Spark에서 Azure Machine Learning Notebook을 사용하는 방법
중요하다
AKS의 Azure HDInsight는 2025년 1월 31일에 사용 중지되었습니다. 이 공지 을 통해에 대해 더 알아보세요.
워크로드가 갑자기 종료되는 것을 방지하기 위해 워크로드를 Microsoft Fabric 또는 동등한 Azure 제품으로 워크로드를 마이그레이션해야 합니다.
중요하다
이 기능은 현재 미리 보기로 제공됩니다. Microsoft Azure 미리 보기에 대한 추가 사용 약관은 베타 또는 아직 일반 공급으로 릴리스되지 않은 Azure 기능에 적용되는 더 많은 법적 조건을 포함합니다. 이 특정 미리 보기에 대한 정보는 Azure HDInsight on AKS 미리 보기 정보를 참조하세요. 질문이나 기능 제안을 하시려면 AskHDInsight에 요청을 제출해 주세요. 자세한 업데이트를 받으시려면 Azure HDInsight Community를 팔로우해 주세요.
기계 학습은 컴퓨터가 과거 데이터에서 자동으로 학습할 수 있도록 하는 성장하는 기술입니다. 기계 학습은 수학 모델을 빌드하고 예측에 기록 데이터 또는 정보를 사용하는 다양한 알고리즘을 사용합니다. 일부 매개 변수까지 정의된 모델이 있으며 학습은 학습 데이터 또는 환경을 사용하여 모델의 매개 변수를 최적화하기 위해 컴퓨터 프로그램을 실행하는 것입니다. 모델은 향후 예측을 예측하거나 데이터에서 지식을 습득하기 위한 설명이 될 수 있습니다.
다음 자습서 Notebook은 테이블 형식 데이터에 대한 기계 학습 모델 학습의 예를 보여 줍니다. 이 전자 필기장을 가져와서 직접 실행할 수 있습니다.
스토리지에 CSV 업로드
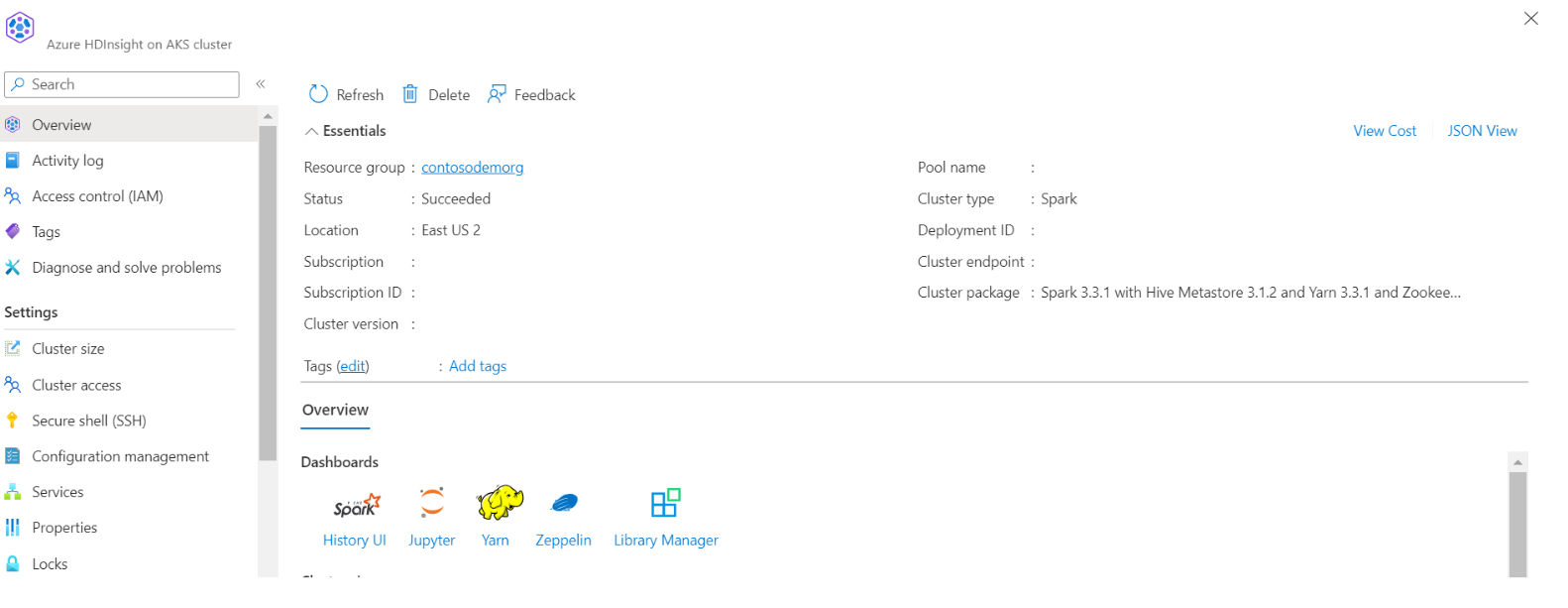
포털 JSON 보기에서 스토리지 및 컨테이너 이름 찾기
JSON 보기를 보여 주는
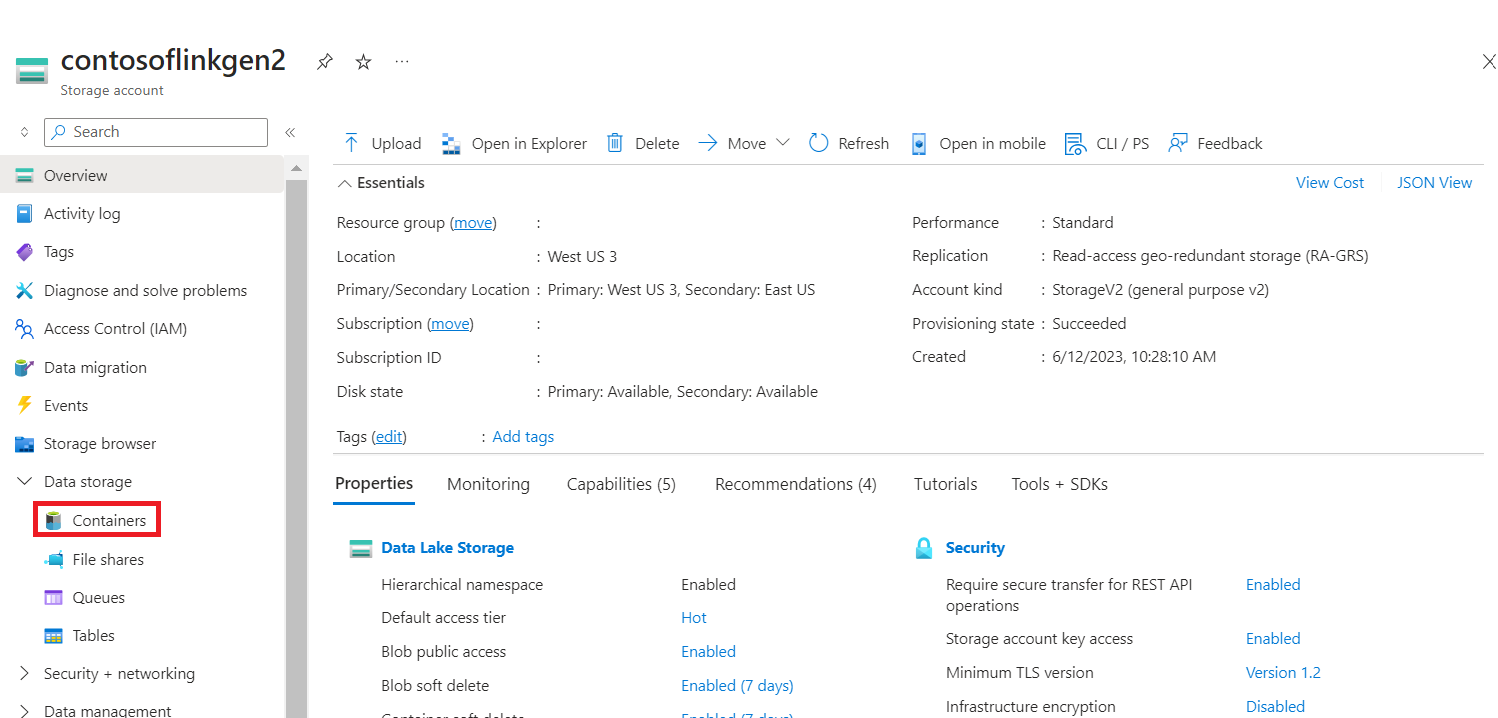
기본 HDI 스토리지>컨테이너>기본 폴더로 이동하여 CSV 업로드할> 있습니다.
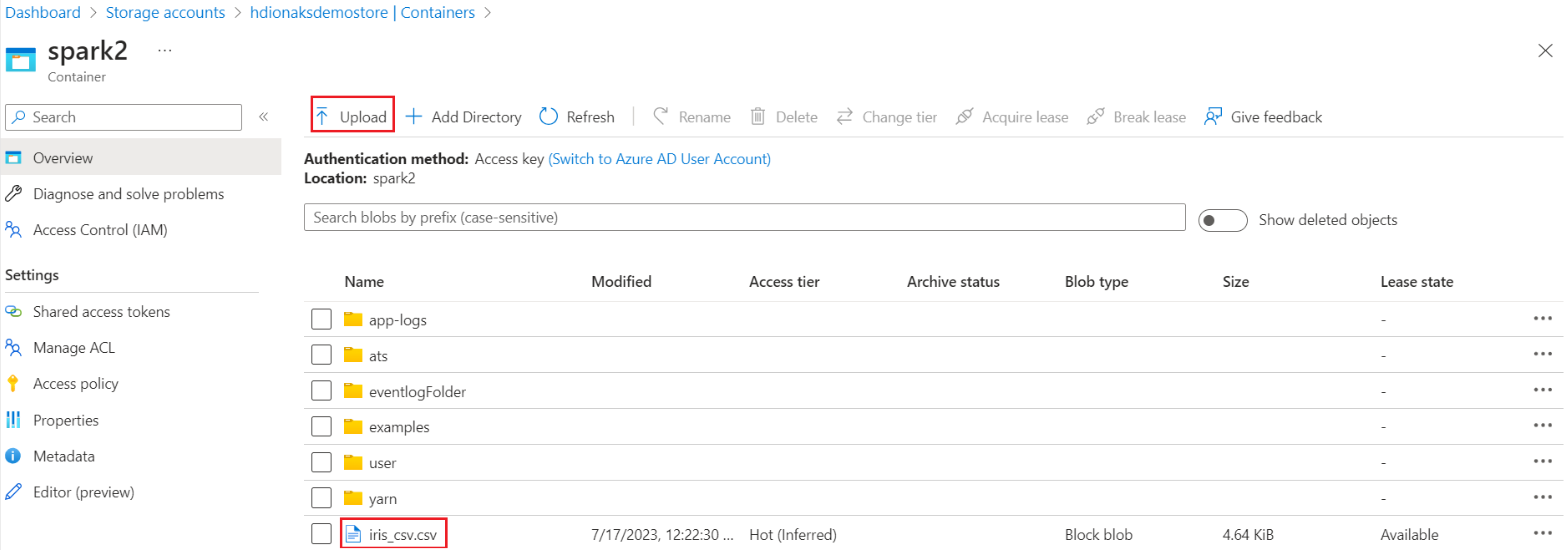
CSV 파일을 업로드하는 방법을 보여 주는
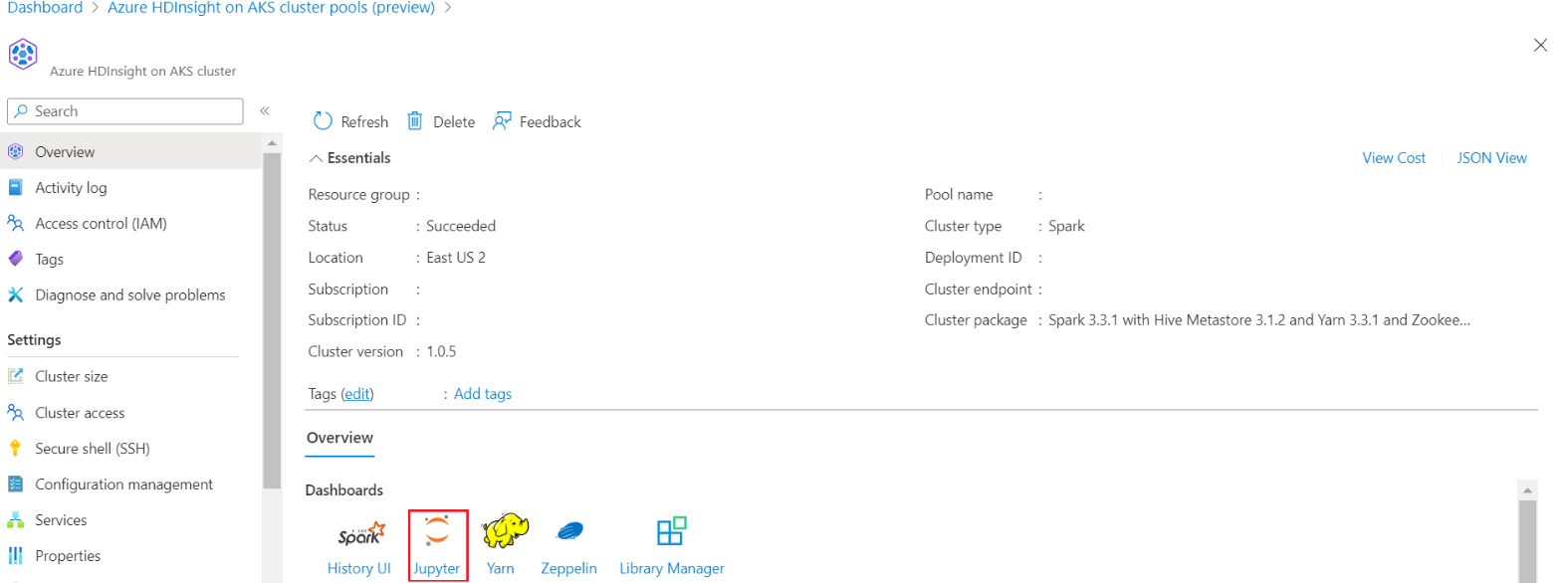
클러스터에 로그인하고 Jupyter Notebook을 엽니다.
Jupyter Notebook을 보여 주는
Spark MLlib 라이브러리를 가져와 파이프라인 만들기
import pyspark from pyspark.ml import Pipeline, PipelineModel from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import VectorAssembler, StringIndexer, IndexToString
Spark 데이터 프레임으로 CSV 읽기
df = spark.read.("abfss:///iris_csv.csv",inferSchema=True,header=True)학습 및 테스트를 위해 데이터 분할
iris_train, iris_test = df.randomSplit([0.7, 0.3], seed=123)파이프라인 만들기 및 모델 학습
assembler = VectorAssembler(inputCols=['sepallength', 'sepalwidth', 'petallength', 'petalwidth'],outputCol="features",handleInvalid="skip") indexer = StringIndexer(inputCol="class", outputCol="classIndex", handleInvalid="skip") classifier = LogisticRegression(featuresCol="features", labelCol="classIndex", maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[assembler,indexer,classifier]) model = pipeline.fit(iris_train) # Create a test `dataframe` with predictions from the trained model test_model = model.transform(iris_test) # Taking an output from the test dataframe with predictions test_model.take(1)
모델 정확도 평가
import pyspark.ml.evaluation as ev evaluator = ev.MulticlassClassificationEvaluator(labelCol='classIndex') print(evaluator.evaluate(test_model,{evaluator.metricName: 'accuracy'}))출력을 인쇄하는 방법을 보여 주는




