AKS의 HDInsight에서 Apache Spark™란? (미리 보기)
중요하다
AKS의 Azure HDInsight는 2025년 1월 31일에 사용 중지되었습니다. 이 공지 을 통해에 대해 자세히 알아보세요.
워크로드가 갑자기 종료되는 것을 방지하기 위해 워크로드를 Microsoft Fabric 또는 동등한 Azure 제품으로 워크로드를 마이그레이션해야 합니다.
중요하다
이 기능은 현재 미리 보기로 제공됩니다. Microsoft Azure 프리뷰에 대한 추가 사용 약관은 공개 베타, 미리 보기 또는 아직 일반 공급되지 않은 Azure 기능에 적용되는 추가적인 법적 조건을 포함하고 있습니다. 이 특정 미리 보기에 대한 자세한 내용은 Azure HDInsight를 AKS 미리 보기 정보에서 참조하세요. 질문 또는 기능 제안이 있으면 AskHDInsight로 요청을 제출해 주시고, 더 많은 업데이트를 받으시려면 에 있는 Azure HDInsight Community를 팔로우해 주세요.
Apache Spark™는 빅 데이터 분석 애플리케이션의 성능을 향상시키기 위해 메모리 내 처리를 지원하는 병렬 처리 프레임워크입니다.
Apache Spark™는 메모리 내 클러스터 컴퓨팅을 위한 기본 형식을 제공합니다. Spark 작업은 데이터를 로드하고 메모리에 캐시하고 반복적으로 쿼리할 수 있습니다. 메모리 내 컴퓨팅은 HDFS(Hadoop 분산 파일 시스템)를 통해 데이터를 공유하는 Hadoop과 같은 디스크 기반 애플리케이션보다 빠릅니다. Apache Spark를 사용하면 Scala 및 Python 프로그래밍 언어와 통합하여 로컬 컬렉션과 같은 분산 데이터 집합을 조작할 수 있습니다. 모든 항목을 지도로 구성하고 작업을 줄일 필요가 없습니다.
AKS의 HDInsight에서 Spark 개요를 보여 주는 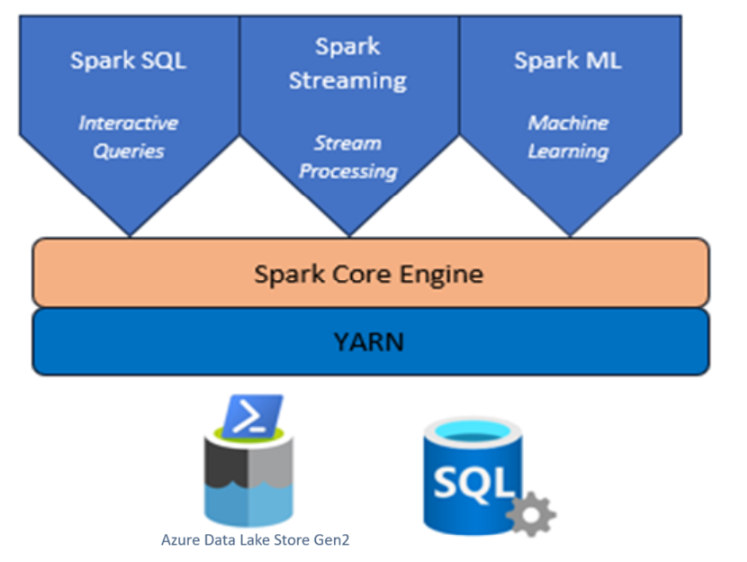
AKS에서 HDInsight를 사용하는 Apache Spark 클러스터
Azure HDInsight는 엔터프라이즈를 위한 관리형 전체 스펙트럼 오픈 소스 분석 서비스입니다.
AKS의 Azure HDInsight의 Apache Spark™는 Microsoft Azure의 관리되는 Spark 서비스입니다. AKS의 Azure HDInsight에서 Apache Spark를 사용하면 Azure 내에서 데이터를 모두 저장하고 처리할 수 있습니다. HDInsight의 Spark 클러스터는 Azure Data Lake Storage Gen2 호환되거나기존 데이터 저장소에 Spark 처리를 적용할 수 있습니다.
AKS의 HDInsight용 Apache Spark 프레임워크를 사용하면 메모리 내 처리를 사용하여 빠른 데이터 분석 및 클러스터 컴퓨팅을 수행할 수 있습니다. Jupyter Notebook을 사용하면 데이터와 상호 작용하고, 코드를 markdown 텍스트와 결합하고, 간단한 시각화를 수행할 수 있습니다.
HDInsight의 AKS에서 Apache Spark는 여러 구성 요소가 Pod로 구성되어 있습니다.
클러스터 컨트롤러
클러스터 컨트롤러는 해당 서비스를 설치하고 관리하는 역할을 담당합니다. 다양한 컨트롤러가 Spark 클러스터에 설치 및 관리됩니다.
Apache Spark 서비스 구성 요소
Zookeeper 서비스: 3개의 노드 Zookeeper 클러스터는 다른 서비스에 대한 분산 코디네이터 또는 고가용성 스토리지 역할을 합니다.
Yarn 서비스 : Hadoop Yarn 클러스터에서 Spark 작업은 Yarn 애플리케이션으로서 클러스터에서 계획됩니다.
클라이언트 인터페이스: AKS의 HDInsight에서 Apache Spark 클러스터를 다양한 클라이언트 인터페이스를 제공합니다. Livy Server, Jupyter Notebook, Spark 기록 서버는 AKS 사용자의 HDInsight에 Spark 서비스를 제공합니다.
참조
- Apache, Apache Spark, Spark 및 관련 오픈 소스 프로젝트 이름은 Apache Software Foundation(ASF)의 상표입니다.