파워 쿼리의 쿼리 참조
이 문서는 Power BI Desktop을 개발하는 데이터 모델러를 대상으로 합니다. 다른 쿼리를 참조하는 파워 쿼리의 쿼리를 정의하기 위한 지침을 제공합니다.
이것이 의미하는 바를 명확하게 설명하자면 다음과 같습니다. 쿼리가 두 번째 쿼리를 참조하는 경우 두 번째 쿼리의 단계가 첫 번째 쿼리의 단계와 결합되고 이보다 먼저 실행되는 것과 같습니다.
몇 가지 쿼리를 고려해 보세요. Query1은 웹 서비스의 데이터를 원본으로 사용하고 로드는 사용하지 않습니다. Query2, Query3, Query4는 모두 Query1을 참조하고 해당 출력은 데이터 모델에 로드됩니다.
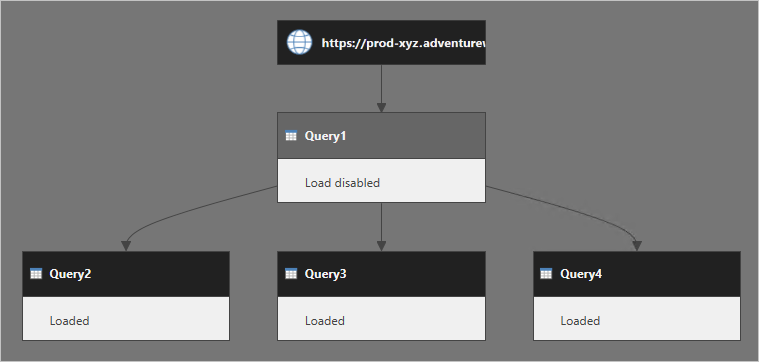
데이터 모델을 새로 고칠 때 파워 쿼리가 Query1 결과를 검색하고 참조된 쿼리에서 다시 사용하는 것으로 가정하는 경우가 많습니다. 이는 잘못된 생각입니다. 실제로 파워 쿼리는 Query2, Query3, Query4를 별도로 실행합니다.
Query2에 Query1 단계가 포함되어 있다고 생각할 수 있습니다. Query3과 Query4도 마찬가지입니다. 다음 다이어그램에서는 쿼리가 실행되는 방식을 보다 명확하게 보여 줍니다.
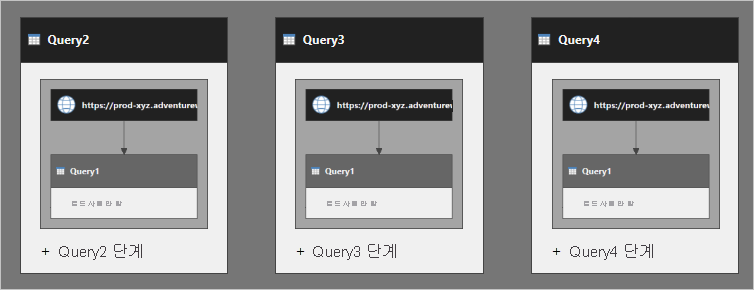
Query1은 세 번 실행됩니다. 여러 번의 실행으로 인해 데이터 새로 고침이 느려지고 데이터 원본에 부정적인 영향을 미칠 수 있습니다.
Query1에서 Table.Buffer 함수를 사용하면 추가 데이터 검색을 제거하지 않습니다. 이 함수는 테이블을 메모리에 버퍼링하며, 버퍼링된 테이블은 동일한 쿼리 실행 내에서만 사용할 수 있습니다. 그러므로 예제에서 Query2가 실행될 때 Query1이 버퍼링될 경우 Query3 및 Query4가 실행될 때는 버퍼링된 데이터를 사용할 수 없습니다. 이러한 쿼리가 데이터를 두 번 더 버퍼링합니다. (각 참조 쿼리가 테이블을 버퍼링하기 때문에 성능에 대한 부정적 영향이 가중될 수 있습니다.)
참고 항목
파워 쿼리 캐싱 아키텍처는 복잡하며 이 문서에서 중점적으로 다루는 내용이 아닙니다. 파워 쿼리는 데이터 원본에서 검색된 데이터를 캐시할 수 있습니다. 그러나 쿼리를 실행할 때 데이터 원본에서 데이터를 두 번 이상 검색할 수 있습니다.
권장 사항
일반적으로 쿼리 전체에서 논리가 중복되지 않도록 쿼리를 참조하는 것을 권장합니다. 그러나 이 문서에 설명된 대로 이 디자인 방법은 데이터 새로 고침 속도를 저하하고 데이터 원본에 과도한 부담을 줄 수 있습니다.
대신 데이터 흐름을 만드는 것이 좋습니다. 데이터 흐름을 사용하면 데이터 새로 고침 시간을 개선하고 데이터 원본에 대한 영향을 줄일 수 있습니다.
원본 데이터와 변환을 캡슐화하도록 데이터 흐름을 디자인할 수 있습니다. 데이터 흐름은 Power BI 서비스의 지속형 데이터 저장소이므로 데이터 검색 속도가 빠릅니다. 따라서 참조 쿼리가 데이터 흐름에 여러 번 요청하는 경우에도 데이터 새로 고침 시간이 향상될 수 있습니다.
예제에서 Query1을 데이터 흐름 엔터티로 새로 디자인하는 경우 Query2, Query3, Query4가 이를 데이터 원본으로 사용할 수 있습니다. 이 디자인에서는 Query1에서 검색된 엔터티가 한 번만 평가됩니다.
관련 콘텐츠
이 문서와 관련된 보다 자세한 내용을 알아보려면 다음 리소스를 참조하세요.
- Power BI의 셀프 서비스 데이터 준비
- Power BI에서 데이터 흐름 만들기 및 사용
- 궁금한 점이 더 있나요? Power BI 커뮤니티에 질문합니다.
- 제안 사항은? Power BI 개선을 위한 아이디어 제공