TripPin 10부 - 기본 쿼리 폴딩
참고 항목
이 콘텐츠는 현재 Visual Studio의 로그에 대한 레거시 구현의 콘텐츠를 참조합니다. Visual Studio Code의 새 파워 쿼리 SDK를 포함하도록 콘텐츠가 곧 업데이트될 예정입니다.
이 다중 파트 자습서에서는 파워 쿼리에 대한 새 데이터 원본 확장의 생성에 대해 설명합니다. 이 자습서는 순차적으로 수행됩니다. 각 단원은 이전 단원에서 만든 커넥터를 기반으로 하여 커넥터에 새 기능을 증분 방식으로 추가합니다.
이 단원에서는 다음을 수행합니다.
- 쿼리 폴딩의 기본 사항 알아보기
- Table.View 함수에 대해 알아보기
- 다음을 위해 OData 쿼리 폴딩 처리기를 복제합니다.
$top$skip$count$select$orderby
M 언어의 강력한 기능 중 하나는 하나 이상의 기본 데이터 원본에 변환 작업을 푸시하는 기능입니다. 이 기능을 쿼리 폴딩이라고 합니다(다른 도구/기술은 조건자 푸시다운 또는 쿼리 위임과 유사한 함수라고도 함).
OData.Feed 또는 Odbc.DataSource와 같은 기본 제공 쿼리 폴딩 기능이 있는 M 함수를 사용하는 사용자 지정 커넥터를 만들 때 커넥터는 자동으로 이 기능을 무료로 상속합니다.
이 자습서에서는 Table.View 함수에 대한 함수 처리기를 구현하여 OData에 대한 기본 제공 쿼리 폴딩 동작을 복제본(replica). 자습서의 이 부분에서는 구현하기 쉬운 처리기 중 일부(즉, 식 구문 분석 및 상태 추적이 필요하지 않은 처리기)를 구현합니다.
OData 서비스가 제공할 수 있는 쿼리 기능에 대해 자세히 알아보려면 OData v4 URL 규칙으로 이동합니다.
참고 항목
앞에서 설명한 대로 OData.Feed 함수는 쿼리 폴딩 기능을 자동으로 제공합니다. TripPin 시리즈는 OData 서비스를 OData.Feed 대신 Web.Contents를 사용하여 일반 REST API로 처리하므로 쿼리 폴딩 처리기를 직접 구현해야 합니다. 실제 사용의 경우 가능한 한 OData.Feed를 사용하는 것이 좋습니다.
쿼리 폴딩에 대한 자세한 내용은 파워 쿼리의 쿼리 평가 및 쿼리 폴딩 개요로 이동합니다.
Table.View 사용
Table.View 함수를 사용하면 사용자 지정 커넥터가 데이터 원본에 대한 기본 변환 처리기를 재정의할 수 있습니다. Table.View의 구현은 하나 이상의 지원되는 처리기에 대한 함수를 제공합니다. 처리기가 중요하지 않거나 평가 중에 반환되는 error 경우 M 엔진은 기본 처리기로 대체됩니다.
사용자 지정 커넥터가 Web.Contents와 같은 암시적 쿼리 폴딩을 지원하지 않는 함수를 사용하는 경우 기본 변환 처리기는 항상 로컬에서 수행됩니다. 연결하려는 REST API가 쿼리의 일부로 쿼리 매개 변수를 지원하는 경우 Table.View 를 사용하면 변환 작업을 서비스에 푸시할 수 있는 최적화를 추가할 수 있습니다.
Table.View 함수에는 다음과 같은 서명이 있습니다.
Table.View(table as nullable table, handlers as record) as table
구현은 기본 데이터 원본 함수를 래핑합니다. Table.View에는 다음 두 가지 필수 처리기가 있습니다.
GetType- 쿼리 결과의 예상table type을 반환합니다.GetRows- 데이터 원본 함수의 실제table결과를 반환합니다.
가장 간단한 구현은 다음 예제와 유사합니다.
TripPin.SuperSimpleView = (url as text, entity as text) as table =>
Table.View(null, [
GetType = () => Value.Type(GetRows()),
GetRows = () => GetEntity(url, entity)
]);
다음이 TripPinNavTable 아닌 GetEntity호출 TripPin.SuperSimpleView 하도록 함수를 업데이트합니다.
withData = Table.AddColumn(rename, "Data", each TripPin.SuperSimpleView(url, [Name]), type table),
단위 테스트를 다시 실행하면 함수의 동작이 변경되지 않습니다. 이 경우 Table.View 구현은 단순히 호출을 통해 전달됩니다 GetEntity. 아직 변환 처리기를 구현하지 않았으므로 원래 url 매개 변수는 그대로 다시 기본.
Table.View의 초기 구현
Table.View의 위의 구현은 간단하지만 유용하지는 않습니다. 다음 구현은 기준선으로 사용되며 접기 기능을 구현하지는 않지만 수행해야 하는 스캐폴딩이 있습니다.
TripPin.View = (baseUrl as text, entity as text) as table =>
let
// Implementation of Table.View handlers.
//
// We wrap the record with Diagnostics.WrapHandlers() to get some automatic
// tracing if a handler returns an error.
//
View = (state as record) => Table.View(null, Diagnostics.WrapHandlers([
// Returns the table type returned by GetRows()
GetType = () => CalculateSchema(state),
// Called last - retrieves the data from the calculated URL
GetRows = () =>
let
finalSchema = CalculateSchema(state),
finalUrl = CalculateUrl(state),
result = TripPin.Feed(finalUrl, finalSchema),
appliedType = Table.ChangeType(result, finalSchema)
in
appliedType,
//
// Helper functions
//
// Retrieves the cached schema. If this is the first call
// to CalculateSchema, the table type is calculated based on
// the entity name that was passed into the function.
CalculateSchema = (state) as type =>
if (state[Schema]? = null) then
GetSchemaForEntity(entity)
else
state[Schema],
// Calculates the final URL based on the current state.
CalculateUrl = (state) as text =>
let
urlWithEntity = Uri.Combine(state[Url], state[Entity])
in
urlWithEntity
]))
in
View([Url = baseUrl, Entity = entity]);
Table.View 호출을 보면 레코드Diagnostics.WrapHandlers 주위에 추가 래퍼 함수가 handlers 표시됩니다. 이 도우미 함수는 진단 모듈(추가 진단 단원에서 도입됨)에서 찾을 수 있으며 개별 처리기에서 발생한 오류를 자동으로 추적하는 유용한 방법을 제공합니다.
GetType 및 GetRows 함수는 두 개의 새로운 도우미 함수를 사용하도록 업데이트됩니다CalculateUrl.CalculateSchema 현재 이러한 함수의 구현은 매우 간단합니다. 이 함수에는 이전에 함수에서 GetEntity 수행한 작업의 일부가 포함되어 있습니다.
마지막으로 매개 변수를 허용하는 내부 함수(View)를 정의합니다 state .
더 많은 처리기를 구현할 때 내부 함수를 재귀적으로 호출 View 하여 진행하면서 업데이트하고 전달 state 합니다.
함수를 TripPinNavTable 다시 업데이트하고 호출을 TripPin.SuperSimpleView 새 TripPin.View 함수에 대한 호출로 바꾼 다음 단위 테스트를 다시 실행합니다. 새 기능은 아직 표시되지 않지만 이제 테스트에 대한 견고한 기준이 있습니다.
쿼리 폴딩 구현
쿼리를 접을 수 없을 때 M 엔진이 자동으로 로컬 처리로 되돌아가므로 Table.View 처리기가 제대로 작동하는지 확인하기 위해 몇 가지 추가 단계를 수행해야 합니다.
접기 동작의 유효성을 검사하는 수동 방법은 Fiddler와 같은 도구를 사용하여 단위 테스트에서 수행하는 URL 요청을 확인하는 것입니다. 또는 실행 중인 전체 URL을 내보내기 위해 TripPin.Feed 추가한 진단 로깅에 처리기가 추가하는 OData 쿼리 문자열 매개 변수가 포함되어야 합니다 .
쿼리 폴딩의 유효성을 검사하는 자동화된 방법은 쿼리가 완전히 접지 않는 경우 단위 테스트 실행이 강제로 실패하도록 하는 것입니다. 프로젝트 속성을 열고 접기 실패 시 오류를 True로 설정하여 이 작업을 수행할 수 있습니다. 이 설정을 사용하도록 설정하면 로컬 처리가 필요한 모든 쿼리에서 다음 오류가 발생합니다.
식을 원본으로 접을 수 없습니다. 더 간단한 식을 사용해 보세요.
하나 이상의 테이블 변환이 포함된 단위 테스트 파일에 새 Fact 항목을 추가하여 이를 테스트할 수 있습니다.
// Query folding tests
Fact("Fold $top 1 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Airlines, 1)
)
참고 항목
접기 오류에 대한 오류 설정은 "전부 또는 전혀" 접근 방식입니다. 단위 테스트의 일부로 접도록 설계되지 않은 쿼리를 테스트하려면 그에 따라 테스트를 사용하거나 사용하지 않도록 설정하는 조건부 논리를 추가해야 합니다.
이 자습서의 다시 기본 섹션에서는 각각 새 Table.View 처리기를 추가합니다. 먼저 실패한 단위 테스트를 추가한 다음 M 코드를 구현하여 해결하는 TDD(Test Driven Development) 접근 방식을 사용합니다.
다음 처리기 섹션에서는 처리기에서 제공하는 기능, OData에 해당하는 쿼리 구문, 단위 테스트 및 구현에 대해 설명합니다. 앞에서 설명한 스캐폴딩 코드를 사용하여 각 처리기 구현에는 두 가지 변경 내용이 필요합니다.
- 레코드를 업데이트하는 Table.View 에 처리기를 추가합니다
state. CalculateUrl값을state검색하고 URL 및/또는 쿼리 문자열 매개 변수에 추가하도록 수정합니다.
OnTake를 사용하여 Table.FirstN 처리
OnTake 처리기는 매개 변수를 count 받습니다. 이 매개 변수는 가져올 최대 행 수입니다GetRows.
OData 용어에서 이를 $top 쿼리 매개 변수로 변환할 수 있습니다.
다음 단위 테스트를 사용합니다.
// Query folding tests
Fact("Fold $top 1 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Airlines, 1)
),
Fact("Fold $top 0 on Airports",
#table( type table [Name = text, IataCode = text, Location = record] , {} ),
Table.FirstN(Airports, 0)
),
이러한 테스트는 모두 Table.FirstN을 사용하여 결과 집합을 첫 번째 X 행 수로 필터링합니다. 폴딩 실패 시 오류(기본값)로 설정된 False 상태에서 이러한 테스트를 실행하는 경우 테스트가 성공하지만 Fiddler를 실행하거나 추적 로그를 검사 경우 보내는 요청에 OData 쿼리 매개 변수가 포함되지 않습니다.
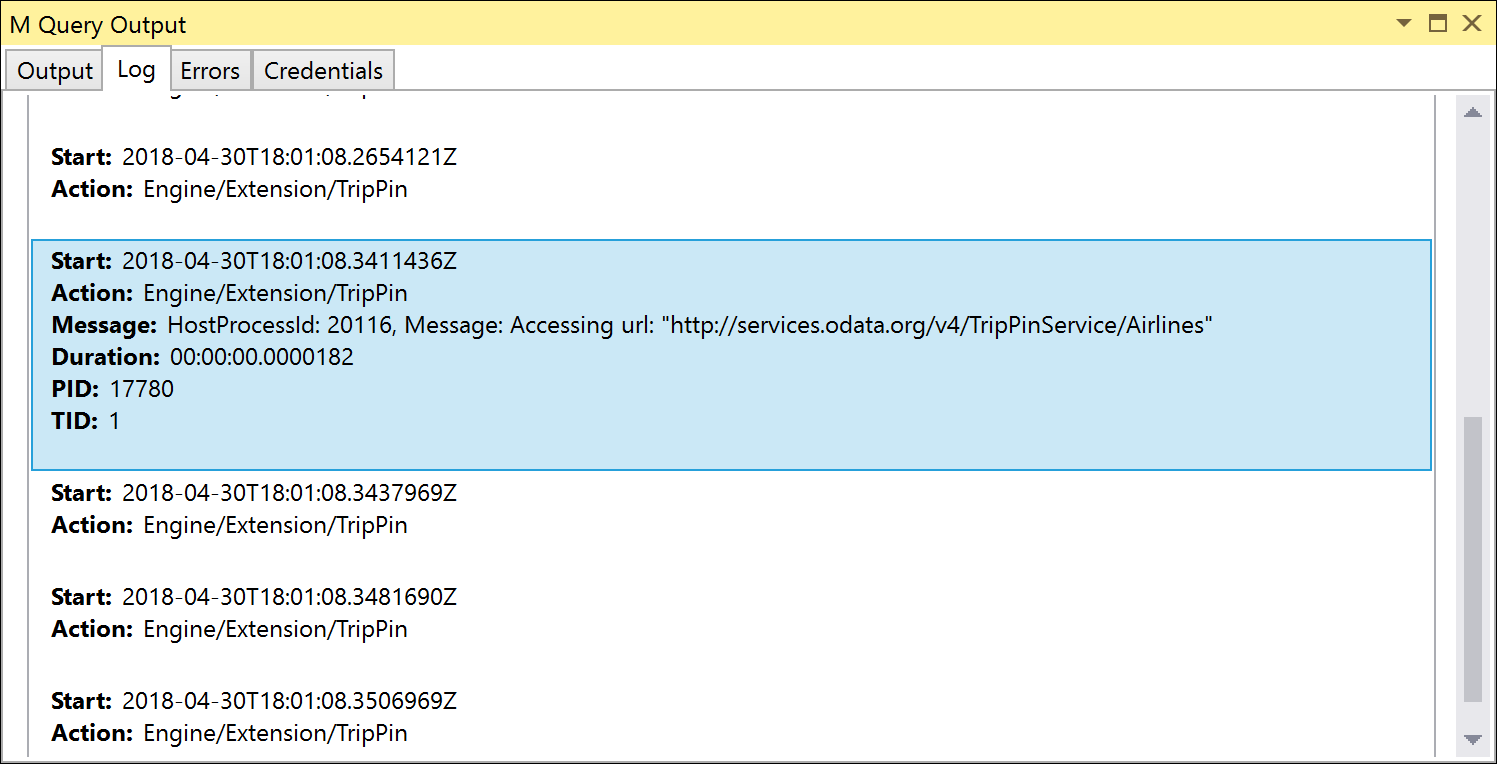
접기 실패 True시 오류를 설정하면 오류와 함께 테스트가 Please try a simpler expression. 실패합니다. 이 오류를 해결하려면 첫 번째 Table.View 처리기를 정의해야 합니다 OnTake.
OnTake 처리기는 다음 코드와 같습니다.
OnTake = (count as number) =>
let
// Add a record with Top defined to our state
newState = state & [ Top = count ]
in
@View(newState),
함수는 CalculateUrl 레코드에서 state 값을 추출 Top 하고 쿼리 문자열에서 올바른 매개 변수를 설정하도록 업데이트됩니다.
// Calculates the final URL based on the current state.
CalculateUrl = (state) as text =>
let
urlWithEntity = Uri.Combine(state[Url], state[Entity]),
// Uri.BuildQueryString requires that all field values
// are text literals.
defaultQueryString = [],
// Check for Top defined in our state
qsWithTop =
if (state[Top]? <> null) then
// add a $top field to the query string record
defaultQueryString & [ #"$top" = Number.ToText(state[Top]) ]
else
defaultQueryString,
encodedQueryString = Uri.BuildQueryString(qsWithTop),
finalUrl = urlWithEntity & "?" & encodedQueryString
in
finalUrl
단위 테스트를 다시 실행하면 액세스하는 URL에 매개 변수가 $top 포함됩니다. URL 인코딩 $top 으로 인해 OData %24top서비스는 자동으로 변환할 수 있을 만큼 스마트합니다.
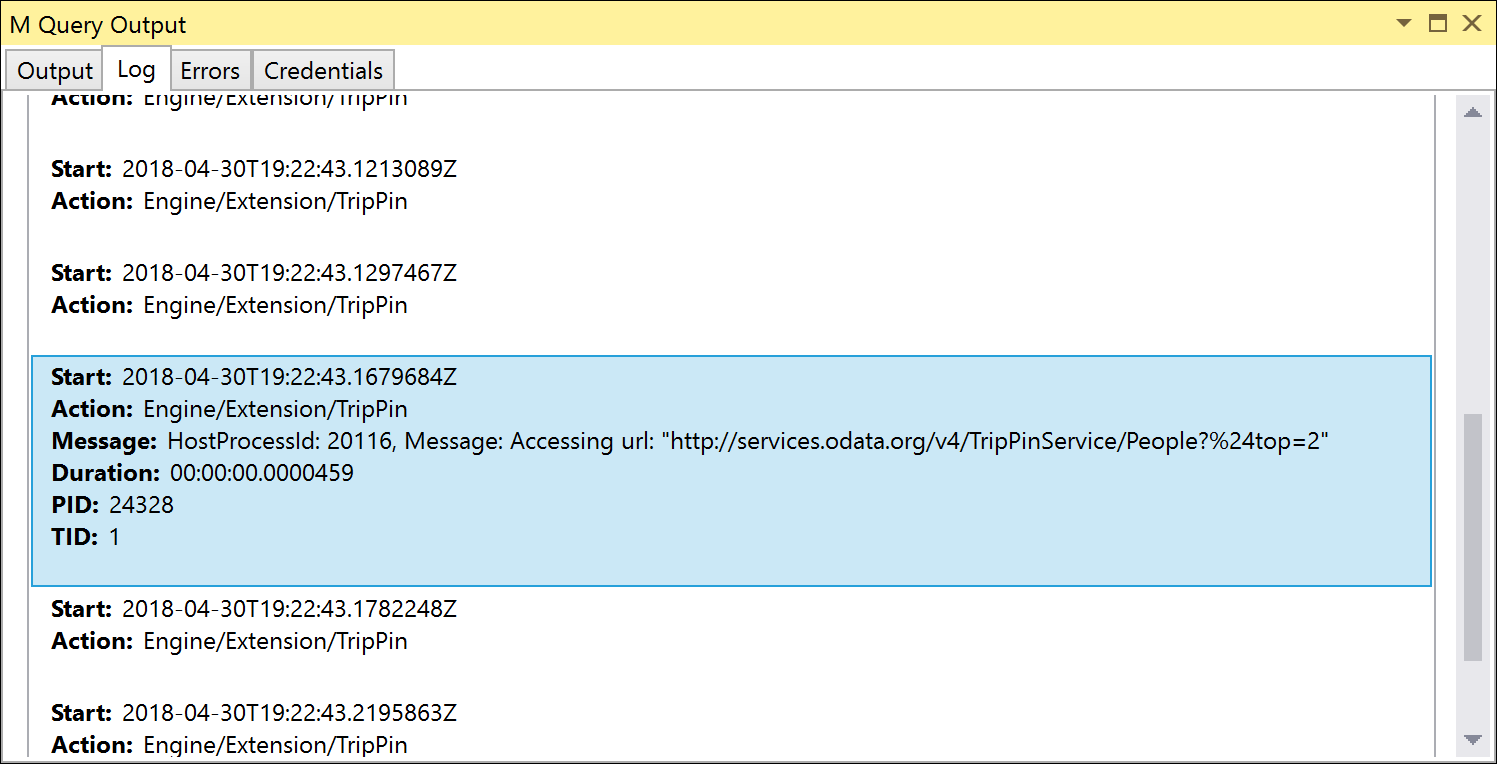
OnSkip을 사용하여 Table.Skip 처리
OnSkip 처리기는 다음과 같습니다OnTake. 결과 집합에서 건너뛸 행 수인 매개 변수를 받 count 습니다. 이 처리기는 OData $skip 쿼리 매개 변수로 잘 변환됩니다.
단위 테스트:
// OnSkip
Fact("Fold $skip 14 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"EK", "Emirates"}} ),
Table.Skip(Airlines, 14)
),
Fact("Fold $skip 0 and $top 1",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Table.Skip(Airlines, 0), 1)
),
구현:
// OnSkip - handles the Table.Skip transform.
// The count value should be >= 0.
OnSkip = (count as number) =>
let
newState = state & [ Skip = count ]
in
@View(newState),
업데이트 일치:CalculateUrl
qsWithSkip =
if (state[Skip]? <> null) then
qsWithTop & [ #"$skip" = Number.ToText(state[Skip]) ]
else
qsWithTop,
추가 정보: Table.Skip
OnSelectColumns를 사용하여 Table.SelectColumns 처리
OnSelectColumns 사용자가 결과 집합에서 열을 선택하거나 제거할 때 처리기가 호출됩니다. 처리기는 선택할 하나 이상의 열을 나타내는 값을 받 list text 습니다.
OData 용어에서 이 작업은 $select 쿼리 옵션에 매핑됩니다.
여러 열이 있는 테이블을 처리할 때 열 선택을 접을 때의 장점이 명백해집니다. $select 연산자는 결과 집합에서 선택되지 않은 열을 제거하여 보다 효율적인 쿼리를 생성합니다.
단위 테스트:
// OnSelectColumns
Fact("Fold $select single column",
#table( type table [AirlineCode = text] , {{"AA"}} ),
Table.FirstN(Table.SelectColumns(Airlines, {"AirlineCode"}), 1)
),
Fact("Fold $select multiple column",
#table( type table [UserName = text, FirstName = text, LastName = text],{{"russellwhyte", "Russell", "Whyte"}}),
Table.FirstN(Table.SelectColumns(People, {"UserName", "FirstName", "LastName"}), 1)
),
Fact("Fold $select with ignore column",
#table( type table [AirlineCode = text] , {{"AA"}} ),
Table.FirstN(Table.SelectColumns(Airlines, {"AirlineCode", "DoesNotExist"}, MissingField.Ignore), 1)
),
처음 두 테스트는 Table.SelectColumns를 사용하여 서로 다른 수의 열을 선택하고 테스트 사례를 간소화하기 위해 Table.FirstN 호출을 포함합니다.
참고 항목
테스트가 단순히 열 이름을 반환하는 경우(데이터가 아닌 Table.ColumnNames 사용) OData 서비스에 대한 요청은 실제로 전송되지 않습니다. 이는 호출이 M 엔진이 결과를 계산하는 GetType 데 필요한 모든 정보를 포함하는 스키마를 반환하기 때문입니다.
세 번째 테스트는 MissingField.Ignore 옵션을 사용합니다. 이 옵션은 M 엔진에 결과 집합에 없는 선택한 열을 무시하도록 지시합니다. 처리기는 이 OnSelectColumns 옵션에 대해 걱정할 필요가 없습니다. M 엔진은 자동으로 처리합니다(즉, 누락된 열은 목록에 포함되지 columns 않음).
참고 항목
Table.SelectColumns의 다른 옵션인 MissingField.UseNull에는 처리기를 구현하는 커넥터가 OnAddColumn필요합니다. 이 작업은 후속 단원에서 수행됩니다.
구현 OnSelectColumns 은 다음 두 가지 작업을 수행합니다.
- 선택한 열 목록을 에 추가합니다
state. - 올바른 테이블 형식을
Schema설정할 수 있도록 값을 다시 계산합니다.
OnSelectColumns = (columns as list) =>
let
// get the current schema
currentSchema = CalculateSchema(state),
// get the columns from the current schema (which is an M Type value)
rowRecordType = Type.RecordFields(Type.TableRow(currentSchema)),
existingColumns = Record.FieldNames(rowRecordType),
// calculate the new schema
columnsToRemove = List.Difference(existingColumns, columns),
updatedColumns = Record.RemoveFields(rowRecordType, columnsToRemove),
newSchema = type table (Type.ForRecord(updatedColumns, false))
in
@View(state &
[
SelectColumns = columns,
Schema = newSchema
]
),
CalculateUrl 는 상태의 열 목록을 검색하고 매개 변수에 대한 열 목록을 구분 기호 $select 와 결합하도록 업데이트됩니다.
// Check for explicitly selected columns
qsWithSelect =
if (state[SelectColumns]? <> null) then
qsWithSkip & [ #"$select" = Text.Combine(state[SelectColumns], ",") ]
else
qsWithSkip,
OnSort를 사용하여 Table.Sort 처리
OnSort 처리기는 형식의 레코드 목록을 받습니다.
type [ Name = text, Order = Int16.Type ]
각 레코드에는 Name 열 이름을 나타내는 필드와 Order.Ascending 또는 Order.Descending과 Order 같은 필드가 포함됩니다.
OData 용어에서 이 작업은 $orderby 쿼리 옵션에 매핑됩니다.
구문에는 $orderby 열 이름 뒤에 오 asc 름차순 또는 내림차순을 나타내거나 desc 오름차순으로 지정합니다. 여러 열을 정렬하면 값이 쉼표로 구분됩니다. 매개 변수에 columns 둘 이상의 항목이 포함된 경우 표시되는 순서를 기본 것이 중요합니다.
단위 테스트:
// OnSort
Fact("Fold $orderby single column",
#table( type table [AirlineCode = text, Name = text], {{"TK", "Turkish Airlines"}}),
Table.FirstN(Table.Sort(Airlines, {{"AirlineCode", Order.Descending}}), 1)
),
Fact("Fold $orderby multiple column",
#table( type table [UserName = text], {{"javieralfred"}}),
Table.SelectColumns(Table.FirstN(Table.Sort(People, {{"LastName", Order.Ascending}, {"UserName", Order.Descending}}), 1), {"UserName"})
)
구현:
// OnSort - receives a list of records containing two fields:
// [Name] - the name of the column to sort on
// [Order] - equal to Order.Ascending or Order.Descending
// If there are multiple records, the sort order must be maintained.
//
// OData allows you to sort on columns that do not appear in the result
// set, so we do not have to validate that the sorted columns are in our
// existing schema.
OnSort = (order as list) =>
let
// This will convert the list of records to a list of text,
// where each entry is "<columnName> <asc|desc>"
sorting = List.Transform(order, (o) =>
let
column = o[Name],
order = o[Order],
orderText = if (order = Order.Ascending) then "asc" else "desc"
in
column & " " & orderText
),
orderBy = Text.Combine(sorting, ", ")
in
@View(state & [ OrderBy = orderBy ]),
업데이트:CalculateUrl
qsWithOrderBy =
if (state[OrderBy]? <> null) then
qsWithSelect & [ #"$orderby" = state[OrderBy] ]
else
qsWithSelect,
GetRowCount를 사용하여 Table.RowCount 처리
구현하는 GetRowCount 다른 쿼리 처리기와 달리 처리기는 결과 집합에 예상되는 행 수인 단일 값을 반환합니다. M 쿼리에서 이 값은 일반적으로 Table.RowCount 변환의 결과입니다.
OData 쿼리의 일부로 이 값을 처리하는 방법에 대한 몇 가지 옵션이 있습니다.
- $count 쿼리 매개 변수로, 결과 집합에서 개수를 별도의 필드로 반환합니다.
- 총 개수만 스칼라 값으로 반환하는 /$count 경로 세그먼트입니다.
쿼리 매개 변수 접근 방식의 단점은 전체 쿼리를 OData 서비스로 보내야 한다는 것입니다. 개수가 결과 집합의 일부로 인라인으로 돌아오므로 결과 집합에서 데이터의 첫 번째 페이지를 처리해야 합니다. 이 프로세스는 전체 결과 집합을 읽고 행을 계산하는 것보다 더 효율적이지만, 원하는 것보다 더 많은 작업을 수행할 수 있습니다.
경로 세그먼트 접근 방식의 장점은 결과에서 단일 스칼라 값만 수신한다는 것입니다. 이 방법을 사용하면 전체 작업이 훨씬 더 효율적입니다. 그러나 OData 사양에 설명된 대로 /$count 경로 세그먼트는 유용성을 제한하는 다른 쿼리 매개 변수(예: $top 또는 $skip)를 포함하는 경우 오류를 반환합니다.
이 자습서에서는 경로 세그먼트 접근 방식을 사용하여 처리기를 구현 GetRowCount 했습니다. 다른 쿼리 매개 변수가 포함된 경우 발생하는 오류를 방지하기 위해 다른 상태 값에 대해 검사 "중요하지 않은 오류"()가... 있는 경우 반환합니다. Table.View 처리기에서 오류를 반환하면 M 엔진에 작업을 접을 수 없으며 대신 기본 처리기로 대체되어야 합니다(이 경우 총 행 수를 계산함).
먼저 단위 테스트를 추가합니다.
// GetRowCount
Fact("Fold $count", 15, Table.RowCount(Airlines)),
경로 세그먼트는 /$count JSON 결과 집합이 아닌 단일 값(일반/텍스트 형식)을 반환하므로 요청을 만들고 결과를 처리하기 위한 새 내부 함수(TripPin.Scalar)도 추가해야 합니다.
// Similar to TripPin.Feed, but is expecting back a scalar value.
// This function returns the value from the service as plain text.
TripPin.Scalar = (url as text) as text =>
let
_url = Diagnostics.LogValue("TripPin.Scalar url", url),
headers = DefaultRequestHeaders & [
#"Accept" = "text/plain"
],
response = Web.Contents(_url, [ Headers = headers ]),
toText = Text.FromBinary(response)
in
toText;
그러면 구현에서 이 함수를 사용합니다(다음에서 state다른 쿼리 매개 변수를 찾을 수 없는 경우).
GetRowCount = () as number =>
if (Record.FieldCount(Record.RemoveFields(state, {"Url", "Entity", "Schema"}, MissingField.Ignore)) > 0) then
...
else
let
newState = state & [ RowCountOnly = true ],
finalUrl = CalculateUrl(newState),
value = TripPin.Scalar(finalUrl),
converted = Number.FromText(value)
in
converted,
CalculateUrl 필드가 에 설정된 경우 함수가 URL에 RowCountOnly state추가 /$count 되도록 업데이트됩니다.
// Check for $count. If all we want is a row count,
// then we add /$count to the path value (following the entity name).
urlWithRowCount =
if (state[RowCountOnly]? = true) then
urlWithEntity & "/$count"
else
urlWithEntity,
이제 새 Table.RowCount 단위 테스트를 통과해야 합니다.
대체 사례를 테스트하려면 오류를 강제로 적용하는 다른 테스트를 추가합니다.
먼저 접기 오류에 대한 작업의 결과를 try 검사 도우미 메서드를 추가합니다.
// Returns true if there is a folding error, or the original record (for logging purposes) if not.
Test.IsFoldingError = (tryResult as record) =>
if ( tryResult[HasError]? = true and tryResult[Error][Message] = "We couldn't fold the expression to the data source. Please try a simpler expression.") then
true
else
tryResult;
그런 다음 Table.RowCount와 Table.FirstN을 모두 사용하여 오류를 강제로 적용하는 테스트를 추가합니다.
// test will fail if "Fail on Folding Error" is set to false
Fact("Fold $count + $top *error*", true, Test.IsFoldingError(try Table.RowCount(Table.FirstN(Airlines, 3)))),
여기서 중요한 점은 작업이 로컬(기본값) 처리기로 대체되므로 falseTable.RowCount 접기 오류 시 오류가 설정된 경우 이 테스트에서 오류를 반환한다는 것입니다. 폴딩 오류 발생 시 오류로 설정된 테스트를 실행하면 true Table.RowCount 실패하고 테스트가 성공할 수 있습니다.
결론
커넥터에 Table.View를 구현하면 코드에 상당한 복잡성이 추가됩니다. M 엔진은 모든 변환을 로컬로 처리할 수 있으므로 Table.View 처리기를 추가해도 사용자에게 새로운 시나리오가 가능하지는 않지만 더 효율적인 처리(그리고 잠재적으로 더 행복한 사용자)가 됩니다. Table.View 처리기의 기본 장점 중 하나는 커넥터에 대한 이전 버전과의 호환성에 영향을 주지 않고 새 기능을 증분 방식으로 추가할 수 있다는 점입니다.
대부분의 커넥터에서 구현 OnTake 해야 하는 중요한(및 기본) 처리기는 반환되는 행 수를 제한하기 $top 때문에 OData로 변환됩니다. 파워 쿼리 환경은 탐색기 및 쿼리 편집기에서 미리 보기를 표시할 때 항상 행을 수행 OnTake 1000 하므로 사용자는 더 큰 데이터 집합으로 작업할 때 성능이 크게 향상될 수 있습니다.