Apache Flink® DataStream API를 사용하여 Azure Data Lake Storage Gen2에 이벤트 메시지 쓰기
중요하다
AKS의 Azure HDInsight는 2025년 1월 31일에 사용 중지되었습니다. 이 공지 을 통해에 대해 자세히 알아보세요.
워크로드가 갑자기 종료되는 것을 방지하기 위해 워크로드를 Microsoft Fabric 또는 동등한 Azure 제품으로 워크로드를 마이그레이션해야 합니다.
중요하다
이 기능은 현재 미리 보기로 제공됩니다. Microsoft Azure Previews에 대한 추가 사용 약관에는 베타, 미리 보기 또는 아직 일반 공급으로 릴리스되지 않은 Azure 기능에 적용되는 추가적인 법적 조건이 포함되어 있습니다. 이 특정 미리 보기에 대한 자세한 내용은 Azure HDInsight AKS 미리 보기 정보를 참조하세요. 질문이나 기능 제안이 있으시면, 세부 사항과 함께 AskHDInsight에 요청을 제출해 주시고, Azure HDInsight Community를 팔로우하여 더 많은 업데이트를 받아보세요.
Apache Flink는 파일 시스템을 사용하여 애플리케이션의 결과와 내결함성 및 복구를 위해 데이터를 사용하고 영구적으로 저장합니다. 이 문서에서는 DataStream API를 사용하여 Azure Data Lake Storage Gen2에 이벤트 메시지를 작성하는 방법을 알아봅니다.
필수 구성 요소
- AKS의 HDInsight에 있는 Apache Flink 클러스터
- HDInsight의 Apache Kafka 클러스터
- 네트워크 설정을 HDInsight의 Apache Kafka 사용 방법 에서에 설명된 대로 처리해야 합니다. AKS 및 HDInsight 클러스터의 HDInsight가 동일한 Virtual Network에 있는지 확인합니다.
- MSI를 사용하여 ADLS Gen2 액세스
- AKS Virtual Network의 HDInsight에서 Azure VM 개발용 IntelliJ
Apache Flink FileSystem 커넥터
이 파일 시스템 커넥터는 BATCH 및 STREAMING 모두에 대해 동일한 보장을 제공하며 STREAMING 실행에 정확히 한 번 의미 체계를 제공하도록 설계되었습니다. 자세한 내용은 Flink DataStream Filesystem참조하세요.
Apache Kafka 커넥터
Flink는 정확히 한 번의 보장으로 Kafka 토픽에서 데이터를 읽고 Kafka 토픽에 쓸 수 있는 Apache Kafka 커넥터를 제공합니다. 자세한 내용은 Apache Kafka Connector참조하세요.
Apache Flink용 프로젝트 빌드
IntelliJ IDEA의 pom.xml
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
ADLS Gen2 싱크를 위한 프로그램
abfsGen2.java
메모
hdInsight 클러스터의 Apache Kafka bootStrapServers를 사용자 소유의 Kafka 3.2 브로커로 교체합니다.
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class KafkaSinkToGen2 {
public static void main(String[] args) throws Exception {
// 1. get stream execution env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration flinkConfig = new Configuration();
flinkConfig.setString("classloader.resolve-order", "parent-first");
env.getConfig().setGlobalJobParameters(flinkConfig);
// 2. read kafka message as stream input, update your broker ip's
String brokers = "<update-broker-ip>:9092,<update-broker-ip>:9092,<update-broker-ip>:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
stream.print();
// 3. sink to gen2, update container name and storage path
String outputPath = "abfs://<container-name>@<storage-path>.dfs.core.windows.net/flink/data/click_events";
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(2))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute("Kafka Sink To Gen2");
}
}
패키지 jar를 Apache Flink에 제출합니다.
ABFS에 jar을 업로드합니다.
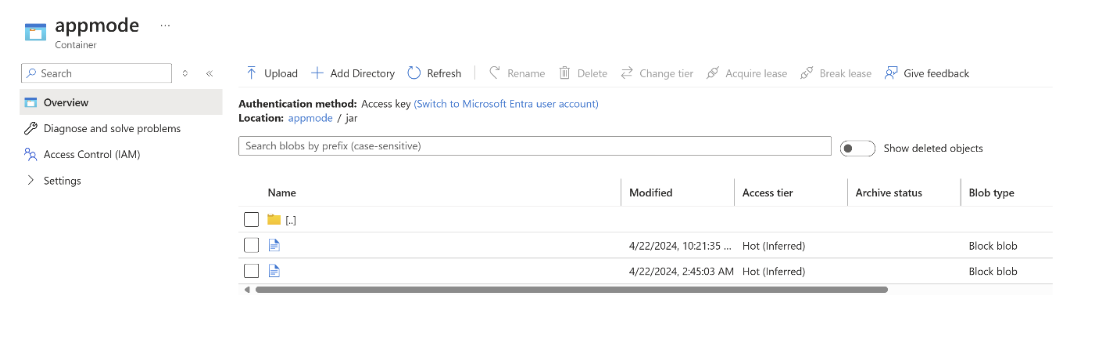
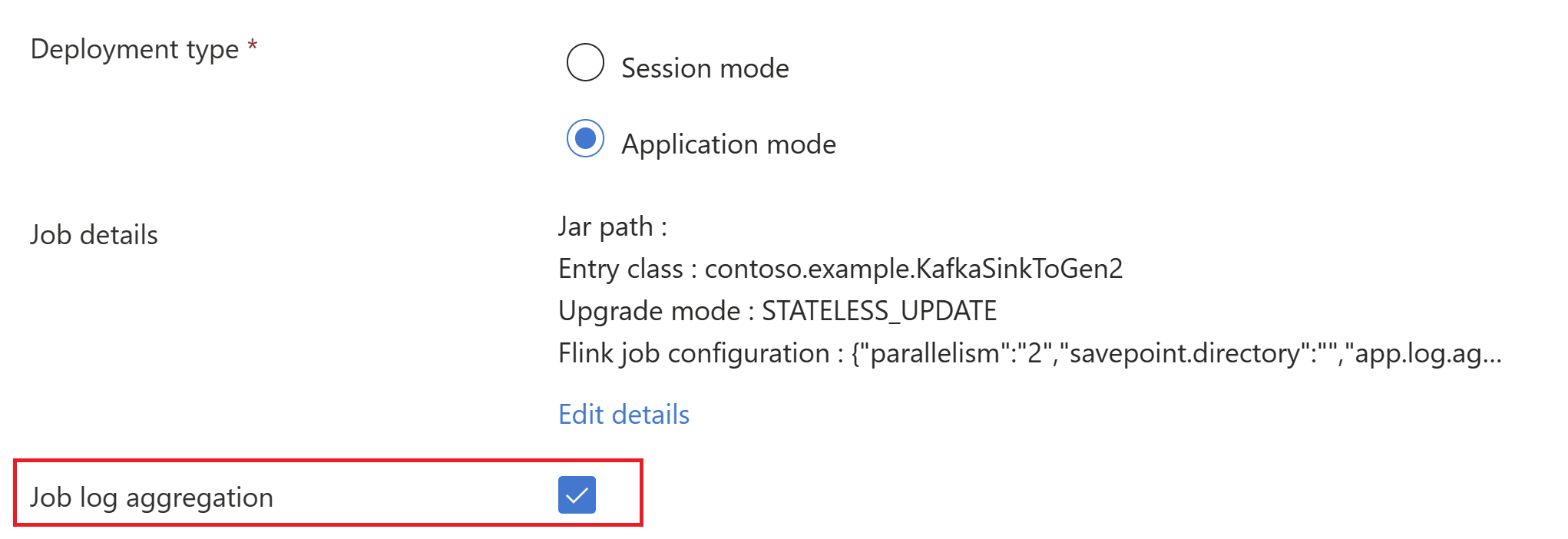
AppMode클러스터 생성 시 작업 jar 정보를 전달합니다.앱 만들기 모드를 보여 주는

메모
확인하십시오 classloader.resolve-order를 'parent-first'로 추가하고 hadoop.classpath.enable을
true으로 설정하십시오.작업 로그 집계를 선택하여 작업 로그를 스토리지 계정에 푸시합니다.
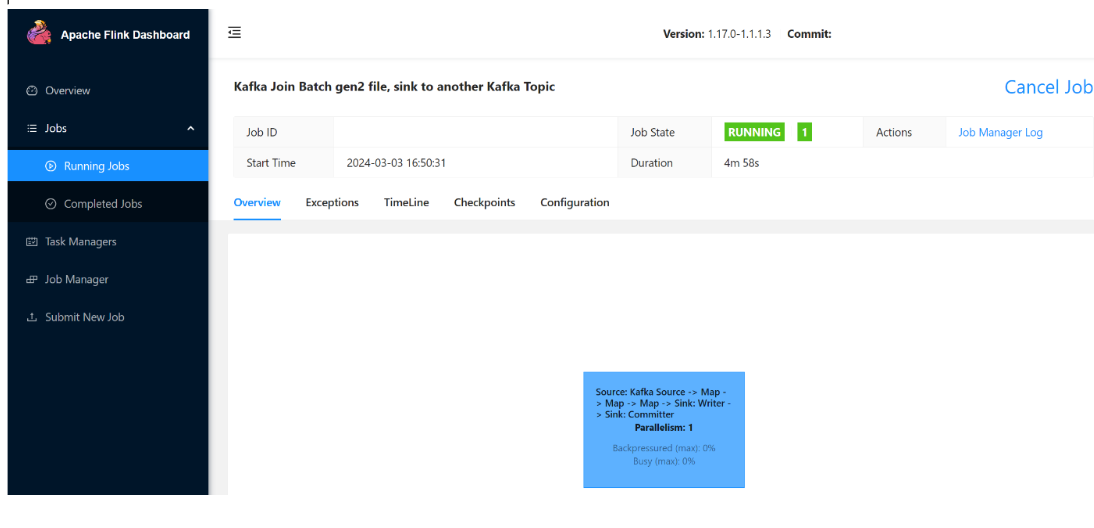
실행 중인 작업을 볼 수 있습니다.
Flink UI를 보여 주는




ADLS Gen2 스트리밍 데이터 유효성 검사
click_events가 ADLS Gen2로 스트리밍되는 것을 보고 있습니다.
ADLS Gen2 출력을 보여 주는 스크린샷 

다음 세 가지 조건 중에서 진행 중인 파트 파일을 롤아웃하는 롤링 정책을 지정할 수 있습니다.
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(5))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
참조
- Apache Kafka 커넥터
- Flink DataStream 파일 시스템
- Apache Flink 웹 사이트
- Apache, Apache Kafka, Kafka, Apache Flink, Flink 및 관련 오픈 소스 프로젝트 이름은 Apache Software Foundation(ASF)의 상표입니다.