여러 GPU 및 컴퓨터
1. 소개
CNTK는 현재 다음과 같은 4개의 병렬 SGD 알고리즘을 지원합니다.
필수 구성 요소
병렬 학습을 실행하려면 MPI(메시지 전달 인터페이스)의 구현이 설치되어 있는지 확인합니다.
Windows에서는 페이지 제목에 단순히 "버전 7"로 표시된 이 다운로드 페이지에서 메시지 전달 인터페이스 표준의 Microsoft 구현인 Microsoft MPI(MS-MPI) 버전 7(7.0.12437.6)을 설치합니다. 다운로드 단추를 클릭한 다음 런타임(
MSMpiSetup.exe)을 선택합니다.Linux에서 OpenMPI 버전 1.10.x를 설치합니다. 여기에 있는 지침에 따라 직접 빌드하세요.
2. Python에서 CNTK에서 병렬 학습 구성
Python에서 데이터 병렬 SGD를 사용하려면 사용자는 분산 학습자를 만들고 트레이너에게 전달해야 합니다.
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
사용자 정의 학습 루프의 경우(training_session 대신) 사용자는 다른 MPI 노드가 num_data_partitionspartition_indexMinibatchSource.next_minibatch() 다른 데이터 파티션에서 데이터를 읽을 수 있도록(샘플을 읽은 후 distributed_after ) 메서드에 전달해야 합니다.
분산 학습이 Communicator.finalize() 성공적으로 완료된 경우에만 호출해야 합니다. 분산 작업자가 실패하는 경우 이 메서드를 호출하면 안 됩니다.
완벽하게 작동하는 예제는 ConvNet 예제를 참조하세요.
3. BrainScript에서 CNTK에서 병렬 학습 구성
CNTK BrainScript에서 병렬 학습을 사용하도록 설정하려면 먼저 구성 파일 또는 명령줄에서 다음 스위치를 켜야 합니다.
parallelTrain = true
둘째, 구성 파일의 SGD 블록에는 다음 인수가 포함된 ParallelTrain 하위 블록이 포함되어야 합니다.
parallelizationMethod: (필수) 합법적인 값은DataParallelSGD,BlockMomentumSGD및ModelAveragingSGD.사용할 병렬 알고리즘을 지정합니다.
distributedMBReading: (선택 사항) 부울 값을true허용합니다. 또는false; 기본값은 입니다.false각 작업자의 I/O 비용을 최소화하려면 분산 미니배치 읽기를 켜는 것이 좋습니다. CNTK 텍스트 형식 판독기, 이미지 판독기 또는 복합 데이터 판독기를 사용하는 경우 distributedMBReading을 true로 설정해야 합니다.
parallelizationStartEpoch: (선택 사항) 정수 값을 허용합니다. 기본값은 1입니다.이는 Epoch, 병렬 학습 알고리즘이 사용되는 시작부터 지정합니다. 그 전에는 모든 작업자가 동일한 교육을 수행하지만 한 명의 작업자만 모델을 저장할 수 있습니다. 이 옵션은 병렬 학습에 "웜 시작" 단계가 필요한 경우에 유용할 수 있습니다.
syncPerfStats: (선택 사항) 정수 값을 허용합니다. 기본값은 0입니다.성능 통계가 인쇄되는 빈도를 지정합니다. 이러한 통계에는 병렬 학습 알고리즘의 병목 상태를 이해하는 데 유용할 수 있는 동기화 기간의 통신 및/또는 계산에 소요된 시간이 포함됩니다.
0은 통계가 인쇄되지 않음을 의미합니다. 다른 값은 통계가 인쇄되는 빈도를 지정합니다. 예를 들어
syncPerfStats=55개의 동기화마다 통계가 출력됨을 의미합니다.각 병렬 학습 알고리즘의 세부 정보를 지정하는 하위 블록입니다. 하위 블록의 이름은 같아야 합니다
parallelizationMethod. (필수)
Python은 더 많은 유연성을 제공하며 다양한 병렬화 방법에 대한 사용법이 아래에 나와 있습니다.
4. CNTK를 사용하여 병렬 학습 실행
CNTK의 병렬 처리는 MPI를 사용하여 구현됩니다.
4.1 BrainScript를 사용하여 병렬 학습 실행
위의 병렬 학습 BrainScript 구성을 고려할 때 다음 명령을 사용하여 병렬 MPI 작업을 시작할 수 있습니다.
Linux를 사용하여 동일한 컴퓨터에서 병렬 학습:
mpiexec --npernode $num_workers $cntk configFile=$configWindows를 사용하는 동일한 컴퓨터에서 병렬 학습:
mpiexec -n %num_workers% %cntk% configFile=%config%Linux를 사용하여 여러 컴퓨팅 노드에서 병렬 학습:
1단계: 즐겨 찾는 편집기를 사용하여 호스트 파일 $hostfile 만들기
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
여기서 name_of_node(n)은 단순히 작업자 노드의 DNS 이름 또는 IP 주소입니다.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile $cntk configFile=$config
```
Windows를 사용하는 여러 컴퓨팅 노드에서 병렬 학습:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... %cntk% configFile=%config%
여기서 $cntk CNTK 실행 파일의 경로를 참조해야 합니다($x Linux 셸의 환경 변수를 대체하는 방법은 Windows 셸에 해당 %x% ).
4.2 Python을 사용하여 병렬 학습 실행
Python을 사용하는 CNTK v2에 대한 분산 학습 예제는 다음에서 찾을 수 있습니다.
CNTK v2 Python 스크립트 training.py 가 제공되면 다음 명령을 사용하여 병렬 MPI 작업을 시작할 수 있습니다.
Linux를 사용하여 동일한 컴퓨터에서 병렬 학습:
mpiexec --npernode $num_workers python training.pyWindows를 사용하는 동일한 컴퓨터에서 병렬 학습:
mpiexec -n %num_workers% python training.pyLinux를 사용하여 여러 컴퓨팅 노드에서 병렬 학습:
1단계: 즐겨 찾는 편집기를 사용하여 호스트 파일 $hostfile 만들기
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
여기서 name_of_node(n)은 단순히 작업자 노드의 DNS 이름 또는 IP 주소입니다.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile python training.py
```
Windows를 사용하는 여러 컴퓨팅 노드에서 병렬 학습:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... python training.py
5개 Data-Parallel 1비트 SGD를 사용하여 학습
CNTK는 1비트 SGD 기술 [1]을 구현합니다. 이 기술을 사용하면 각 미니배치를 작업자에게 K 배포할 수 있습니다. 그러면 결과 부분 그라데이션이 각 미니배치 후에 교환되고 집계됩니다. "1비트"는 각 그라데이션 값에 대해 교환되는 데이터의 양을 단일 비트로 줄이기 위해 Microsoft에서 개발된 기술을 나타냅니다.
5.1 "1비트 SGD" 알고리즘
각 미니배치 후에 부분 그라데이션을 직접 교환하려면 엄청난 통신 대역폭이 필요합니다. 이 문제를 해결하기 위해 1비트 SGD는 각 그라데이션 값을 적극적으로 정량화합니다... 값당 단일 비트(!)로 지정합니다. 실제로 이는 큰 그라데이션 값이 잘리는 반면 작은 값은 인위적으로 팽창됨을 의미합니다. 놀랍게도, 트릭 이 사용되는 경우에만 수렴에 해를 끼치지 않습니다.
각 미니배치에 대해 알고리즘은 정량화된 그라데이션(작업자 간에 교환됨)을 원래 그라데이션 값(교환해야 하는)과 비교한다는 것입니다. 둘 사이의 차이( 양자화 오류)는 계산되고 잔차로 기억됩니다. 이 잔차는 다음 미니배치에 추가됩니다.
결과적으로, 적극적인 양자화에도 불구하고 각 그라데이션 값은 결국 전체 정확도로 교환됩니다. 그냥 지연. 실험에 따르면 이 모델이 웜 시작(병렬화 없이 학습 데이터의 작은 하위 집합에서 학습된 시드 모델)과 결합되는 한, 이 기술은 정확도의 손실이 없거나 매우 작은 것으로 나타났으며, 선형에서 너무 멀지 않은 속도를 허용하는 것으로 나타났습니다(너무 작은 하위 일괄 처리에서 컴퓨팅할 때 GPU가 비효율적이라는 제한 요인).
효율성을 극대화하기 위해 이 기술은 자동 미니배치 크기 조정과 결합되어야 하며, 이때마다 트레이너는 미니배치 크기를 늘리려고 합니다. 트레이너는 향후 데이터 Epoch의 작은 하위 집합을 평가하여 수렴에 해를 끼치지 않는 가장 큰 미니배치 크기를 선택합니다. 여기서는 CNTK가 미니배치 크기의 독립적인 방식으로 학습 속도 및 모멘텀 하이퍼 매개 변수를 지정하는 것이 편리합니다.
5.2 BrainScript에서 1비트 SGD 사용
1비트 SGD 자체에는 사용하도록 설정하는 것 외에는 매개 변수가 없으며 그 후에는 Epoch가 시작됩니다. 또한 자동 미니배치 크기 조정을 사용하도록 설정해야 합니다. 이러한 매개 변수는 SGD 블록에 다음 매개 변수를 추가하여 구성됩니다.
SGD = [
...
ParallelTrain = [
DataParallelSGD = [
gradientBits = 1
]
parallelizationStartEpoch = 2 # warm start: don't use 1-bit SGD for first epoch
]
AutoAdjust = [
autoAdjustMinibatch = true # enable automatic growing of minibatch size
minibatchSizeTuningFrequency = 3 # try to enlarge after this many epochs
]
]
Data-Parallel SGD는 1비트 양자화 없이도 사용할 수 있습니다. 그러나 일반적인 시나리오, 특히 각 모델 매개 변수가 피드 전달 DNN과 같이 한 번만 적용되는 시나리오에서는 통신 대역폭 요구가 높기 때문에 효율적이지 않습니다.
아래 섹션 2.2.3은 다음에 설명된 Block-Momentum SGD 메서드와 비교하여 음성 작업에서 1비트 SGD의 결과를 보여줍니다. 두 방법 모두 거의 선형 속도 향상 시 정확도가 거의 손실되지 않습니다.
5.3 Python에서 1비트 SGD 사용
Python에서 데이터 병렬 SGD를 사용하려면 필요에 따라 1비트 SGD를 사용하여 분산 학습자를 만들고 트레이너에게 전달해야 합니다.
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 1, # change to 32 for non-quantized gradient accumulation
distributed_after = distributed_after) # warm start: no parallelization is used for the first 'distributed_after' samples
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
distributed_learner 만드는 동안 num_quantization_bits 32로 변경하면 양자화되지 않은 Data-Parallel SGD를 사용합니다. 이 경우 웜 시작이 필요하지 않습니다.
6 Block-Momentum SGD
Block-Momentum SGD 는 "블록 모델 업데이트 및 필터링" 또는 BMUF 알고리즘, 짧은 블록 모멘텀 [2]의 구현입니다.
6.1 Block-Momentum SGD 알고리즘
다음 그림에서는 Block-Momentum 알고리즘의 절차를 요약합니다.

6.2 BrainScript에서 Block-Momentum SGD 구성
Block-Momentum SGD를 사용하려면 다음 옵션을 사용하여 블록에 SGD 이름이 지정된 BlockMomentumSGD 하위 블록이 있어야 합니다.
syncPeriod. 이는 모델 동기화가syncPeriod수행되는 빈도를 지정하는 inModelAveragingSGD과 유사합니다. 기본값BlockMomentumSGD은 120,000입니다.resetSGDMomentum. 즉, 모든 동기화 지점이 지나면 로컬 SGD에 사용되는 부드러운 그라데이션이 0으로 설정됩니다. 이 변수의 기본값은 true입니다.useNesterovMomentum. 즉, Nesterov 스타일 모멘텀 업데이트가 블록 수준에 적용됩니다. 자세한 내용은 [2]를 참조하세요. 이 변수의 기본값은 true입니다.
블록 모멘텀 및 블록 학습 속도는 일반적으로 사용되는 작업자 수(예:
block_momentum = 1.0 - 1.0/num_of_workers
block_learning_rate = 1.0
이 환경은 이러한 설정이 가장 큰 실험인 최대 64개의 GPU에 대한 표준 SGD 알고리즘과 유사한 수렴을 생성하는 경우가 많다는 것을 나타냅니다. 다음 옵션을 사용하여 이러한 매개 변수를 수동으로 지정할 수도 있습니다.
blockMomentumAsTimeConstant는 블록 수준 모델 업데이트에서 로우 패스 필터의 시간 상수입니다. 다음과 같이 계산됩니다.blockMomentumAsTimeConstant = -syncPeriod / log(block_momentum) # or inversely block_momentum = exp(-syncPeriod/blockMomentumAsTimeConstant)blockLearningRate는 블록 학습 속도를 지정합니다.
다음은 Block-Momentum SGD 구성 섹션의 예입니다.
learningRatesPerSample=0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
# Use it for BlockMomentumSGD as well
ParallelTrain = [
parallelizationMethod = BlockMomentumSGD
distributedMBReading = true
syncPerfStats = 5
BlockMomentumSGD=[
syncPeriod = 120000
resetSGDMomentum = true
useNesterovMomentum = true
]
]
6.3 BrainScript에서 Block-Momentum SGD 사용
1. 학습 매개 변수 다시 조정
작업자당 비슷한 처리량을 달성하려면 작업자 수에 비례하여 미니배치의 샘플 수를 늘려야 합니다. 이는 프레임 모드 임의화가 사용되는지 여부에 따라 조정하거나
nbruttsineachrecurrentiter조정minibatchSize하여 수행할 수 있습니다.학습 속도를 조정할 필요가 없습니다(Model-Averaging SGD와 달리 아래 참조).
웜 시작 모델에서 Block-Momentum SGD를 사용하는 것이 좋습니다. 음성 인식 작업에서 표준 SGD를 사용하여 24시간(860만 샘플)에서 120시간(4,320만 샘플) 데이터로 학습된 시드 모델부터 시작할 때 합리적인 수렴이 이루어집니다.
2. ASR 실험
Block-Momentum SGD 및 Data-Parallel(1비트) SGD 알고리즘을 사용하여 2600시간 음성 인식 작업에서 DNN 및 LSTM을 학습시키고 단어 인식 정확도와 속도 향상 요인을 비교했습니다. 다음 표와 그림에서는 결과(*)를 보여 줍니다.
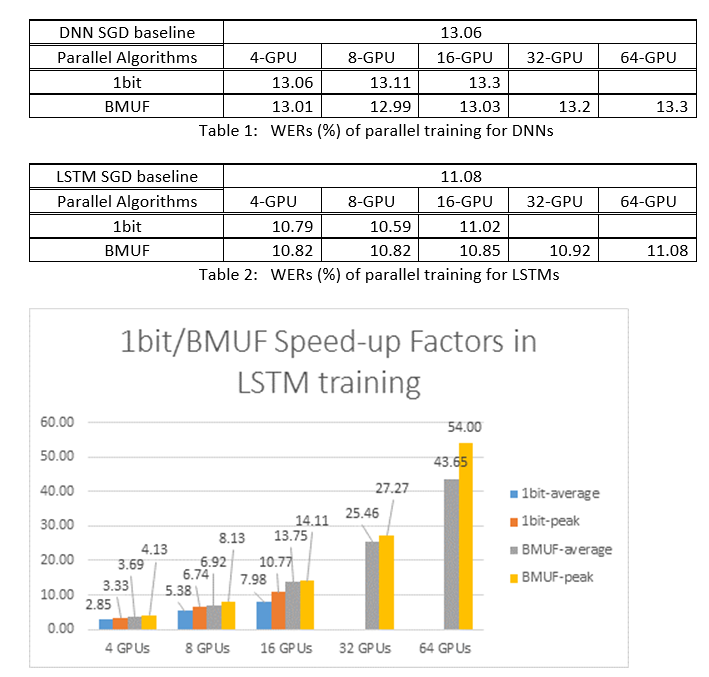
(*): 최대 속도 상승 계수: 1비트 SGD의 경우, 하나의 미니배치에서 달성된 최대 속도 상승 계수(SGD 기준과 비교)로 측정됩니다. 블록 모멘텀의 경우, 한 블록에서 달성된 최대 속도 향상으로 측정됩니다. 평균 속도 상승 계수: SGD 기준의 경과 시간을 관찰된 경과 시간으로 나눈 값입니다. 이러한 두 메트릭은 I/O의 대기 시간으로 인해 도입되었으며, 특히 동기화가 미니 일괄 처리 수준에서 수행되는 경우 평균 속도 상승 계수 측정에 큰 영향을 줄 수 있습니다. 동시에 최대 속도 상승 요소는 상대적으로 강력합니다.
3. 주의 사항
true로 설정하는
resetSGDMomentum것이 좋습니다. 그렇지 않으면 종종 학습 기준의 차이로 이어집니다. 모든 모델 동기화 후 SGD 모멘텀을 0으로 다시 설정하면 기본적으로 마지막 미니 배치의 기여도를 끊습니다. 따라서 큰 SGD 모멘텀을 사용하지 않는 것이 좋습니다. 예를 들어 120,000의 경우syncPeriodSGD에 사용되는 모멘텀이 0.99이면 상당한 정확도 손실을 관찰합니다. SGD 모멘텀을 0.9, 0.5로 줄이거나 모두 사용하지 않도록 설정하면 표준 SGD 알고리즘에서 달성할 수 있는 것과 비슷한 정확도를 제공합니다.Block-Momentum SGD는 이후 블록 간에 한 블록에서 모델 업데이트를 지연시키고 배포합니다. 따라서 모델 동기화가 학습에서 충분히 자주 수행되는지 확인해야 합니다. 빠른 검사는 .를 사용하는
blockMomentumAsTimeConstant것입니다. 고유 학습 샘플N의 수는 다음 수식을 충족하는 것이 좋습니다.N >= blockMomentumAsTimeConstant * num_of_workers ~= syncPeriod * num_of_workers^2
근사값은 다음과 같은 사실에서 비롯됩니다. (1) 블록 모멘텀은 종종 ;로 (1-1/num_of_workers)설정됩니다. (2) log(1-1/num_of_workers)~=-num_of_workers.
6.4 Python에서 Block-Momentum 사용
Python에서 Block-Momentum 사용하도록 설정하려면 1비트 SGD와 마찬가지로 사용자는 블록 모멘텀 분산 학습자를 만들고 트레이너에게 전달해야 합니다.
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_learner = cntk.distributed.block_momentum_distributed_learner(learner, block_size=block_size)
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
완벽하게 작동하는 예제는 ConvNet 예제를 참조하세요.
7 Model-Averaging SGD
모델 평균 SGD 는 자연 그라데이션을 사용하지 않고 [3,4]에 자세히 설명된 모델 평균 알고리즘의 구현입니다. 여기서는 각 작업자가 데이터의 하위 집합을 처리하지만 지정된 기간 후에 각 작업자의 모델 매개 변수 평균을 처리하도록 하는 것이 좋습니다.
Model-Averaging SGD는 일반적으로 1비트 SGD 및 Block-Momentum SGD에 비해 더 느리고 더 최적으로 수렴되므로 더 이상 권장되지 않습니다.
Model-Averaging SGD를 사용하려면 다음 옵션을 사용하여 블록에 SGD 이름이 지정된 ModelAveragingSGD 하위 블록이 있어야 합니다.
syncPeriod는 모델 평균을 수행하기 전에 각 작업자가 처리해야 하는 샘플 수를 지정합니다. 기본값은 40,000입니다.
7.1 BrainScript에서 Model-Averaging SGD 사용
Model-Averaging SGD를 최대한 효과적이고 효율적으로 만들려면 사용자가 몇 가지 하이퍼 매개 변수를 조정해야 합니다.
minibatchSize또는nbruttsineachrecurrentiter작업자가 Model-Averaging SGD 구성에 참여한다고 가정n해 보겠습니다. 현재 분산 읽기 구현은 미니배치의 -th를 각 작업자에 로드1/n합니다. 따라서 각 작업자가 표준 SGD와 동일한 처리량을 생성하도록 하려면 미니배치 크기n-fold를 확대해야 합니다. 프레임 모드 임의화를 사용하여 학습된 모델의 경우 시간별로n확대하여minibatchSize이를 달성할 수 있습니다. 모델의 경우 RNN과 같은 시퀀스 모드 임의화를 사용하여 학습되는 경우 일부 판독기를 대신 늘려nbruttsineachrecurrentitern야 합니다.learningRatesPerSample. 우리의 경험은 표준 SGD와 유사한 수렴을 얻으려면 시간을 늘려learningRatesPerSamplen야 한다는 것을 나타냅니다. 설명은 [2]에서 찾을 수 있습니다. 학습 속도가 증가하므로 학습이 서로 다른지 확인하기 위해 추가 주의가 필요하며 이는 실제로 Model-Averaging SGD의 주요 주의 사항입니다. 학습 기준의 증가가AutoAdjust관찰되는 경우 설정을 사용하여 이전 최상의 모델을 다시 로드할 수 있습니다.웜 시작. Model-Averaging SGD는 일반적으로 표준 SGD 알고리즘에 의해 학습된 시드 모델에서 시작하는 경우(병렬 처리 없이) 더 잘 수렴되는 것으로 나타났습니다. 음성 인식 작업에서 표준 SGD를 사용하여 24시간(860만 샘플)에서 120시간(4,320만 샘플) 데이터로 학습된 시드 모델부터 시작할 때 합리적인 수렴이 이루어집니다.
다음은 구성 섹션의 ModelAveragingSGD 예입니다.
learningRatesPerSample = 0.002
# increase the learning rate by 4 times for 4-GPU training.
# learningRatesPerSample = 0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
ParallelTrain = [
parallelizationMethod = ModelAveragingSGD
distributedMBReading = true
syncPerfStats = 20
ModelAveragingSGD = [
syncPeriod=40000
]
]
7.2 Python에서 Model-Averaging SGD 사용
진행 중인 작업입니다.
8 Data-Parallel 매개 변수 서버를 사용하여 학습
매개 변수 서버는 분산 기계 학습 [5][6][7]에서 널리 사용되는 프레임워크입니다. 가장 중요한 이점은 많은 작업자를 사용한 비동기 병렬 교육입니다. 매개 변수 서버를 분산 모델 저장소로 소개합니다. 매개 변수 서버 프레임워크는 AllReduce 기본 형식을 직접 활용하여 작업자 간에 매개 변수 업데이트를 동기화하는 대신 로컬 작업자가 매개 변수 서버에서 전역 매개 변수를 업데이트하고 검색할 수 있도록 "추가" 및 "가져오기"와 같은 인터페이스를 사용자에게 제공합니다. 이러한 방식으로 로컬 작업자는 학습 프로세스 중에 서로를 기다릴 필요가 없으므로 특히 작업자 수가 클 때 많은 시간을 절약할 수 있습니다.
또한 매개 변수 서버는 모델 매개 변수를 저장하는 분산 프레임워크이므로 작업자는 미니 일괄 처리 학습 프로세스 중에 필요한 매개 변수만 검색할 수 있으므로 설계 분산 학습 방법에 매우 뛰어난 유연성을 제공하고 스파스 모델 업데이트로 학습을 수행할 때 효율성을 향상시킵니다. 이 릴리스에서는 먼저 비동기 병렬 학습에 초점을 맞출 것이며, 나중에 스파스 업데이트로 효율적인 모델 학습을 위해 매개 변수 서버 프레임워크를 활용하는 방법에 대해 자세히 소개합니다.
8.1 Data-Parallel ASGD 사용
- 비동기 SGD(abbr. ASGD)에 매개 변수 서버를 사용하려면 Multiverso 가 지원되는 CNTK를 빌드해야 합니다. Multiverso는 Microsoft Research 아시아 팀에서 개발한 분산 기계 학습 작업을 위한 일반 매개 변수 서버 프레임워크입니다.
Clone Code: 다음을 사용하여 CNTK의 루트 폴더 아래에 코드를 복제하세요.
git submodule update --init Source/Multiverso
Linux: 구성 프로세스에서 빌드--asgd=yes하세요.Windows: please addCNTK_ENABLE_ASGDto your system environment and set the value totrue
- 웜 시작. 경우에 따라 시드 모델(표준 SGD 알고리즘에 의해 학습됨)에서 비동기 모델 학습을 시작하는 것이 좋습니다. 어떤 의미에서 비동기 SGD는 작업자 간의 비동기 업데이트 지연으로 인해 학습에 더 많은 노이즈를 제공합니다. 일부 모델은 처음에 이러한 노이즈에 매우 민감하므로 모델 학습이 다를 수 있습니다. 이러한 상황에서는 따뜻한 시작 이 필요합니다.
8.2 BrainScript에서 Data-Parallel ASGD 구성
CNTK에서 Data-Parallel ASGD를 사용하려면 다음 옵션을 사용하여 SGD 블록에 하위 블록 DataParallelASGD가 있어야 합니다.
-
syncPeriodPerWorkers. 매개 변수 서버와 통신하기 전에 각 작업자가 처리해야 하는 샘플 수를 지정합니다. 기본값은 256입니다. 미니배치의 크기로 권장됩니다. 자주 동기화하면 상당한 통신 비용이 발생할 것이 분명합니다. 테스트에서 대부분의 경우 값을 1로 설정할 필요는 없습니다.
-
usePipeline. 모델 검색 및 로컬 계산의 파이프라인을 켜는지 여부를 지정합니다. 파이프라인을 켜면 통신 비용의 일부 또는 전부가 숨겨지기 때문에 전체 학습 처리량이 크게 증가합니다. 그러나 파이프라인을 추가하여 더 많은 지연이 도입되기 때문에 수렴 속도가 느려질 수 있습니다. 전반적으로 클록 시간은 대부분의 경우 파이프라인에서 저장됩니다.
-
AdjustLearningRateAtBeginning. 최근 발표된 논문 [5]에 따르면, 학습 ASGD는 덜 안정적이며, 학습 손실의 간헐적인 폭발을 피하기 위해 훨씬 더 작은 학습 속도를 사용해야 하므로 학습 프로세스의 효율성이 떨어집니다. 그러나 낮은 학습 속도를 사용하는 것이 모든 작업에 필요하지는 않다는 것을 발견했습니다. 그리고 처음에 민감한 작업의 경우 학습 속도를 작게 시작하여 정규 SGD에서 사용되는 초기 학습 속도에 도달할 때까지 학습 프로세스의 시작 단계에서 점진적으로 확대합니다. 이러한 방식으로 최종 정확도는 ASGD 속도와 함께 SGD와 일치합니다. 따라서 ASGD 사용자가 이 트릭을 활용할 수 있도록 이 옵션을 제공합니다. adjustCoefficient 및 adjustNBMiniBatch라는 두 매개 변수가 있는 DataParallelASGD의 하위 블록입니다. 논리는 학습 속도가 SGD 초기 학습 속도의 adjustCoefficient에서 시작하고 모든 adjustNBMiniBatch 미니 일괄 처리마다 SGD 초기 학습 속도의 adjustCoefficient에 의해 증가한다는 것입니다.
다음은 구성 섹션의 DataParallelASGD 예입니다.
learningRatesPerSample = 0.0005
ParallelTrain = [
parallelizationMethod = DataParallelASGD
distributedMBReading = true
syncPerfStats = 20
DataParallelASGD = [
syncPeriodPerWorker=256
usePipeline = true
AdjustLearningRateAtBeginning = [
adjustCoefficient = 0.2
adjustNBMiniBatch = 1024
# Learning rate will be adjusted to original one after ((1 / adjustCoefficient) * adjustNBMiniBatch) samples
# which is 5120 in this case
]
]
]
8.3 Python에서 Data-Parallel ASGD 구성
진행 중인 작업입니다.
8.4 실험
다음 그림에서는 CIFAR-10 데이터 세트를 사용하여 ASGD를 테스트하는 실험을 보여 줍니다. 이 실험에 사용된 모델은 20층 ResNet입니다. 비동기 알고리즘은 모든 작업자 노드를 기다리는 비용을 줄입니다. 이 경우 ASGD는 MA 및 SSGD와 같은 동기 알고리즘보다 훨씬 빠릅니다. *실험에서 모든 병렬 모드는 모든 반복(미니 일괄 업데이트) 매개 변수를 동기화합니다. 또한 SSGD의 경우 32비트 매개 변수 업데이트를 사용했습니다. 비동기 알고리즘은 특히 작업 노드 수가 최대 16개인 경우 샘플 처리 속도로 측정된 학습 처리량 측면에서 상당한 이점을 얻습니다.
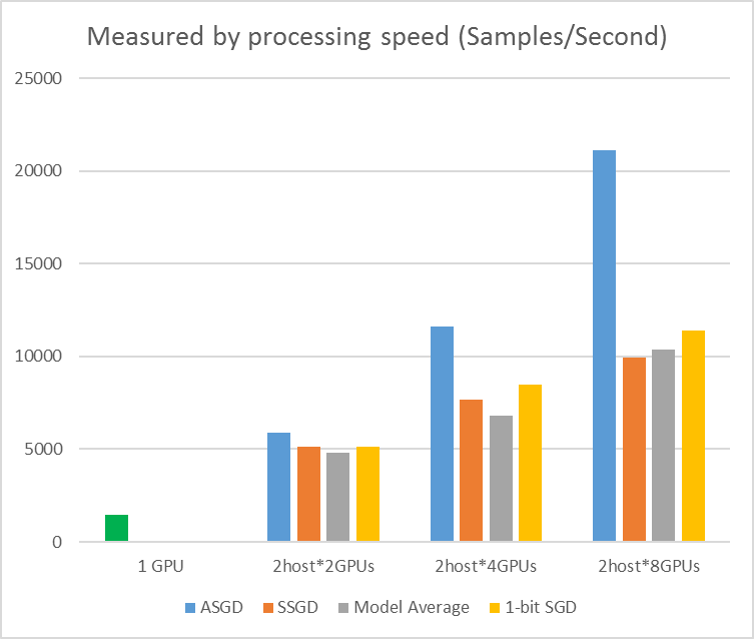 그림 2.4 다양한 학습 방법에 대한 속도 향상
그림 2.4 다양한 학습 방법에 대한 속도 향상
참조
[1] F. Seide, Hao Fu, Jasha Droppo, Gang Li 및 Dong Yu, 2014년 Interspeech 절차에서 "1비트 확률적 그라데이션 하강 및 음성 DNN의 데이터 병렬 분산 학습에 적용".
[2] K. Chen 및 Q. Huo, 2016년 ICASSP 절차에서 "블록 내 병렬 최적화 및 블록 내 모델 업데이트 필터링을 사용하여 증분 블록 학습을 통해 딥 러닝 머신의 확장 가능한 학습".
[3] M. Zinkevich, M. Weimer, L. Li, 및 A. J. Smola, "병렬화된 확률 그라데이션 하강," NIPS에서 발전의 절차, 2010, pp. 2595-2603.
[4] D. Povey, X. Zhang 및 S. Khudanpur, "자연 그라데이션 및 매개 변수 평균을 가진 DNN의 병렬 학습", 학습 표현에 대한 국제 회의의 절차, 2014.
[5] Chen J, Monga R, Bengio S, et al. Distributed Synchronous SGD를 다시 방문합니다. ICLR, 2016.
[6] 딘 제프리, 그렉 코라도, 라자트 몽가, 카이 첸, 마티유 데빈, 마크 마오, 앤드류 시니어 외. 대규모 분산 심층 네트워크. 신경 정보 처리 시스템의 고급에서 pp. 1223-1231. 2012.
[7] Li Mu, Li Zhou, Zichao Yang, Aaron Li, Fei Xia, David G. Andersen, and Alexander Smola. "분산 기계 학습을 위한 매개 변수 서버." 빅 러닝 NIPS 워크샵, vol. 6, p. 2. 2013.