AKS의 HDInsight에 있는 Apache Flink® 클러스터의 Table API 및 SQL
중요하다
AKS의 Azure HDInsight는 2025년 1월 31일에 사용 중지되었습니다. 공지 을 통해에 대해 더 알아보세요.
워크로드가 갑자기 종료되는 것을 방지하기 위해 워크로드를 Microsoft Fabric 또는 동등한 Azure 제품으로 워크로드를 마이그레이션해야 합니다.
중요하다
이 기능은 현재 미리 보기로 제공됩니다. Microsoft Azure Preview에 대한 추가 사용 약관은 베타, 미리 보기 상태이거나 아직 일반 공급으로 릴리스되지 않은 Azure 기능에 적용되는 더 많은 법적 조건을 포함하고 있습니다. 이 특정 미리 보기에 대한 정보는 AKS에서 실행되는 Azure HDInsight 미리 보기 정보을 참조하세요. 질문이나 기능 제안이 있는 경우, 세부 사항과 함께 AskHDInsight에 요청을 제출해 주세요. 더 많은 업데이트를 받으시려면 Azure HDInsight Community를 팔로우하세요.
Apache Flink에는 통합 스트림 및 일괄 처리에 대한 두 가지 관계형 API인 Table API 및 SQL이 있습니다. Table API는 선택, 필터링 및 조인과 같은 관계형 연산자의 쿼리를 직관적으로 구성하도록 허용하는 언어 통합 쿼리 API입니다. Flink의 SQL 지원은 SQL 표준을 구현하는 Apache Calcite를 기반으로 합니다.
Table API 및 SQL 인터페이스는 Flink의 DataStream API와 원활하게 통합됩니다. API와 이를 기반으로 하는 라이브러리 간에 쉽게 전환할 수 있습니다.
Apache Flink SQL
다른 SQL 엔진과 마찬가지로 Flink 쿼리는 테이블 위에서 작동합니다. Flink는 미사용 데이터를 로컬로 관리하지 않으므로 기존 데이터베이스와 다릅니다. 대신 쿼리는 외부 테이블에 대해 지속적으로 작동합니다.
Flink 데이터 처리 파이프라인은 원본 테이블로 시작하고 싱크 테이블로 끝납니다. 원본 테이블은 쿼리 실행 중에 작동하는 행을 생성합니다. 쿼리의 FROM 절에서 참조되는 테이블입니다. 커넥터는 HDInsight Kafka, HDInsight HBase, Azure Event Hubs, 데이터베이스, 파일 시스템 또는 커넥터가 클래스 경로에 있는 다른 시스템일 수 있습니다.
AKS 클러스터의 HDInsight에서 Flink SQL 클라이언트 사용
Azure Portal의 Secure Shell CLI를 사용하는 방법에 대한 이 문서를 참조할 수 있습니다. 다음은 시작하는 방법에 대한 몇 가지 빠른 샘플입니다.
SQL 클라이언트를 시작하려면
./bin/sql-client.shsql-client와 함께 실행할 초기화 sql 파일을 전달하려면
./sql-client.sh -i /path/to/init_file.sqlsql-client에서 구성을 설정하려면
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
SQL DDL (데이터 정의 언어)
Flink SQL은 다음 CREATE 문을 지원합니다.
- 테이블 생성
- 데이터베이스 생성
- 카탈로그 만들기
다음은 jdbc 커넥터를 사용하여 MSSQL에 연결하고, 'id', 'name'을 열로 하는 원본 테이블을 CREATE TABLE 문에서 정의하는 예제 구문입니다.
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
데이터베이스 생성 :
CREATE DATABASE students;
카탈로그 만들기 :
CREATE CATALOG myhive WITH ('type'='hive');
이러한 테이블 위에 연속 쿼리를 실행할 수 있습니다.
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
싱크 테이블에 원본 테이블에서 씁니다.
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
종속성 추가
JAR 문은 사용자 jar를 클래스 경로에 추가하거나 클래스 경로에서 사용자 jar를 제거하거나 런타임에 클래스 경로에 추가된 jar을 표시하는 데 사용됩니다.
Flink SQL은 다음 JAR 문을 지원합니다.
- JAR 추가
- 병 표시
- JAR 제거
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
AKS의 HDInsight에 있는 Apache Flink® 클러스터의 Hive Metastore
카탈로그는 데이터베이스, 테이블, 파티션, 뷰 및 함수와 같은 메타데이터와 데이터베이스 또는 기타 외부 시스템에 저장된 데이터에 액세스하는 데 필요한 정보를 제공합니다.
AKS의 HDInsight에서 Flink는 다음 두 가지 카탈로그 옵션을 지원합니다.
일반 메모리 내 카탈로그
GenericInMemoryCatalog 카탈로그의 메모리 내 구현입니다. 모든 개체는 sql 세션의 수명 동안만 사용할 수 있습니다.
HiveCatalog
HiveCatalog 두 가지 용도로 사용됩니다. 순수 Flink 메타데이터에 대한 영구 스토리지로, 기존 Hive 메타데이터를 읽고 쓰기 위한 인터페이스로 사용됩니다.
메모
AKS 클러스터의 HDInsight에는 Apache Flink용 Hive Metastore의 통합 옵션이 함께 제공됩니다. 클러스터를 만드는 동안 Hive Metastore를 선택할 수
카탈로그에 Flink 데이터베이스를 만들고 등록하는 방법
CLI를 사용하고 Azure Portal의 Secure Shell Flink SQL Client를 시작하는 방법에 대한 이 문서를 참조할 수 있습니다.
sql-client.sh세션 시작
Default_catalog 기본 메모리 내 카탈로그입니다.
이제 메모리 내 카탈로그의 기본 데이터베이스를 확인해 보겠습니다.
버전 3.1.2의 Hive 카탈로그를 만들고 사용하겠습니다.
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;메모
AKS의 HDInsight는 Hive 3.1.2 및 Hadoop 3.3.2지원합니다.
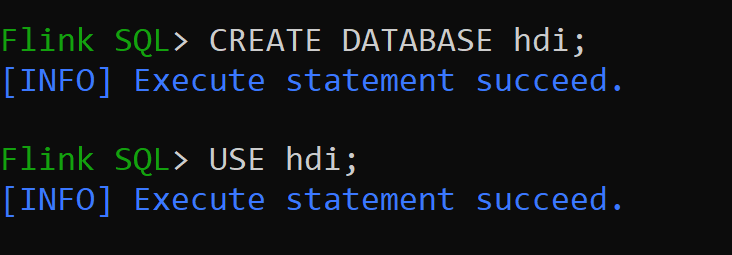
hive-conf-dir이(가)/opt/hive-conf위치로 설정됩니다.Hive 카탈로그에서 데이터베이스를 만들고 세션의 기본값으로 설정해 보겠습니다(변경되지 않는 한).
Hive 카탈로그에 Hive 테이블을 만들고 등록하는 방법
Flink 데이터베이스를 생성하고 카탈로그에 등록하는 방법에 대한 지침을 따르십시오.
파티션 없이 커넥터 유형 Hive의 Flink 테이블을 만들어 보겠습니다.
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');hive_table에 데이터 삽입하기
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';hive_table 데이터를 읽습니다.
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rows메모
Hive Warehouse 디렉터리가 Apache Flink 클러스터를 만드는 동안 선택한 스토리지 계정의 지정된 컨테이너에 있으며, 디렉터리 hive/warehouse/에서 찾을 수 있습니다.
파티션을 사용하여 커넥터 형식 하이브의 Flink 테이블을 만들 수 있습니다.
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
중요하다
Apache Flink에는 알려진 제한 사항이 있습니다. 마지막 'n' 열은 사용자 정의 파티션 열에 관계없이 파티션에 대해 선택됩니다. FLINK-32596 Flink 방언을 사용하여 Hive 테이블을 만들 때 파티션 키가 잘못되었습니다.
참조
- Apache Flink Table API & SQL
- Apache, Apache Flink, Flink 및 관련 오픈 소스 프로젝트 이름은 asF(Apache Software Foundation)의 상표입니다.