임계값을 설정할 수 있습니다(세부 정보).
추가 스크립트
데이터를 시각화하고 분석하기 위해 실행할 수 있는 세 가지 선택적 스크립트가 있습니다.
B1_VisualizeInputROIs.py후보 입력 ROI를 시각화합니다.B2_EvaluateInputROIs.py는 후보 ROI와 관련하여 지상 진리 ROI의 회수를 계산합니다.B3_VisualizeOutputROIs.py경계 상자 및 예측 레이블을 시각화합니다.
Pascal VOC 실행
Pascal VOC(PASCAL Visual Object Classs) 데이터는 개체 클래스 인식에 대해 잘 알려진 표준화된 이미지 집합입니다. Pascal VOC 데이터에서 CNTK Fast R-CNN을 학습하거나 테스트하려면 RAM이 4GB 이상인 GPU가 필요합니다. 또는 CPU를 사용하여 실행할 수 있지만 다소 시간이 걸립니다.
Pascal VOC 데이터 가져오기
2007(trainval 및 test) 및 2012(trainval) 데이터뿐만 아니라 원래 논문에 사용된 사전 계산된 ROI가 필요합니다.
아래에 설명된 폴더 구조를 따라야 합니다.
스크립트는 파스칼 데이터가 상주한다고 가정합니다 $CNTK_ROOT/Examples/Image/DataSets/Pascal.
다른 폴더를 사용하는 경우 해당 폴더에 PARAMETERS.py 설정 pascalDataDir 하세요.
- 2012 학습 데이터 다운로드 및 압축 풀기
DataSets/Pascal/VOCdevkit2012 - 2007 학습 데이터 다운로드 및 압축 풀기
DataSets/Pascal/VOCdevkit2007 - 동일한 폴더에 2007 테스트 데이터 다운로드 및 압축 풀기
DataSets/Pascal/VOCdevkit2007 - 사전 계산된 ROI를 다운로드하여 압축을 풉
DataSets/Pascal/selective_search_data* http://dl.dropboxusercontent.com/s/orrt7o6bp6ae0tc/selective_search_data.tgz?dl=0
폴더는 VOCdevkit2007 다음과 같습니다(2012년과 유사).
VOCdevkit2007/VOC2007
VOCdevkit2007/VOC2007/Annotations
VOCdevkit2007/VOC2007/ImageSets
VOCdevkit2007/VOC2007/JPEGImages
파스칼 VOC에서 CNTK 실행
To run on the Pascal VOC data make sure that in PARAMETERS.pydataset is set to "pascal".
- 실행
A1_GenerateInputROIs.py하여 다운로드한 ROI 데이터에서 학습 및 테스트할 CNTK 형식의 입력 파일을 생성합니다. - 빠른 R-CNN 모델 및 컴퓨팅 테스트 결과를 학습하려면 실행
A2_RunWithBSModel.py합니다. - 실행
A3_ParseAndEvaluateOutput.py하여 학습된 모델의 mAP(평균 평균 정밀도)를 계산합니다.- 이 작업은 진행 중이며 새 기준 모델을 학습할 때 결과는 예비입니다.
- 인코딩 오류를 방지하려면 fastRCNN/pascal_voc.py 및 fastRCNN/voc_eval.py 파일에 대한 CNTK 마스터의 최신 버전이 있어야 합니다.
사용자 고유의 데이터 학습
사용자 지정 데이터 세트 준비
옵션 #1: 시각적 개체 태그 지정 도구(권장)
VOTT(Visual Object Tagging Tool)는 비디오 및 이미지 자산에 태그를 지정하기 위한 플랫폼 간 주석 도구입니다.

VOTT는 다음과 같은 기능을 제공합니다.
- Camshift 추적 알고리즘을 사용하여 비디오의 개체에 대한 컴퓨터 지원 태그 지정 및 추적
- 개체 검색 모델을 학습하기 위해 태그 및 자산을 CNTK Fast-RCNN 형식으로 내보냅니다.
- 새 비디오에서 학습된 CNTK 개체 검색 모델을 실행하고 유효성을 검사하여 더 강력한 모델을 생성합니다.
VOTT로 주석을 추가하는 방법:
옵션 #2: 주석 스크립트 사용
사용자 고유의 데이터 집합에서 CNTK Fast R-CNN 모델을 학습하기 위해 이미지에 직사각형 영역에 주석을 달고 이러한 지역에 레이블을 할당하는 두 개의 스크립트를 제공합니다.
스크립트는 빠른 R-CNN(A1_GenerateInputROIs.py)을 실행하는 첫 번째 단계에서 필요에 따라 주석을 올바른 형식으로 저장합니다.
먼저 다음 폴더 구조에 이미지를 저장합니다.
<your_image_folder>/negative- 개체를 포함하지 않는 학습에 사용되는 이미지<your_image_folder>/positive- 개체를 포함하는 학습에 사용되는 이미지<your_image_folder>/testImages- 개체를 포함하는 테스트에 사용되는 이미지
음수 이미지의 경우 주석을 만들 필요가 없습니다. 다른 두 폴더의 경우 제공된 스크립트를 사용합니다.
- 실행
C1_DrawBboxesOnImages.py하여 이미지에 경계 상자를 그립니다.- 실행하기 전에 스크립트 집합
imgDir = <your_image_folder>(/positive또는/testImages)에서 - 마우스 커서를 사용하여 주석을 추가합니다. 이미지의 모든 개체에 주석이 추가되면 키 'n'을 누르면 .bboxes.txt 파일이 기록되고 다음 이미지로 이동하면 'u'는 마지막 사각형을 실행 취소(즉, 제거)하고 'q'는 주석 도구를 종료합니다.
- 실행하기 전에 스크립트 집합
- 실행
C2_AssignLabelsToBboxes.py하여 경계 상자에 레이블을 할당합니다.- 실행하기 전에 스크립트 집합
imgDir = <your_image_folder>(/positive또는/testImages)에서... - ... 개체 범주를 반영하도록 스크립트의 클래스 를 조정합니다. 예를 들면 다음과 같습니다
classes = ("dog", "cat", "octopus"). - 스크립트는 각 이미지에 대해 수동으로 주석이 추가된 직사각형을 로드하고, 하나씩 표시하며, 창 왼쪽에 있는 해당 단추를 클릭하여 개체 클래스를 제공하도록 사용자에게 요청합니다. "미정" 또는 "제외"로 표시된 지상 진리 주석은 추가 처리에서 완전히 제외됩니다.
- 실행하기 전에 스크립트 집합
사용자 지정 데이터 세트 학습
스크립트 A1-A3을 사용하여 CNTK Fast R-CNN을 실행하기 전에 다음으로 데이터 집합을 PARAMETERS.py추가해야 합니다.
dataset = "CustomDataset"설정- Python 클래스
CustomDataset아래에 데이터 집합에 대한 매개 변수를 추가합니다. 매개 변수를 복사하여 시작할 수 있습니다.GroceryParameters- 개체 범주 를 반영하도록 클래스를 조정합니다. 위의 예제에 따르면 다음과 같습니다
self.classes = ('__background__', 'dog', 'cat', 'octopus'). self.imgDir = <your_image_folder>을 설정합니다.- 선택적으로 더 많은 매개 변수(예: ROI 생성 및 정리)를 조정할 수 있습니다( 매개 변수 섹션 참조).
- 개체 범주 를 반영하도록 클래스를 조정합니다. 위의 예제에 따르면 다음과 같습니다
사용자 고유의 데이터를 학습할 준비가 완료되었습니다. (토이 예제와 동일한 단계를 사용합니다.)
기술 세부 정보
매개 변수
의 주요 매개 변수는 다음과 같습니다.PARAMETERS.py
dataset- 사용할 데이터 집합cntk_nrRois- 학습 및 테스트에 사용할 ROI 수nmsThreshold- 최대값이 아닌 억제 임계값(범위 [0,1]) 낮을수록 더 많은 ROI가 결합됩니다. 평가 및 시각화 모두에 사용됩니다.
최소 및 최대 너비 및 높이 등 ROI 생성에 대한 모든 매개 변수는 Python 클래스 Parameters아래에 설명 PARAMETERS.py 되어 있습니다. 모두 적절한 기본값으로 설정됩니다.
사용 중인 데이터 집합에 # project-specific parameters 해당하는 섹션에서 덮어쓸 수 있습니다.
CNTK 구성
빠른 R-CNN을 학습하고 테스트하는 데 사용되는 CNTK BrainScript 구성 파일은 fastrcnn.cntk입니다.
네트워크를 생성하는 부분은 명령의 BrainScriptNetworkBuilder 섹션 Train 입니다.
BrainScriptNetworkBuilder = {
network = BS.Network.Load ("../../../../../../../PretrainedModels/AlexNet.model")
convLayers = BS.Network.CloneFunction(network.features, network.conv5_y, parameters = "constant")
fcLayers = BS.Network.CloneFunction(network.pool3, network.h2_d)
model (features, rois) = {
featNorm = features - 114
convOut = convLayers (featNorm)
roiOut = ROIPooling (convOut, rois, (6:6))
fcOut = fcLayers (roiOut)
W = ParameterTensor{($NumLabels$:4096), init="glorotUniform"}
b = ParameterTensor{$NumLabels$, init = 'zero'}
z = W * fcOut + b
}.z
imageShape = $ImageH$:$ImageW$:$ImageC$ # 1000:1000:3
labelShape = $NumLabels$:$NumTrainROIs$ # 21:64
ROIShape = 4:$NumTrainROIs$ # 4:64
features = Input {imageShape}
roiLabels = Input {labelShape}
rois = Input {ROIShape}
z = model (features, rois)
ce = CrossEntropyWithSoftmax(roiLabels, z, axis = 1)
errs = ClassificationError(roiLabels, z, axis = 1)
featureNodes = (features:rois)
labelNodes = (roiLabels)
criterionNodes = (ce)
evaluationNodes = (errs)
outputNodes = (z)
}
첫 번째 줄에서 미리 학습된 AlexNet이 기본 모델로 로드됩니다. 네트워크의 다음 두 부분이 복제 convLayers 됩니다. 즉, 더 이상 학습되지 않는 일정한 가중치를 가진 나선형 계층을 포함합니다.
fcLayers 에는 미리 학습된 가중치가 있는 완전히 연결된 계층이 포함되어 있으며, 이 계층은 추가로 학습됩니다.
노드 이름 network.featuresnetwork.conv5_y 등은 스크립트의 로그 출력에 포함된 cntk.exe 호출의 A2_RunWithBSModel.py 로그 출력을 확인하여 파생될 수 있습니다.
모델 정의(model (features, rois) = ...)는 먼저 각 채널 및 픽셀에 대해 114를 빼서 기능을 정규화합니다.
그런 다음 정규화된 기능이 푸시된 다음, ROIPooling 마지막으로 fcLayers..를 통해 convLayers 푸시됩니다.
ROI 풀링 계층의 출력 셰이프(width:height)는 AlexNet 모델에서 미리 학습된 fcLayers 셰이프 nd 크기이므로 설정 (6:6) 됩니다. 출력 fcLayers 은 각 ROI에 대해 레이블당 하나의 값(NumLabels)을 예측하는 조밀한 계층으로 공급됩니다.
다음 여섯 줄은 입력을 정의합니다.
- 크기 1000 x 1000 x 3(
$ImageH$:$ImageW$:$ImageC$)의 이미지 - 각 ROI에 대한 접지 진리 레이블(
$NumLabels$:$NumTrainROIs$) - 및 이미지의 전체 너비 및 높이와 관련하여 모든 상대(x, y, w, h)에 해당하는 ROI(
4:$NumTrainROIs$)당 4개의 좌표입니다.
z = model (features, rois) 는 입력 이미지 및 ROI를 정의된 네트워크 모델에 공급하고 출력 z을 할당합니다.
ROI당 예측 오류를 고려하여 기준(CrossEntropyWithSoftmax) 및 오류(ClassificationError)를 모두 지정 axis = 1 합니다.
CNTK 구성의 판독기 섹션은 아래에 나열되어 있습니다. 세 개의 역직렬 변환기를 사용합니다.
ImageDeserializer이미지 데이터를 읽습니다. 이미지 파일 이름을train.txt선택하고 가로 세로 비율을 유지하면서 이미지를 원하는 너비 및 높이로 조정하고(빈 영역을 빈 영역으로114패딩) 올바른 입력 셰이프를 갖도록 텐서를 바꿉니다.- 에서
CNTKTextFormatDeserializerROI 좌표를 읽을 수 있습니다train.rois.txt. - 에서 ROI 레이블을 읽는 데
train.roislabels.txt1초CNTKTextFormatDeserializer
입력 파일 형식은 다음 섹션에서 설명합니다.
reader = {
randomize = false
verbosity = 2
deserializers = ({
type = "ImageDeserializer" ; module = "ImageReader"
file = train.txt
input = {
features = { transforms = (
{ type = "Scale" ; width = $ImageW$ ; height = $ImageW$ ; channels = $ImageC$ ; scaleMode = "pad" ; padValue = 114 }:
{ type = "Transpose" }
)}
ignored = {labelDim = 1000}
}
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.rois.txt
input = { rois = { dim = $TrainROIDim$ ; format = "dense" } }
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.roilabels.txt
input = { roiLabels = { dim = $TrainROILabelDim$ ; format = "dense" } }
})
}
CNTK 입력 파일 형식
위에서 설명한 3개의 역직렬 변환자에 해당하는 CNTK Fast R-CNN에 대한 세 개의 입력 파일이 있습니다.
train.txt에는 먼저 각 줄에 시퀀스 번호, 이미지 파일 이름 및 마지막으로0(현재 ImageReader의 레거시 이유로 여전히 필요)가 포함됩니다.
0 image_01.jpg 0
1 image_02.jpg 0
...
train.rois.txt(CNTK 텍스트 형식)에는 먼저 각 줄에 시퀀스 번호가 포함된 다음|rois, 식별자 다음에 숫자 시퀀스가 포함됩니다. 이들은 ROI의 (x, y, w, h)에 해당하는 4개의 숫자로 구성된 그룹으로, 이미지의 전체 너비 및 높이와 관련하여 모두 상대적입니다. 줄당 총 4 * rois 번호가 있습니다.
0 |rois 0.2185 0.0 0.165 0.29 ...
train.roilabels.txt(CNTK 텍스트 형식)에는 먼저 각 줄에 시퀀스 번호가 포함된 다음|roiLabels, 식별자 다음에 숫자 시퀀스가 포함됩니다. 이들은 하나의 핫 표현으로 접지 진리 클래스를 인코딩하는 ROI당 레이블 수 숫자(0 또는 1)의 그룹입니다. 줄당 총 레이블 수 * rois 수입니다.
0 |roiLabels 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
알고리즘 세부 정보
빠른 R-CNN
개체 감지를 위한 R-CNN은 2014년 Ross Girshick 등에 의해 처음 발표되었으며, 파스칼 VOC라는 분야의 주요 개체 인식 과제 중 하나에서 이전의 최첨단 접근 방식을 능가하는 것으로 나타났습니다. 그 이후로 빠른 R-CNN 과 빠른 R-CNN의 상당한 속도 향상을 포함하는 두 가지 후속 논문이 발표되었습니다.
R-CNN의 기본 개념은 원래 수백만 개의 주석이 추가된 이미지를 사용하여 이미지 분류를 위해 학습된 심층 신경망을 사용하고 개체 감지를 위해 수정하는 것입니다. 첫 번째 R-CNN 논문의 기본 아이디어는 아래 그림(논문에서 가져온 그림)에 나와 있습니다. (1) 입력 이미지를 지정하면 첫 번째 단계에서 (2) 많은 수의 지역 제안이 생성됩니다. (3) 이러한 지역 제안 또는 ROI(관심 지역)는 각 ROI에 대해 4096 부동 소수점 값의 벡터를 출력하는 네트워크를 통해 각각 독립적으로 전송됩니다. 마지막으로, (4) 4096 float ROI 표현을 입력으로 사용하고 각 ROI에 레이블과 신뢰도를 출력하는 분류자를 학습합니다.
이 방법은 정확도 측면에서는 잘 작동하지만 신경망이 각 ROI에 대해 평가되어야 하므로 컴퓨팅 비용이 매우 많이 듭니다. 빠른 R-CNN은 이미지당 단일 시간(특정: 나선형 계층)의 대부분만 평가하여 이러한 단점을 해결합니다. 저자에 따르면, 이것은 테스트 하는 동안 213 배 속도 및 정확도 손실 없이 훈련 하는 동안 9 배 속도. 이는 ROI를 나선형 기능 맵에 투영하고 최대 풀링을 수행하여 다음 계층에서 예상하는 원하는 출력 크기를 생성하는 ROI 풀링 계층을 사용하여 수행됩니다. 이 자습서에 사용된 AlexNet 예제에서 ROI 풀링 계층은 마지막 나선형 계층과 완전히 연결된 첫 번째 계층 사이에 배치됩니다( BrainScript 코드 참조).
R-CNN 논문에 사용된 원래 Caffe 구현은 GitHub( RCNN, Fast R-CNN 및 더 빠른 R-CNN)에서 찾을 수 있습니다. 이 자습서에서는 SVM 학습 및 모델 평가를 위해 이러한 리포지토리의 일부 코드를 사용합니다.
SVM 및 NN 학습
Patrick Buehler는 CNTK Fast R-CNN 출력(마지막으로 완전히 연결된 계층의 4096 기능 사용)에서 SVM을 학습시키는 방법에 대한 지침과 여기에 장단점을 설명합니다.
선택적 검색
선택적 검색 은 실제 개체의 클래스와 관계없이 이미지에서 가능한 개체 위치의 큰 집합을 찾는 방법입니다. 이미지 픽셀을 세그먼트로 클러스터링한 다음 계층적 클러스터링을 수행하여 동일한 개체의 세그먼트를 개체 제안으로 결합합니다.



선택적 검색에서 검색된 ROI를 보완하기 위해 여러 눈금 및 가로 세로 비율로 이미지를 균일하게 커버하는 ROI를 추가합니다. 첫 번째 이미지는 가능한 각 개체 위치가 녹색 사각형으로 시각화되는 선택적 검색의 예제 출력을 보여줍니다. 너무 작고 너무 큰 ROI는 삭제되고(두 번째 이미지) 마지막으로 이미지를 균일하게 덮는 ROI가 추가됩니다(세 번째 이미지). 그런 다음 이러한 사각형은 R-CNN 파이프라인에서 ROI(관심 영역)로 사용됩니다.
ROI 생성의 목표는 이미지에서 가능한 한 많은 개체를 단단히 덮는 작은 ROI 집합을 찾는 것입니다. 이 계산은 충분히 빨라야 하며 동시에 서로 다른 배율 및 가로 세로 비율로 개체 위치를 찾아야 합니다. 선택적 검색은 이 작업에 대해 잘 수행되는 것으로 나타났으며, 절차 속도를 높이기 위해 정확도가 우수합니다.
NMS(최대 비표시)
개체 검색 방법은 이미지에서 동일한 개체를 완전히 또는 부분적으로 포함하는 여러 검색을 출력하는 경우가 많습니다.
개체 수를 계산하고 이미지에서 정확한 위치를 얻으려면 이러한 ROI를 병합해야 합니다.
이 작업은 일반적으로 NMS(Non Maximum Suppression)라는 기술을 사용하여 수행됩니다. 사용하는 NMS 버전(R-CNN 게시에서도 사용됨)은 ROI를 병합하지 않고 개체의 실제 위치를 가장 잘 다루는 ROI를 식별하려고 시도하며 다른 모든 ROI를 삭제합니다. 이는 신뢰도가 가장 높은 ROI를 반복적으로 선택하고 이 ROI와 상당히 겹치고 동일한 클래스로 분류되는 다른 모든 ROI를 제거하여 구현됩니다. 겹침 임계값을 설정할 PARAMETERS.py 수 있습니다(세부 정보).
감지 결과 앞(첫 번째 이미지) 및 이후(두 번째 이미지) 최대값이 아닌 표시 안 함:

mAP(평균 평균 정밀도)
일단 학습되면 정밀도, 재현율, 정확도, 영역 아래 곡선 등과 같은 다양한 조건을 사용하여 모델의 품질을 측정할 수 있습니다. Pascal VOC 개체 인식 챌린지에 사용되는 일반적인 메트릭은 각 클래스에 대한 AP(Average Precision)를 측정하는 것입니다. 평균 정밀도에 대한 다음 설명은 에버링엄 외에서 가져온 것입니다. 평균 평균 정밀도(mAP)는 모든 클래스의 AP에 대한 평균을 계산하여 계산됩니다.
지정된 작업 및 클래스의 경우 정밀도/재현율 곡선은 메서드의 순위가 지정된 출력에서 계산됩니다. 재현율은 지정된 순위보다 높은 모든 긍정 예제의 비율로 정의됩니다. 전체 자릿수는 양수 클래스의 순위 위에 있는 모든 예제의 비율입니다. AP는 정밀도/재현율 곡선의 모양을 요약하고 11개의 동일한 간격의 회수 수준 [0,0.1, 집합에서 평균 정밀도로 정의됩니다. . . ,1]:
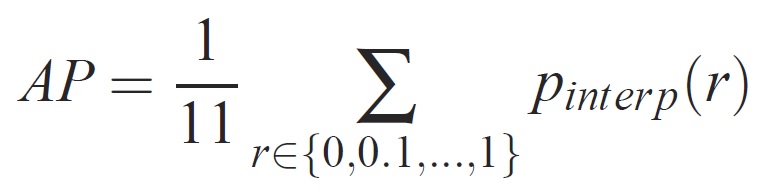
각 회수 수준 r의 정밀도는 해당 회수가 r을 초과하는 메서드에 대해 측정된 최대 정밀도를 사용하여 보간됩니다.
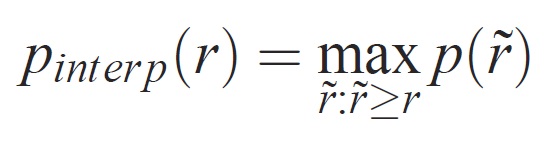
여기서 p( 1r)는 리콜 시 측정된 정밀도입니다. 이러한 방식으로 정밀도/재현율 곡선을 보간하려는 의도는 예제 순위의 작은 변화로 인한 정밀도/재현율 곡선에서 "흔들기"의 영향을 줄이는 것입니다. 높은 점수를 얻으려면 메서드가 모든 수준의 재현율에 정밀도를 가져야 합니다. 이렇게 하면 정밀도가 높은 예제의 하위 집합(예: 자동차의 측면 보기)만 검색하는 메서드가 처벌됩니다.