TripPin 5부 - 페이징
이 다중 파트 자습서에서는 파워 쿼리에 대한 새 데이터 원본 확장의 생성에 대해 설명합니다. 이 자습서는 순차적으로 수행됩니다. 각 단원은 이전 단원에서 만든 커넥터를 기반으로 하여 커넥터에 새 기능을 증분 방식으로 추가합니다.
이 단원에서는 다음을 수행합니다.
- 커넥터에 페이징 지원 추가
많은 Rest API는 "페이지"에서 데이터를 반환하므로 클라이언트가 결과를 함께 연결하기 위해 여러 요청을 해야 합니다. 페이지 매김에 대한 몇 가지 일반적인 규칙(예: RFC 5988)이 있지만 일반적으로 API마다 다릅니다. 다행히 TripPin은 OData 서비스이며 OData 표준은 응답 본문에 반환된 odata.nextLink 값을 사용하여 페이지 매김을 수행하는 방법을 정의합니다.
커넥터의 이전 반복을 간소화하기 위해 함수는 TripPin.Feed 페이지를 인식하지 못했습니다. 요청에서 반환된 JSON을 구문 분석하고 테이블 형식으로 지정하기만 하면 됩니다. OData 프로토콜에 익숙한 사람들은 응답 형식(예: 레코드 배열이 포함된 필드가 있다고 가정value)에 대해 잘못된 가정이 많이 이루어졌다는 것을 알아차렸을 수 있습니다.
이 단원에서는 페이지를 인식하게 하여 응답 처리 논리를 개선합니다. 이후 자습서를 통해 페이지 처리 논리가 더 강력하고 여러 응답 형식(서비스의 오류 포함)을 처리할 수 있습니다.
참고 항목
OData.Feed를 기반으로 하는 커넥터를 사용하여 자체 페이징 논리를 구현할 필요가 없습니다. 이 논리는 자동으로 처리되므로 구현할 필요가 없습니다.
페이징 검사 목록
페이징 지원을 구현할 때 API에 대한 다음 사항을 알아야 합니다.
- 다음 데이터 페이지를 요청하려면 어떻게 해야 할까요?
- 페이징 메커니즘에 값 계산이 포함됩니까, 아니면 응답에서 다음 페이지의 URL을 추출하나요?
- 페이징을 중지해야 하는 경우를 어떻게 알 수 있나요?
- 알고 있어야 하는 페이징과 관련된 매개 변수가 있나요? (예: "페이지 크기")
이러한 질문에 대한 답변은 페이징 논리를 구현하는 방식에 영향을 줍니다. 페이징 구현에서 재사용되는 코드는 어느 정도 있지만(예: Table.GenerateByPage 사용) 대부분의 커넥터에는 사용자 지정 논리가 필요하게 됩니다.
참고 항목
이 단원에는 특정 형식을 따르는 OData 서비스에 대한 페이징 논리가 포함되어 있습니다. API에 대한 설명서를 확인하여 해당 페이징 형식을 지원하기 위해 커넥터에서 변경해야 하는 변경 내용을 확인합니다.
OData 페이징 개요
OData 페이징은 응답 페이로드 내에 포함된 nextLink 주석에 의해 구동됩니다. nextLink 값은 데이터의 다음 페이지에 대한 URL을 포함합니다. 응답에서 가장 바깥쪽 개체의 필드를 찾아 odata.nextLink 다른 데이터 페이지가 있는지 알 수 있습니다. 필드가 없 odata.nextLink 으면 모든 데이터를 읽었습니다.
{
"odata.context": "...",
"odata.count": 37,
"value": [
{ },
{ },
{ }
],
"odata.nextLink": "...?$skiptoken=342r89"
}
일부 OData 서비스를 사용하면 클라이언트가 최대 페이지 크기 기본 설정을 제공할 수 있지만 이를 적용할지 여부는 서비스에 달려 있습니다. 파워 쿼리는 모든 크기의 응답을 처리할 수 있어야 하므로 페이지 크기 기본 설정을 지정하는 것에 대해 걱정할 필요가 없습니다. 서비스에서 throw하는 모든 항목을 지원할 수 있습니다.
서버 기반 페이징에 대한 자세한 내용은 OData 사양에서 확인할 수 있습니다.
TripPin 테스트
페이징 구현을 수정하기 전에 이전 자습서에서 확장의 현재 동작을 확인합니다. 다음 테스트 쿼리는 사람 테이블을 검색하고 인덱스 열을 추가하여 현재 행 수를 표시합니다.
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data],
withRowCount = Table.AddIndexColumn(data, "Index")
in
withRowCount
Fiddler를 켜고 파워 쿼리 SDK에서 쿼리를 실행합니다. 쿼리는 행이 8개인 테이블(인덱스 0~7)을 반환합니다.
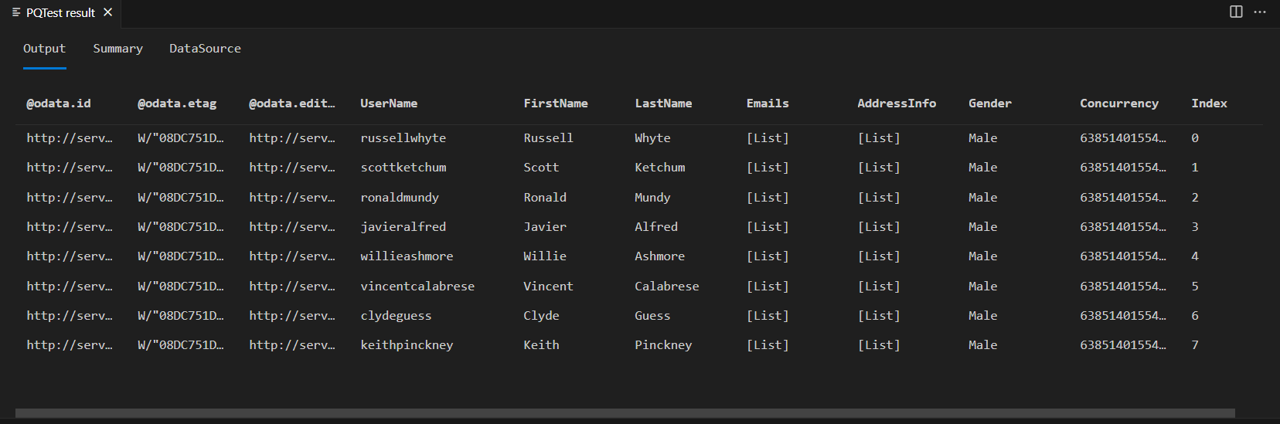
fiddler의 응답 본문을 보면 실제로 사용할 수 있는 데이터 페이지가 더 많다는 것을 나타내는 필드가 포함되어 @odata.nextLink 있음을 알 수 있습니다.
{
"@odata.context": "https://services.odata.org/V4/TripPinService/$metadata#People",
"@odata.nextLink": "https://services.odata.org/v4/TripPinService/People?%24skiptoken=8",
"value": [
{ },
{ },
{ }
]
}
TripPin에 대한 페이징 구현
이제 확장을 다음과 같이 변경합니다.
- 일반
Table.GenerateByPage함수 가져오기 GetAllPagesByNextLink모든 페이지를 함께 붙이는 데 사용하는Table.GenerateByPage함수 추가GetPage단일 데이터 페이지를 읽을 수 있는 함수 추가GetNextLink응답에서 다음 URL을 추출하는 함수 추가- 새 페이지 판독기 함수를 사용하도록 업데이트
TripPin.Feed
참고 항목
이 자습서의 앞부분에서 설명한 대로 페이징 논리는 데이터 원본마다 다릅니다. 여기서 구현은 논리를 응답에서 반환된 다음 링크를 사용하는 원본에 다시 사용할 수 있어야 하는 함수로 분리하려고 합니다.
Table.GenerateByPage
원본에서 반환하는 (잠재적으로) 여러 페이지를 단일 테이블로 결합하기 위해 사용합니다 Table.GenerateByPage. 이 함수는 해당 이름에서 제안하는 것만 수행해야 하는 함수를 인수 getNextPage 로 사용합니다. 데이터의 다음 페이지를 가져옵니다. Table.GenerateByPage 는 함수를 getNextPage 반복적으로 호출하며, 결과를 전달할 때마다 더 이상 페이지를 사용할 수 없다는 신호를 다시 null 반환할 때까지 마지막으로 호출된 결과를 생성합니다.
이 함수는 파워 쿼리의 표준 라이브러리에 속하지 않으므로 소스 코드를 .pq 파일에 복사해야 합니다.
GetAllPagesByNextLink 구현
함수 본 GetAllPagesByNextLink 문은 에 대한 함수 인수를 getNextPage Table.GenerateByPage구현합니다. 함수를 GetPage 호출하고 이전 호출의 레코드 필드에서 meta 데이터의 NextLink 다음 페이지에 대한 URL을 검색합니다.
// Read all pages of data.
// After every page, we check the "NextLink" record on the metadata of the previous request.
// Table.GenerateByPage will keep asking for more pages until we return null.
GetAllPagesByNextLink = (url as text) as table =>
Table.GenerateByPage((previous) =>
let
// if previous is null, then this is our first page of data
nextLink = if (previous = null) then url else Value.Metadata(previous)[NextLink]?,
// if NextLink was set to null by the previous call, we know we have no more data
page = if (nextLink <> null) then GetPage(nextLink) else null
in
page
);
GetPage 구현
GetPage 함수는 Web.Contents를 사용하여 TripPin 서비스에서 단일 데이터 페이지를 검색하고 응답을 테이블로 변환합니다. Web.Contents의 응답을 함수에 전달하여 GetNextLink 다음 페이지의 URL을 추출하고 반환된 테이블(데이터 페이지)의 레코드에 meta 설정합니다.
이 구현은 이전 자습서에서 호출의 TripPin.Feed 약간 수정된 버전입니다.
GetPage = (url as text) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value])
in
data meta [NextLink = nextLink];
GetNextLink 구현
함수는 GetNextLink 단순히 필드에 대한 @odata.nextLink 응답 본문을 검사 값을 반환합니다.
// In this implementation, 'response' will be the parsed body of the response after the call to Json.Document.
// Look for the '@odata.nextLink' field and simply return null if it doesn't exist.
GetNextLink = (response) as nullable text => Record.FieldOrDefault(response, "@odata.nextLink");
모든 항목 요약
페이징 논리를 구현하는 마지막 단계는 새 함수를 사용하도록 업데이트 TripPin.Feed 하는 것입니다. 지금은 단순히 호출하고 GetAllPagesByNextLink있지만 후속 자습서에서는 스키마 적용 및 쿼리 매개 변수 논리와 같은 새로운 기능을 추가합니다.
TripPin.Feed = (url as text) as table => GetAllPagesByNextLink(url);
자습서의 앞부분에서 동일한 테스트 쿼리 를 다시 실행하는 경우 이제 페이지 판독기가 작동하는 것을 볼 수 있습니다. 응답에 8개가 아닌 24개의 행이 있음을 확인할 수 있습니다.
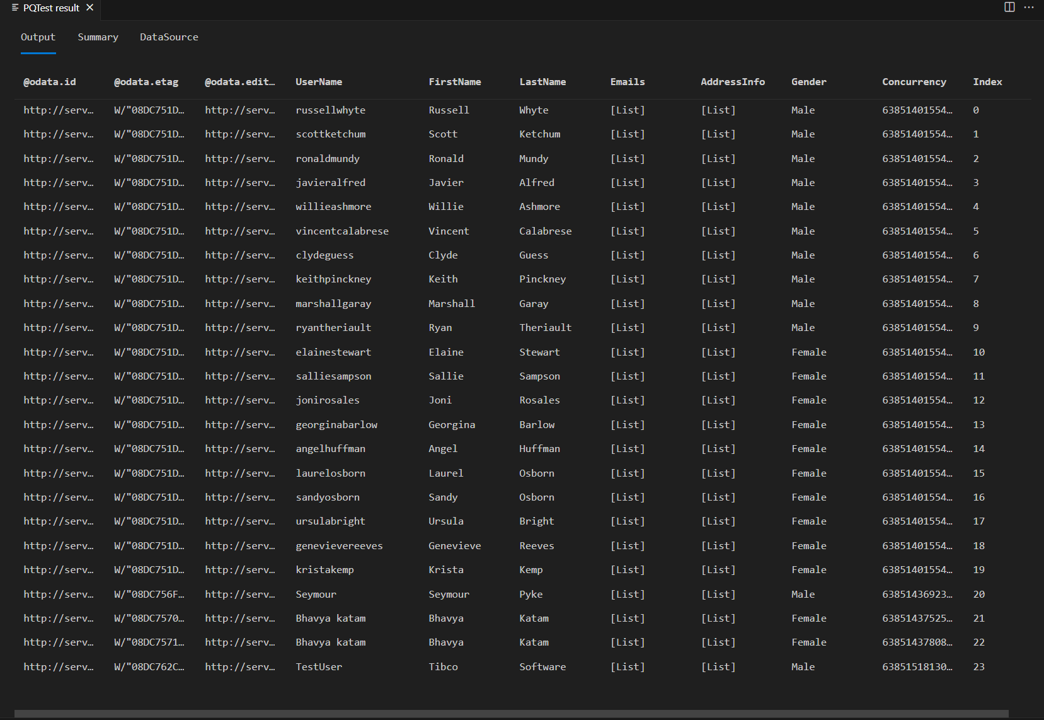
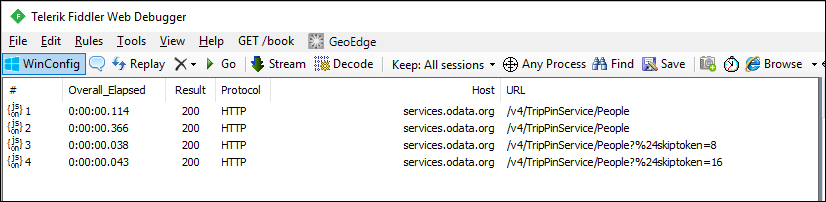
Fiddler에서 요청을 살펴보면 이제 각 데이터 페이지에 대한 별도의 요청이 표시됩니다.
참고 항목
서비스에서 데이터의 첫 번째 페이지에 대한 중복된 요청을 확인할 수 있습니다. 이는 이상적이지 않습니다. 추가 요청은 M 엔진의 스키마 검사 동작의 결과입니다. 지금은 이 문제를 무시하고 명시적 스키마를 적용하는 다음 자습서에서 해결합니다.
결론
이 단원에서는 Rest API에 대한 페이지 매김 지원을 구현하는 방법을 보여 줍니다. 논리는 API마다 다를 수 있지만 여기에 설정된 패턴은 사소한 수정으로 재사용할 수 있어야 합니다.
다음 단원에서는 간단한 데이터 형식Json.Document을 number 넘어 데이터에 명시적 스키마를 text 적용하는 방법을 살펴보겠습니다.