자동 집계
자동 집계는 최첨단 ML(기계 학습)을 사용하여 보고서 쿼리의 최대 성능을 얻기 위해 DirectQuery 의미 체계 모델을 지속적으로 최적화합니다. 자동 집계는 Power BI의 복합 모델과 함께 처음 도입되었던 기존의 사용자 정의 집계 인프라를 기반으로 구현되었습니다. 자동 집계는 사용자 정의 집계와 달리 구성 및 유지 관리를 위해 방대한 데이터 모델링 및 쿼리 최적화 능력이 필요하지 않습니다. 자동 집계는 자체 학습 및 자체 최적화를 수행합니다. 모든 기술 수준을 갖춘 모델 소유자가 쿼리 성능을 개선하여 대규모 모델에 대해 빠른 보고서 시각화를 제공할 수 있습니다.
자동 집계를 사용하면:
- 더 빠른 보고서 시각화 - 백 엔드 데이터 원본 시스템 대신 자동으로 유지 관리되는 메모리 내 집계 캐시에 의해 보고서 쿼리의 최적의 비율이 반환됩니다. 메모리 내 캐시에 의해 반환되지 않는 이상값 쿼리는 DirectQuery를 사용하여 직접 데이터 원본으로 전달됩니다.
- 균형 잡힌 아키텍처 - 순수 DirectQuery 모드와 비교했을 때 대부분의 쿼리 결과가 Power BI 쿼리 엔진 및 메모리 내 집계 캐시에 의해 반환됩니다. 보고 활동이 정점에 달하는 시기에 데이터 원본 시스템의 쿼리 처리 부하가 크게 줄어들어 데이터 원본 백엔드의 스케일링 성능이 늘어납니다.
- 손쉬운 설정 - 모델 소유자가 모델에 관해 자동 집계 학습을 사용하도록 설정하고 하나 이상의 새로 고침을 예약할 수 있습니다. 첫 번째 학습 및 새로 고침을 통해 자동 집계는 집계 프레임워크 및 최적의 집계를 만들기 시작합니다. 시스템은 시간이 흐름에 따라 자동으로 자체 조정됩니다.
- 미세 조정 – 모델 설정의 단순하고 직관적인 사용자 인터페이스를 사용하여 메모리 내 집계 캐시로부터 반환된 여러 쿼리 백분율의 성능 이득을 추정하고 더 높은 이득을 얻도록 조정할 수 있습니다. 하나의 슬라이드 바 컨트롤을 사용하여 환경을 쉽게 미세 조정할 수 있습니다.
요구 사항
지원되는 계획
자동 집계는 Power BI 용량 단위 Premium, 사용자 단위 Premium 및 Power BI Embedded 모델에서 지원됩니다.
지원되는 데이터 원본
자동 집계는 다음과 같은 데이터 원본에 대해 지원됩니다.
- Azure SQL Database
- Azure Synapse의 전용 SQL 풀
- SQL Server 2019 이상
- Google BigQuery
- Snowflake
- Databricks
- Amazon Redshift
지원되는 모드
자동 집계는 DirectQuery 모드 모델에서 지원됩니다. 가져오기 테이블과 DirectQuery 연결이 모두 포함된 복합 모델 모델이 지원됩니다. 자동 집계는 DirectQuery 연결에 대해서만 지원됩니다.
사용 권한
자동 집계를 사용하도록 설정하고 구성하려면 모델 소유자여야 합니다. 작업 영역 관리자는 소유자 자격으로 인계 받아서 자동 집계 설정을 구성할 수 있습니다.
자동 집계 구성
자동 집계는 모델 설정에서 구성됩니다. 구성 방법은 간단합니다. 자동 집계 학습을 사용하도록 설정하고 하나 이상의 새로 고침을 예약하면 됩니다. 모델에 대한 자동 집계를 구성하기 전에 이 문서를 완전히 숙지해야 합니다. 이 문서에서는 자동 집계가 작동하는 방식에 관해 설명하며, 사용자 환경에 자동 집계가 적합한지 판단하는 데 도움이 될 수 있습니다. 자동 집계 학습을 사용하도록 설정하고, 새로 고침 예약을 구성하고, 환경에 맞게 미세 조정하는 단계별 지침을 수행할 준비가 되면 자동 집계 구성을 참조하세요.
이점
DirectQuery를 사용하면 모델 사용자가 보고서를 열거나 보고서 시각화와 상호 작용할 때마다 DAX(Data Analysis Expressions) 쿼리가 쿼리 엔진으로 전달된 다음, SQL 쿼리로 백 엔드 데이터 원본에 전달됩니다. 데이터 원본은 각 쿼리에 대한 결과를 계산하고 반환해야 합니다. DirectQuery 데이터 원본 왕복은 메모리 내에 저장된 가져오기 모드 모델보다 시간과 프로세스를 많이 사용하여 보고서 시각화의 쿼리 응답 시간이 느려지는 경우가 많습니다.
DirectQuery 모델에 관해 자동 집계를 사용하도록 설정한 경우 데이터 원본 쿼리의 왕복을 방지하여 보고서 쿼리 성능을 향상할 수 있습니다. 미리 집계된 쿼리 결과는 데이터 원본으로 전송되고 다시 반환되는 대신 메모리 내 집계 캐시에 의해 자동으로 반환됩니다. 메모리 내 집계 캐시에 있는 미리 집계된 데이터의 양은 데이터 원본의 팩트 및 세부 정보 테이블에 보관된 데이터의 작은 일부분입니다. 그 결과 보고서 쿼리 성능이 향상될 뿐만 아니라 백 엔드 데이터 원본 시스템에 가중되는 부하도 줄어듭니다. 자동 집계에서는 순수 DirectQuery 모드처럼 메모리 내 캐시에 포함되지 않은 집계가 필요한 임시 쿼리와 보고서의 작은 부분만 백 엔드 데이터 원본으로 전달됩니다.
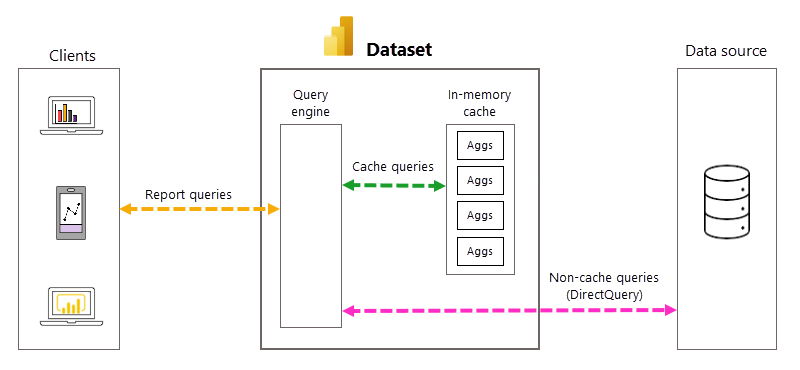
자동 쿼리 및 집계 관리
자동 집계를 사용하면 사용자 정의 집계 테이블을 만들 필요가 없고 미리 집계된 데이터 솔루션을 구현하는 작업이 크게 간소화되지만, 자동 집계가 작동하는 방식을 이해하는 데는 기본 프로세스와 종속성에 관해 알아보는 것이 도움이 됩니다. Power BI는 다음과 같은 항목을 사용하여 자동 집계를 만들고 관리합니다.
쿼리 로그
Power BI가 모델 및 사용자 보고서 쿼리를 쿼리 로그에서 추적합니다. Power BI가 각 모델에 관해 7일 분량의 쿼리 로그 데이터를 보관합니다. 쿼리 로그 데이터는 매일 롤포워드됩니다. 쿼리 로그는 안전하게 보호되며, 사용자에게 표시되거나 XMLA 엔드포인트를 통해 표시되지 않습니다.
학습 작업
선택한 빈도(일 또는 주)의 첫 번째 예약된 모델 새로 고침 작업의 일환으로, Power BI가 쿼리 로그를 평가하여 메모리 내 집계 캐시에 있는 집계가 변화하는 쿼리 패턴에 적응하는지 확인하는 학습 작업을 시작합니다. 메모리 내 집계 테이블이 만들어지거나 업데이트되거나 삭제되며, 캐시에 포함할 집계를 확인하기 위해 특수 쿼리가 데이터 원본으로 전송됩니다. 그러나 계산된 집계 데이터는 학습 중에 메모리 내 캐시에 로드되지 않으며, 후속 새로 고침 작업 중에 로드됩니다.
예를 들어, 일 빈도를 선택했고 예약이 오전 4시, 오전 9시, 오후 2시, 오후 7시에 새로 고침되면, 매일 오전 4시 새로 고침만 학습 작업 및 새로 고침 작업을 모두 포함합니다. 같은 날 오전 9시, 오후 2시. 오후 7시에 예약된 후속 새로 고침은 캐시에 있는 기존 집계를 업데이트하는 새로 고침 작업 전용 작업입니다.
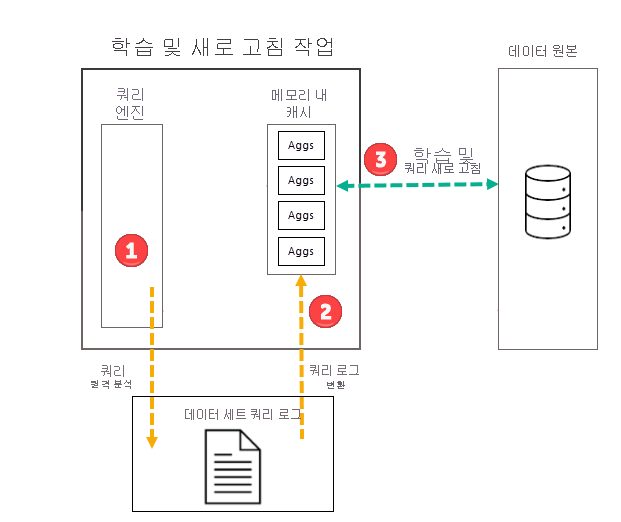
학습 작업은 쿼리 로그에 있는 지난 쿼리를 평가하긴 하지만, 이후 쿼리에 적용될 수 있을 만큼 결과가 충분히 정확합니다. 그러나 새로운 쿼리는 쿼리 로그에서 파생된 쿼리와 다를 수 있으므로 메모리 내 집계에 의해 이후 쿼리가 반환될 것이라는 보장은 없습니다. 메모리 내 집계 캐시에 의해 반환되지 않은 쿼리는 DirectQuery를 사용하여 데이터 원본으로 전달됩니다. 새 쿼리가 발생하는 빈도와 순위에 따라, 해당 쿼리에 대한 집계는 다음번 학습 작업에서 메모리 내 집계 캐시에 포함될 수 있습니다.
학습 작업에는 60분의 시간 제한이 있습니다. 학습이 시간 제한 내에서 전체 쿼리 로그를 처리할 수 없는 경우 모델 새로 고침 기록에 알림이 기록되고 다음에 시작될 때 학습이 다시 시작됩니다. 전체 쿼리 로그가 처리될 때 학습 주기가 완료되고 기존 자동 집계를 대체합니다.
새로 고침 작업
이전에 설명한 것처럼, 선택한 빈도에 관해 첫 번째 예약된 새로 고침의 일환으로 학습 작업이 완료되면 Power BI가 새로운 집계 데이터와 업데이트된 집계 데이터를 메모리 내 집계 캐시에 로드하고 (학습 알고리즘의 판단에 따라) 더 이상 충분히 높은 순위를 갖지 않는 집계를 제거하는 새로 고침 작업을 수행합니다. 선택한 일 또는 주 빈도에 대한 모든 후속 새로 고침은 데이터 원본을 쿼리하여 캐시에 있는 기존 집계 데이터를 업데이트하는 새로 고침 전용 작업입니다. 이전 예제를 사용하여 같은 날 오전 9시, 오후 2시, 오후 7시에 예약된 새로 고침은 새로 고침 전용 작업입니다.
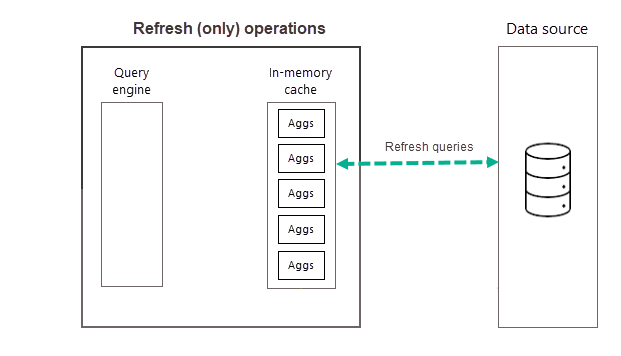
하루(또는 한 주) 동안 정기적인 새로 고침을 예약하면 캐시에 있는 집계 데이터가 백 엔드 데이터 원본에 있는 데이터에 맞게 보다 최신 상태로 유지될 수 있습니다. 모델 설정을 통해 하루에 최대 48개의 새로 고침을 예약하여 집계 캐시에 의해 반환되는 보고서 쿼리가 백 엔드 데이터 원본에 있는 가장 최근에 새로 고침 된 데이터를 기반으로 결과를 가져오도록 할 수 있습니다.
주의
학습 및 새로 고침 작업은 Power BI 서비스와 데이터 원본 시스템 양쪽 모두에서 프로세스와 리소스가 많이 사용되는 작업입니다. 집계를 사용하는 쿼리의 비율을 늘리면 학습 및 새로 고침 작업 중에 데이터 원본에서 더 많은 집계를 쿼리하고 계산해야 하므로 시스템 리소스가 과도하게 사용될 가능성이 높아지고 그로 인해 시간 초과가 발생할 수 있습니다. 자세히 알아보려면 미세 조정을 참조하세요.
주문형 학습
앞에서 설명한 것처럼 학습 주기는 단일 데이터 새로 고침 주기의 시간 제한 내에 완료되지 않을 수 있습니다. 학습을 포함하는 다음 예약된 새로 고침 주기까지 기다리지 않으려면 모델 설정에서 지금 학습 및 새로 고침을 선택하여 요청 시 자동 집계 학습을 트리거할 수도 있습니다. 지금 학습 및 새로 고침을 사용하면 학습 작업과 새로 고침 작업이 모두 트리거됩니다. 모델 새로 고침 기록을 확인하여 필요한 경우 다른 주문형 학습 및 새로 고침 작업을 실행하기 전에 현재 작업이 완료되었는지 확인합니다.
새로 고침 기록
각 새로 고침 작업은 모델 새로 고침 기록에 기록됩니다. 구성된 쿼리 비율에 대해 사용 중인 캐시의 집계 수를 포함하여 각 새로 고침에 대한 중요한 정보가 표시됩니다. 새로 고침 기록을 보려면 모델 설정 페이지에서 새로 고침 기록을 선택합니다. 더 자세히 드릴다운하려면 세부 정보 표시를 선택합니다.

새로 고침 기록을 정기적으로 검토하면 예약된 새로 고침 작업이 허용 가능한 기간 내에 완료되고 있는지 확인할 수 있습니다. 예약된 다음번 새로 고침이 시작되기 전에 새로 고침 작업이 성공적으로 완료되고 있는지 확인하세요.
학습 및 새로 고침 실패
Power BI는 선택한 일 또는 주 빈도에 관해 첫 번째 예약된 새로 고침의 일환으로 학습 및 새로 고침 작업을 수행하지만, 이 두 작업은 별도의 트랜잭션으로 구현됩니다. 학습 작업이 시간 제한 내에서 쿼리 로그를 완전히 처리할 수 없는 경우 Power BI는 이전 학습 상태를 사용하여 기존 집계(및 복합 모델의 일반 테이블)를 계속 새로 고칩니다. 이 경우 새로 고침 기록은 새로 고침이 성공했음을 나타내고 학습은 다음에 학습이 시작될 때 쿼리 로그 처리를 다시 시작합니다. 클라이언트 보고서 쿼리 패턴이 변경되고 집계가 아직 조정되지 않은 경우 쿼리 성능이 비교적 최적화되지 않을 수 있으나 달성된 성능 수준은 집계를 사용하지 않은 순수 DirectQuery 모델보다 훨씬 높을 것입니다.

학습 작업에서 쿼리 로그 처리를 완료하는 데 너무 많은 주기가 필요한 경우 모델 설정에서 메모리 내 집계 캐시를 사용하는 쿼리의 비율을 줄이는 것이 좋습니다. 이렇게 하면 캐시에서 만들어지는 집계의 개수는 줄어드는 한편 학습 및 새로 고침 작업이 완료되기까지 더 많은 시간이 사용됩니다. 자세히 알아보려면 미세 조정을 참조하세요.
학습은 성공했으나 새로 고침은 실패한 경우, 메모리 내 집계 캐시에 결과가 없으므로 전체 새로 고침이 실패로 표시됩니다.
새로 고침을 예약할 때 새로 고침이 실패할 경우 이메일 알림을 지정할 수 있습니다.
사용자 정의 집계와 자동 집계
Power BI의 사용자 정의 집계는 모델의 숨겨진 집계 테이블을 기반으로 수동으로 구성할 수 있습니다. 사용자 정의 집계 구성하기는 높은 수준의 데이터 모델링 및 쿼리 최적화 능력이 요구되는 복잡한 작업입니다. 반면에 자동 집계는 AI 기반 시스템의 한 기능으로 이 복잡성을 제거합니다. 정적인 상태로 유지되는 사용자 정의 집계와 달리, Power BI가 지속적으로 쿼리 로그를 유지 관리하며 이 로그를 통해 ML(기계 학습) 예측 모델링 알고리즘을 바탕으로 쿼리 패턴을 알아냅니다. 미리 집계된 데이터는 쿼리 패턴 분석을 바탕으로 메모리 내에서 계산되고 저장됩니다. 자동 집계에서는 모델이 자체 학습 및 자체 최적화를 수행합니다. 클라이언트 보고서 쿼리 패턴이 변경되면 자동 집계가 가장 자주 사용된 집계를 우선적으로 캐싱하여 이에 맞게 적응합니다.
자동 집계는 기존의 사용자 정의 집계 인프라를 기반으로 구현되었으므로 하나의 모델에서 사용자 정의 집계와 자동 집계를 모두 사용하는 것이 가능합니다. 숙련된 데이터 모델러는 DirectQuery, (증분 새로 고침을 사용하거나 사용하지 않는) 가져오기 또는 이중 스토리지 모드를 사용하여 테이블에 관해 집계를 정의하는 동시에 사용자 정의 집계 테이블에 포함되지 않는 쿼리에 관해 DirectQuery 연결을 통해 자동 집계의 이점을 사용할 수 있습니다. 이러한 유연성 덕분에 쿼리 부하를 줄이고 병목을 방지하는 균형 잡힌 아키텍처가 가능해집니다.
자동 집계 학습 알고리즘에 의해 메모리 내 캐시에서 만들어진 집계는 System 집계로 식별됩니다. 보고 쿼리는 모델에 관해 최적의 집계를 유지하기 위해 분석되고 조정되므로, 학습 알고리즘은 System 집계만 보고 쿼리로서 만들고 삭제합니다. 사용자 정의 집계와 자동 집계는 모두 새로 고침을 사용하여 새로 고침됩니다. 자동 집계에 의해 생성되고 시스템 생성 집계로 표시된 집계만 자동 집계 처리에 포함됩니다.
쿼리 캐싱과 자동 집계
Power BI Premium은 쿼리 결과의 유지 관리를 위해 Power BI Premium/Embedded의 쿼리 캐싱도 지원합니다. 쿼리 캐싱은 자동 집계와 다른 기능입니다. 쿼리 캐싱에서는 Power BI Premium이 로컬 캐싱 서비스를 사용하여 캐싱을 구현하는 반면 자동 집계는 모델 수준에서 구현됩니다. 쿼리 캐싱에서는 서비스가 첫 번째 보고서 페이지 로드에 관해서만 쿼리를 캐싱하므로 사용자가 보고서를 사용할 때 쿼리 성능이 개선되지 않습니다. 반면에 자동 집계는 집계된 쿼리 결과를 미리 캐싱함으로써 사용자가 보고서를 사용할 때 생성된 쿼리를 포함하여 대부분의 보고서 쿼리를 최적화합니다. 하나의 모델에 관해 쿼리 캐싱과 자동 집계를 모두 사용하도록 설정하는 것이 가능하긴 하나, 이렇게 해야 할 필요가 없는 경우가 많습니다.
Azure Log Analytics를 사용하여 모니터링
Azure LA(Log Analytics)는 Power BI가 활동 로그를 저장하는 데 사용할 수 있는 Azure Monitor의 서비스입니다. Azure Monitor 제품군을 사용하면 Azure 및 온-프레미스 환경에서 원격 분석 데이터를 수집, 분석 및 사용할 수 있습니다. Azure Monitor는 장기 스토리지, 임시 쿼리 인터페이스, 그리고 데이터 내보내기와 다른 시스템과의 통합을 지원하는 API 액세스를 제공합니다. 자세한 내용은 Power BI에서 Azure Log Analytics 사용을 참조하세요.
Power BI용 Azure Log Analytics 구성에서 설명하는 것처럼 Power BI가 Azure LA 계정을 사용하여 구성된 경우 자동 집계의 성공률을 분석할 수 있습니다. 가장 중요하게는, 보고서 쿼리가 메모리 내 캐시에 의해 답변되는지 확인할 수 있습니다.
이 기능을 사용하려면 이 Power BI 블로그 게시물에서 설명하는 것처럼 PBIT 템플릿을 다운로드하여 Log Analytics 계정에 연결합니다. 보고서에서는 요약 보기, DAX 쿼리 수준 보기, SQL 쿼리 수준 보기, 이렇게 세 가지 수준에서 데이터를 볼 수 있습니다.
다음 이미지는 모든 쿼리에 대한 요약 페이지를 보여 줍니다. 표시된 차트는 집계로 충족된 총 쿼리의 비율 대비 데이터 원본을 사용해야 했던 쿼리의 비율을 보여 줍니다.
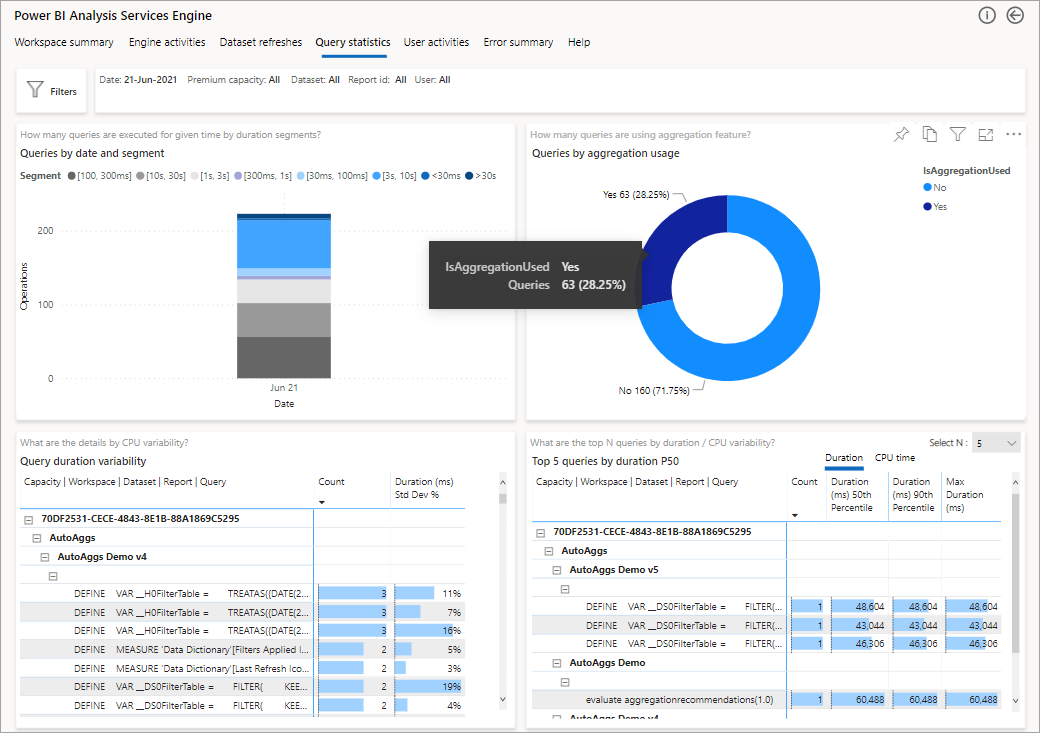
다음으로 자세히 살펴볼 단계는 DAX 쿼리 수준에서 집계가 사용되는 방식입니다. 목록(왼쪽 아래)에서 DAX 쿼리를 마우스 오른쪽 단추로 클릭하고 >드릴스루>쿼리 기록을 클릭합니다.
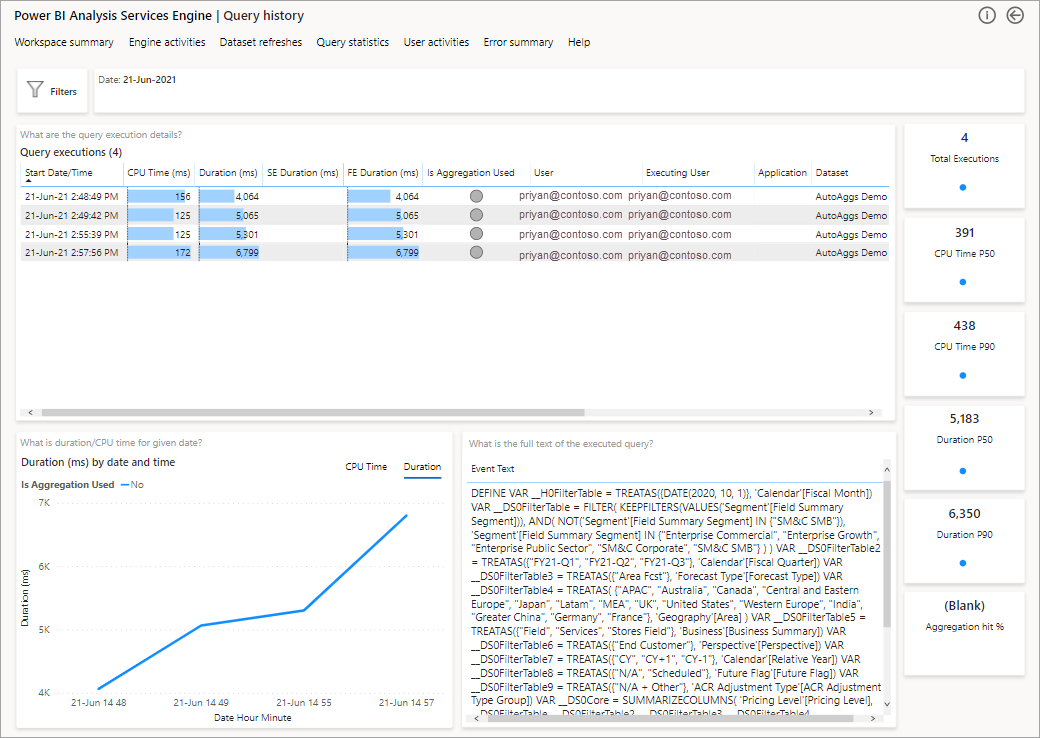
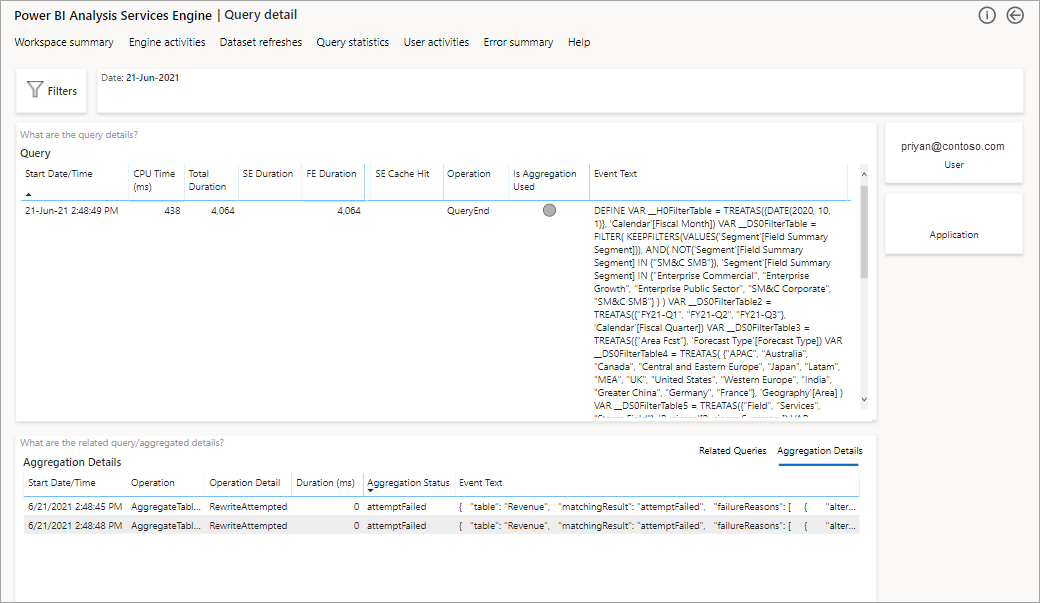
이렇게 하면 모든 관련 쿼리 목록이 표시됩니다. 다음 수준으로 드릴스루하여 더 많은 집계 세부 정보를 표시합니다.
애플리케이션 수명 주기 관리
개발 스테이지에서 테스트 스테이지까지, 그리고 테스트 스테이지에서 프로덕션 스테이지까지, 자동 집계를 사용하도록 설정된 모델에는 ALM 솔루션을 사용하기 위한 특수 요구 사항이 있습니다.
배포 파이프라인
배포 파이프라인을 사용하면 Power BI가 현재 스테이지에서 대상 스테이지로 모델과 모델 구성을 복사할 수 있습니다. 그러나 설정은 현재 스테이지에서 다음 스테이지로 전송되지 않으므로 대상 스테이지에서 자동 집계를 재설정해야 합니다. 배포 파이프라인 REST API를 사용하여 프로그래밍 방식으로 콘텐츠를 배포할 수도 있습니다. 이 프로세스에 관해 자세히 알아보려면 API 및 DevOps를 사용하여 배포 파이프라인 자동화를 참조하세요.
사용자 지정 ALM 솔루션
XMLA 엔드포인트를 기반으로 하는 사용자 지정 ALM 솔루션을 사용하는 경우, 솔루션이 모델 메타데이터의 일환으로 시스템 생성 집계 테이블과 사용자 생성 집계 테이블을 복사할 수 있다는 사실을 기억하세요. 단, 각 배포 단계가 완료된 후에 매번 대상 스테이지에서 수동으로 자동 집계를 사용하도록 설정해야 합니다. 기존 모델을 덮어쓰는 경우 Power BI가 구성을 유지합니다.
참고 항목
Power BI Desktop(.pbix) 파일의 일부로 모델을 업로드하거나 다시 게시하는 경우, Power BI가 기존 모델을 대상 작업 영역의 메타데이터 및 데이터로 대체하므로 시스템 생성 집계 테이블이 손실됩니다.
모델 변경
XMLA 엔드포인트를 통해 자동 집계를 사용하도록 설정한 모델을 변경(테이블 추가 또는 제거 등)한 후 Power BI는 유지할 수 있는 기존 집계를 유지하고 더 이상 필요하지 않거나 관련 없는 집계를 제거합니다. 다음번 학습 단계가 트리거될 때까지 쿼리 성능이 영향을 받을 수 있습니다.
메타데이터 요소
자동 집계를 사용하도록 설정된 모델은 고유한 시스템 생성 집계 테이블을 포함합니다. 집계 테이블은 보고 도구에서 사용자에게 표시되지 않습니다. Analysis Services 클라이언트 라이브러리 버전 19.22.5 이상의 도구를 사용하여 XMLA 엔드포인트를 통해 볼 수 있습니다. 자동 집계를 사용하도록 설정된 모델을 사용할 때는 데이터 모델링 및 관리 도구를 최신 버전의 클라이언트 라이브러리로 업그레이드하세요. SSMS(SQL Server Management Studio)는 SSMS 버전 18.9.2 이상으로 업그레이드하세요. 이전 버전의 SSMS는 테이블을 열거하거나 모델을 스크립팅할 수 없습니다.
자동 집계 테이블은 Analysis Services 클라이언트 라이브러리 버전 19.22.5 이상에서 TOM(Tabular Object Model)에 새로 도입된 SystemManaged 테이블 속성으로 식별됩니다. 다음 코드 조각은 집계 테이블의 경우 true로, 일반 테이블의 경우 false로 설정된 SystemManaged 속성을 보여줍니다.
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
이 코드 조각을 실행하면 모델에 현재 포함된 자동 집계 테이블이 콘솔에 출력됩니다.
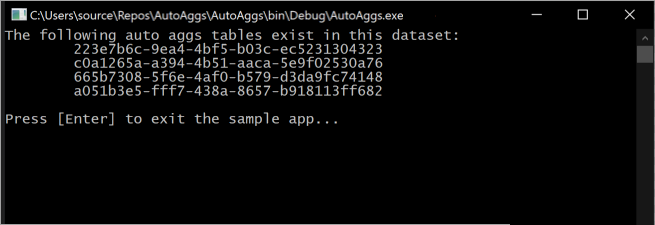
학습 작업이 메모리 내 집계 캐시에 포함할 최적의 집계를 알아냄에 따라 집계 테이블은 지속적으로 변경됩니다.
Important
Power BI는 자동 집계 시스템 생성 테이블 개체를 완전히 관리합니다. 이러한 테이블을 직접 삭제하거나 수정하지 마세요. 이렇게 하면 성능이 저하될 수 있습니다.
Power BI는 모델 외부에서 모델 구성을 유지 관리합니다. 모델에 시스템 관리 집계 테이블이 있다고 해서 모델이 자동 집계 학습을 사용하도록 설정되었음을 의미하는 것은 아닙니다. 즉, 자동 집계를 사용하도록 설정된 모델에 관해 전체 모델 정의를 스크립팅하고 모델의 새 복사본(다른 이름/작업 영역/용량을 사용하여)을 만드는 경우, 새 모델은 자동 집계 학습에 사용할 수 없습니다. 따라서 모델 설정에서 새 모델에 관해 자동 집계 학습을 사용하도록 설정해야 합니다.
고려 사항 및 제한 사항
자동 집계를 사용할 때는 다음에 유의하세요.
- 집계는 동적 M 쿼리 매개 변수를 지원하지 않습니다.
- 초기 학습 단계에서 생성된 SQL 쿼리는 데이터 웨어하우스에 상당한 부하를 발생할 수 있습니다. 학습이 계속 완료되지 않고 데이터 웨어하우스 쪽에서 쿼리 시간 초과가 확인되는 경우 학습 수요를 충족하도록 데이터 웨어하우스를 일시적으로 스케일 업하는 것이 좋습니다.
- 메모리 내 집계 캐시에 저장된 집계는 데이터 원본에 있는 가장 최근 데이터를 기반으로 계산되지 않을 수 있습니다. 순수 DirectQuery와 달리, 그리고 일반 가져오기 테이블과 비슷하게, 데이터 원본에서 이루어지는 업데이트와 메모리 내 집계 캐시에 저장된 집계 데이터 사이에는 대기 시간이 있습니다. 대기 시간은 항상 어느 정도 존재하긴 하나, 효과적인 새로 고침 일정을 통해 완화할 수 있습니다.
- 성능을 추가로 최적화하려면 모든 차원 테이블을 이중 모드로 설정하고 팩트 테이블은 DirectQuery 모드로 유지합니다.
- Power BI Pro, Azure Analysis Services 또는 SQL Server Analysis Services에서는 자동 집계를 사용할 수 없습니다.
- Power BI는 자동 집계를 사용하도록 설정된 모델의 다운로드를 지원하지 않습니다. Power BI Desktop(.pbix) 파일을 Power BI로 업로드하거나 게시한 후에 자동 집계를 사용하도록 설정한 후에는 더 이상 PBIX 파일을 다운로드할 수 없습니다. PBIX 파일의 복사본을 로컬에 보관해 두세요.
- Azure Synapse Analytics에서 외부 테이블을 사용한 자동 집계는 지원되지 않습니다.
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tablesSQL 쿼리를 사용하여 Synapse에서 외부 테이블을 열거할 수 있습니다. - 자동 집계는 향상된 메타데이터를 사용하는 모델에서만 사용할 수 있습니다. 오래된 모델에 관해 자동 집계를 사용하도록 설정하려면 먼저 모델을 향상된 메타데이터로 업그레이드하세요. 자세한 내용은 향상된 모델 메타데이터 사용을 참조하세요.
- DirectQuery 데이터 원본이 Single Sign-On을 사용하도록 구성되었고 동적 데이터 보기 또는 보안 컨트롤을 사용하여 사용자가 액세스할 수 있는 데이터를 제한하는 경우 자동 집계를 사용하도록 설정하지 않습니다. 자동 집계는 이러한 데이터 원본 수준 제어를 인식하지 못하므로 사용자별로 올바른 데이터가 제공되도록 하는 것이 가능하지 않습니다. 학습은 Single Sign-On에 대해 구성된 데이터 원본을 감지하고 이 데이터 원본을 사용하는 테이블을 건너뛰었다는 경고를 새로 고침 기록에 기록합니다. 가능하면 이러한 데이터 원본에 대해 SSO를 사용하지 않도록 설정하여 자동 집계가 제공할 수 있는 최적화된 쿼리 성능을 최대한 활용합니다.
- 모델에 불필요한 처리 오버헤드를 방지하기 위해 하이브리드 테이블만 포함된 경우 자동 집계를 사용하도록 설정하지 마세요. 하이브리드 테이블은 가져오기 파티션과 DirectQuery 파티션을 모두 사용합니다. 일반적인 시나리오는 DirectQuery 파티션이 마지막 데이터 새로 고침 후에 발생한 데이터 원본에서 트랜잭션을 가져오는 실시간 데이터를 사용한 증분 새로 고침입니다. 그러나 Power BI는 새로 고침 중에 집계를 가져옵니다. 자동 집계에는 마지막 데이터 새로 고침 후에 발생한 트랜잭션이 포함될 수 없습니다. 학습은 새로 고침 기록에 하이브리드 테이블을 검색하고 건너뛰었다는 경고를 기록합니다.
- 계산 열은 자동 집계에서 고려되지 않습니다. DirectQuery 모드에서 계산 열을 사용하는 경우(예:
COMBINEVALUESDAX 함수를 사용하여 두 개의 DirectQuery 테이블의 여러 열을 기반으로 관계를 만드는 경우), 보고서 쿼리가 메모리 내 집계 캐시에 전달되지 않습니다. - 자동 집계는 Power BI 서비스에서만 사용할 수 있습니다. Power BI Desktop은 시스템 생성 집계 테이블을 만들지 않습니다.
- 자동 집계를 사용하도록 설정된 모델의 메타데이터를 수정하는 경우, 다음번 학습 프로세스가 트리거되기 전까지 쿼리 성능이 저하될 수 있습니다. 가장 좋은 방법은 자동 집계를 삭제하고 변경 사항을 적용한 후에 다시 학습을 진행하는 것입니다.
- 자동 집계를 사용하지 않도록 설정했고 모델을 정리하는 것이 아닌 이상 시스템 생성 집계 테이블을 수정하거나 삭제하지 않습니다. 이러한 개체는 시스템이 관리합니다.
커뮤니티
Power BI는 MVP, BI 전문가 및 피어가 토론 그룹, 비디오, 블로그 등에서 전문 지식을 공유하는 커뮤니티가 활성화되어 있습니다. 자동 집계에 관해 자세히 알아보려면 다음과 같은 다른 리소스를 확인하세요.