Batch AI에서 Azure Machine Learning 서비스로 마이그레이션
Azure Batch AI 서비스가 3월에 사용 중지됩니다. Batch AI의 대규모 학습 및 채점 기능을 이제 Azure Machine Learning Service에서 사용할 수 있습니다(2018년 12월 4일 일반 제공됨).
Azure Machine Learning Service에는 다양한 다른 기계 학습 기능과 함께 기계 학습 모델을 학습시키고, 배포하며, 채점하기 위한 클라우드 기반 관리형 컴퓨팅 대상이 포함되어 있습니다. 이 컴퓨팅 대상을 Azure Machine Learning 컴퓨팅이라고 합니다. 지금 마이그레이션을 시작하고 사용해 보세요. Python SDK, 명령줄 인터페이스 및 Azure Portal을 통해 Azure Machine Learning Service와 상호 작용할 수 있습니다.
Preview Batch AI에서 GA(일반 공급)되는 Azure Machine Learning Service로 업그레이드하면 추정기 및 데이터 저장소와 같이 사용하기 쉬운 개념을 통해 더 나은 환경을 제공합니다. 또한 GA 수준 Azure 서비스 SLA 및 고객 지원도 보장합니다.
Azure Machine Learning Service도 대부분의 대규모 AI 워크로드에 유용한 자동화된 기계 학습, 하이퍼 매개 변수 튜닝 및 ML 파이프라인과 같은 새로운 기능을 도입했습니다. 별도의 서비스로 전환하지 않고도 학습된 모델을 배포할 수 있으므로 데이터 준비(Data Prep SDK 사용)에서 운영화 및 모델 모니터링까지 데이터 과학 루프를 완료하는 데 도움이 됩니다.
마이그레이션 시작
애플리케이션의 중단을 방지하고 최신 기능을 활용하려면 2019년 3월 31일 전에 다음 단계를 수행하세요.
Azure Machine Learning Service 작업 영역을 만들고 시작합니다.
Azure Machine Learning SDK 및 Data Prep SDK를 설치합니다.
Azure Machine Learning 컴퓨팅의 모델 학습을 설정합니다.
Azure Machine Learning 컴퓨팅을 사용하도록 스크립트를 업데이트합니다. 다음 섹션에서는 Batch AI에 사용하는 일반적인 코드가 Azure Machine Learning의 어떤 코드에 해당하는지를 보여 줍니다.
작업 영역 만들기
Azure Batch AI에서 configuration.json을 사용하여 작업 영역을 초기화하는 개념은 Azure Machine Learning Service의 구성 파일을 사용하는 개념과 비슷하게 매핑됩니다.
Batch AI에서는 다음과 같이 수행했습니다.
sys.path.append('../../..')
import utilities as utils
cfg = utils.config.Configuration('../../configuration.json')
client = utils.config.create_batchai_client(cfg)
utils.config.create_resource_group(cfg)
_ = client.workspaces.create(cfg.resource_group, cfg.workspace, cfg.location).result()
Azure Machine Learning Service에서는 다음을 시도합니다.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
print('Workspace name: ' + ws.name,
'Azure region: ' + ws.location,
'Subscription id: ' + ws.subscription_id,
'Resource group: ' + ws.resource_group, sep = '\n')
또한 다음과 같은 구성 매개 변수를 지정하여 Workspace(작업 영역)를 직접 만들 수도 있습니다.
from azureml.core import Workspace
# Create the workspace using the specified parameters
ws = Workspace.create(name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group,
location = workspace_region,
create_resource_group = True,
exist_ok = True)
ws.get_details()
# write the details of the workspace to a configuration file to the notebook library
ws.write_config()
SDK 참조 설명서에서 Azure Machine Learning Workspace 클래스에 대해 자세히 알아보세요.
컴퓨팅 클러스터 만들기
Azure Machine Learning은 여러 컴퓨팅 대상을 지원하며, 이 중 일부는 서비스에서 관리하고 다른 일부는 작업 영역(예: HDInsight 클러스터 또는 원격 VM에 연결할 수 있습니다. 다양한 컴퓨팅 대상에 대해 자세히 알아보세요. Azure Batch AI 컴퓨팅 클러스터를 만드는 개념으로 Azure Machine Learning Service에서 AmlCompute 클러스터를 만듭니다. Amlcompute 만들기는 Azure Batch AI에서 매개 변수를 전달하는 방식과 비슷한 컴퓨팅 구성을 사용합니다. 한 가지 주의할 점은 자동 크기 조정이 AmlCompute 클러스터에서 기본적으로 설정되어 있지만, Azure Batch AI에서는 기본적으로 해제되어 있다는 것입니다.
Batch AI에서는 다음과 같이 수행했습니다.
nodes_count = 2
cluster_name = 'nc6'
parameters = models.ClusterCreateParameters(
vm_size='STANDARD_NC6',
scale_settings=models.ScaleSettings(
manual=models.ManualScaleSettings(target_node_count=nodes_count)
),
user_account_settings=models.UserAccountSettings(
admin_user_name=cfg.admin,
admin_user_password=cfg.admin_password or None,
admin_user_ssh_public_key=cfg.admin_ssh_key or None,
)
)
_ = client.clusters.create(cfg.resource_group, cfg.workspace, cluster_name, parameters).result()
Azure Machine Learning Service에서는 다음을 시도합니다.
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# Choose a name for your CPU cluster
gpu_cluster_name = "nc6"
# Verify that cluster does not exist already
try:
gpu_cluster = ComputeTarget(workspace=ws, name=gpu_cluster_name)
print('Found existing cluster, use it.')
except ComputeTargetException:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6',
vm_priority='lowpriority',
min_nodes=1,
max_nodes=2,
idle_seconds_before_scaledown='300',
vnet_resourcegroup_name='<my-resource-group>',
vnet_name='<my-vnet-name>',
subnet_name='<my-subnet-name>')
gpu_cluster = ComputeTarget.create(ws, gpu_cluster_name, compute_config)
gpu_cluster.wait_for_completion(show_output=True)
SDK 참조 설명서에서 AMLCompute 클래스에 대해 자세히 알아보세요. 위의 구성에서는 vm_size 및 max_nodes만 필수이고, VNets와 같은 나머지 속성은 고급 클러스터 설정 전용입니다.
클러스터 상태 모니터링
이 작업은 아래와 같이 Azure Machine Learning Service에서 더 간단합니다.
Batch AI에서는 다음과 같이 수행했습니다.
cluster = client.clusters.get(cfg.resource_group, cfg.workspace, cluster_name)
utils.cluster.print_cluster_status(cluster)
Azure Machine Learning Service에서는 다음을 시도합니다.
gpu_cluster.get_status().serialize()
스토리지 계정에 대한 참조 가져오기
Blob과 같은 데이터 스토리지의 개념은 Azure Machine Learning Service에서 DataStore 개체를 사용하여 간소화됩니다. 기본적으로 Azure Machine Learning Service 작업 영역은 스토리지 계정을 만들지만, 작업 영역 만들기의 일환으로 사용자 고유의 스토리지를 연결할 수도 있습니다.
Batch AI에서는 다음과 같이 수행했습니다.
azure_blob_container_name = 'batchaisample'
blob_service = BlockBlobService(cfg.storage_account_name, cfg.storage_account_key)
blob_service.create_container(azure_blob_container_name, fail_on_exist=False)
Azure Machine Learning Service에서는 다음을 시도합니다.
ds = ws.get_default_datastore()
print(ds.datastore_type, ds.account_name, ds.container_name)
Azure Machine Learning Service 설명서에서 추가 스토리지 계정을 등록하거나 등록된 다른 데이터 저장소에 대한 참조를 가져오는 방법에 대해 자세히 알아보세요.
데이터 다운로드 및 업로드
두 서비스 중 하나를 사용하면 위의 데이터 저장소 참조를 사용하여 데이터를 스토리지 계정에 쉽게 업로드할 수 있습니다. Azure Batch AI에서는 Azure Machine Learning Service의 경우 작업 구성의 일부로 학습 스크립트를 지정할 수 있는 방법을 보여 주지만, 파일 공유의 일부로 학습 스크립트도 배포합니다.
Batch AI에서는 다음과 같이 수행했습니다.
mnist_dataset_directory = 'mnist_dataset'
utils.dataset.download_and_upload_mnist_dataset_to_blob(
blob_service, azure_blob_container_name, mnist_dataset_directory)
script_directory = 'tensorflow_samples'
script_to_deploy = 'mnist_replica.py'
blob_service.create_blob_from_path(azure_blob_container_name,
script_directory + '/' + script_to_deploy,
script_to_deploy)
Azure Machine Learning Service에서는 다음을 시도합니다.
import os
import urllib
os.makedirs('./data', exist_ok=True)
download_url = 'https://s3.amazonaws.com/img-datasets/mnist.npz'
urllib.request.urlretrieve(download_url, filename='data/mnist.npz')
ds.upload(src_dir='data', target_path='mnist_dataset', overwrite=True, show_progress=True)
path_on_datastore = ' mnist_dataset/mnist.npz' ds_data = ds.path(path_on_datastore) print(ds_data)
실험 만들기
위에서 설명한 대로 Azure Machine Learning Service에는 Azure Batch AI와 비슷한 실험 개념이 있습니다. 이에 따라 각 실험은 Azure Batch AI의 작업을 사용하는 방식과 비슷하게 개별 실행을 사용할 수 있습니다. 또한 Azure Machine Learning Service를 사용하면 개별 자식 실행에 대해 각 부모 실행 아래의 계층 구조를 사용할 수 있습니다.
Batch AI에서는 다음과 같이 수행했습니다.
experiment_name = 'tensorflow_experiment'
experiment = client.experiments.create(cfg.resource_group, cfg.workspace, experiment_name).result()
Azure Machine Learning Service에서는 다음을 시도합니다.
from azureml.core import Experiment
experiment_name = 'tensorflow_experiment'
experiment = Experiment(ws, name=experiment_name)
작업 제출
실험이 만들어지면 몇 가지 다른 방법으로 실행을 제출할 수 있습니다. 다음 예제에서는 TensorFlow를 사용하는 딥 러닝 모델을 만들려고 하며, 이 작업을 수행하기 위해 Azure Machine Learning Service 추정기를 사용합니다. 추정기는 실행을 더 쉽게 제출할 수 있는 기본 실행 구성의 래퍼 함수이며, 현재 Pytorch 및 TensorFlow에서만 지원됩니다. 데이터 저장소의 개념을 통해 탑재 경로를 매우 쉽게 지정할 수 있음을 알 수 있습니다.
Batch AI에서는 다음과 같이 수행했습니다.
azure_file_share = 'afs'
azure_blob = 'bfs'
args_fmt = '--job_name={0} --num_gpus=1 --train_steps 10000 --checkpoint_dir=$AZ_BATCHAI_OUTPUT_MODEL --log_dir=$AZ_BATCHAI_OUTPUT_TENSORBOARD --data_dir=$AZ_BATCHAI_INPUT_DATASET --ps_hosts=$AZ_BATCHAI_PS_HOSTS --worker_hosts=$AZ_BATCHAI_WORKER_HOSTS --task_index=$AZ_BATCHAI_TASK_INDEX'
parameters = models.JobCreateParameters(
cluster=models.ResourceId(id=cluster.id),
node_count=2,
input_directories=[
models.InputDirectory(
id='SCRIPT',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, script_directory)),
models.InputDirectory(
id='DATASET',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, mnist_dataset_directory))],
std_out_err_path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
output_directories=[
models.OutputDirectory(
id='MODEL',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Models'),
models.OutputDirectory(
id='TENSORBOARD',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Logs')
],
mount_volumes=models.MountVolumes(
azure_file_shares=[
models.AzureFileShareReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
azure_file_url='https://{0}.file.core.windows.net/{1}'.format(
cfg.storage_account_name, azure_file_share_name),
relative_mount_path=azure_file_share)
],
azure_blob_file_systems=[
models.AzureBlobFileSystemReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
container_name=azure_blob_container_name,
relative_mount_path=azure_blob)
]
),
container_settings=models.ContainerSettings(
image_source_registry=models.ImageSourceRegistry(image='tensorflow/tensorflow:1.8.0-gpu')),
tensor_flow_settings=models.TensorFlowSettings(
parameter_server_count=1,
worker_count=nodes_count,
python_script_file_path='$AZ_BATCHAI_INPUT_SCRIPT/'+ script_to_deploy,
master_command_line_args=args_fmt.format('worker'),
worker_command_line_args=args_fmt.format('worker'),
parameter_server_command_line_args=args_fmt.format('ps'),
)
)
Azure Batch AI에서 작업 자체를 제출하는 것은 create 함수를 통해 이루어집니다.
job_name = datetime.utcnow().strftime('tf_%m_%d_%Y_%H%M%S')
job = client.jobs.create(cfg.resource_group, cfg.workspace, experiment_name, job_name, parameters).result()
print('Created Job {0} in Experiment {1}'.format(job.name, experiment.name))
이 학습 코드 조각(위의 파일 공유에 업로드한 mnist_replica.py 파일 포함)에 대한 전체 정보는 Azure Batch AI Notebook 샘플 github 리포지토리에서 찾을 수 있습니다.
Azure Machine Learning Service에서는 다음을 시도합니다.
from azureml.train.dnn import TensorFlow
script_params={
'--num_gpus': 1,
'--train_steps': 500,
'--input_data': ds_data.as_mount()
}
estimator = TensorFlow(source_directory=project_folder,
compute_target=gpu_cluster,
script_params=script_params,
entry_script='tf_mnist_replica.py',
node_count=2,
worker_count=2,
parameter_server_count=1,
distributed_backend='ps',
use_gpu=True)
이 학습 코드 조각(tf_mnist_replica.py 파일 포함)에 대한 전체 정보는 Azure Machine Learning Service 샘플 Notebook github 리포지토리에서 찾을 수 있습니다. 데이터 저장소 자체를 개별 노드에 탑재할 수 있거나, 학습 데이터를 노드 자체에서 다운로드할 수 있습니다. 추정기에서 데이터 저장소를 참조하는 방법에 대한 자세한 내용은 Azure Machine Learning Service 설명서를 참조하세요.
Azure Machine Learning Service에서 실행을 제출하는 것은 submit 함수를 통해 이루어집니다.
run = experiment.submit(estimator)
print(run)
실행 구성을 사용하여 실행에 대한 매개 변수를 지정하는 또 다른 방법이 있으며, 특히 사용자 지정 학습 환경을 정의하는 데 유용합니다. 자세한 내용은 이 AmlCompute Notebook 샘플에서 확인할 수 있습니다.
실행 모니터링
실행이 제출되면 코드에서 직접 호출할 수 있는 깔끔한 Jupyter 위젯을 사용하여 실행이 완료될 때까지 기다리거나 Azure Machine Learning Service에서 해당 실행을 모니터링할 수 있습니다. 또한 작업 영역에서 다양한 실험을 반복하여 이전 실행의 컨텍스트를 끌어올 수 있으며, 각 실험 내에서 개별 실행됩니다.
Batch AI에서는 다음과 같이 수행했습니다.
utils.job.wait_for_job_completion(client, cfg.resource_group, cfg.workspace,
experiment_name, job_name, cluster_name, 'stdouterr', 'stdout-wk-0.txt')
files = client.jobs.list_output_files(cfg.resource_group, cfg.workspace, experiment_name, job_name,
models.JobsListOutputFilesOptions(outputdirectoryid='stdouterr'))
for f in list(files):
print(f.name, f.download_url or 'directory')
Azure Machine Learning Service에서는 다음을 시도합니다.
run.wait_for_completion(show_output=True)
from azureml.widgets import RunDetails
RunDetails(run).show()
다음은 로그를 실시간으로 보기 위해 전자 필기장에서 위젯을 로드하는 방법에 대한 스냅샷. 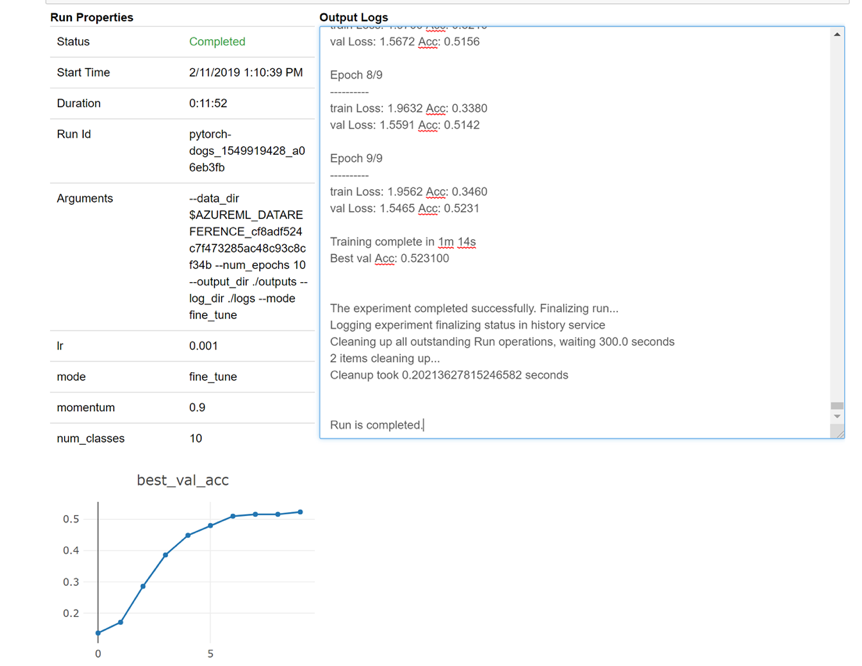
클러스터 편집
클러스터를 삭제하는 것은 간단합니다. 또한 Azure Machine Learning Service를 사용하면 클러스터를 더 많은 수의 노드로 확장하거나 클러스터를 축소하기 전에 유휴 대기 시간을 늘리려는 경우에 대비하여 Notebook 내에서 클러스터를 업데이트할 수 있습니다. 백 엔드에서 새 배포를 실질적으로 수행해야 하므로 클러스터 자체의 VM 크기는 변경할 수 없습니다.
Batch AI에서는 다음과 같이 수행했습니다.
_ = client.clusters.delete(cfg.resource_group, cfg.workspace, cluster_name)
Azure Machine Learning Service에서는 다음을 시도합니다.
gpu_cluster.delete()
gpu_cluster.update(min_nodes=2, max_nodes=4, idle_seconds_before_scaledown=600)
지원 받기
Batch AI는 3월 31일에 사용 중지될 예정이며 지원을 통해 예외를 발생시켜 허용 목록에 없는 한 새 구독이 서비스에 등록되지 않도록 이미 차단하고 있습니다. 질문이 있거나 Azure Machine Learning Service로 마이그레이션할 때 피드백이 있는 경우 Azure Batch AI 학습 미리 보기에 문의하세요.
Azure Machine Learning Service는 일반적으로 공급됩니다. 즉 커밋된 SLA와 다양한 지원 플랜 중에서 선택할 수 있습니다.
두 경우 모두 기본 컴퓨팅에 대한 가격만 청구하므로 Azure Batch AI 서비스 또는 Azure Machine Learning 서비스를 통해 Azure 인프라를 사용하기 위한 가격은 달라서는 안 됩니다. 자세한 내용은 가격 계산기를 참조하세요.
Azure Portal에서 두 서비스 간의 지역별 가용성을 확인해 보세요.
다음 단계
Azure Machine Learning Service 개요를 읽어 봅니다.
Azure Machine Learning Service를 사용하여모델 학습을 위한 컴퓨팅 대상을 구성합니다.
Azure 로드맵을 검토하여 다른 Azure 서비스 업데이트에 대해 알아봅니다.