Power BI Desktop의 데이터 형식
이 문서에서는 Power BI Desktop 및 DAX(데이터 분석 식)가 지원하는 데이터 형식에 대해 설명합니다.
Power BI는 데이터를 로드할 때 원본 열의 데이터 형식을 보다 효율적인 스토리지, 계산 및 데이터 시각화를 지원하는 데이터 형식으로 변환하려고 합니다. 예를 들어 Excel에서 가져오는 값 열에 소수 값이 없는 경우 Power BI Desktop은 데이터 열을 정수 데이터 형식으로 변환합니다. 이는 정수를 저장하는 데 더 적합합니다.
일부 DAX 함수에는 특별한 데이터 형식 요구 사항이 있기 때문에 이 개념이 중요합니다. 대부분의 경우 DAX 데이터 형식을 암시적으로 변환하지만 경우에 따라 변환되지 않습니다. 예를 들어 DAX 함수에
열의 데이터 형식 확인 및 지정
Power BI Desktop에서 파워 쿼리 편집기, 테이블 보기 또는 보고서 보기에서 열의 데이터 형식을 확인하고 지정할 수 있습니다.
파워 쿼리 편집기에서 열을 선택하고, 리본 메뉴의 변환 그룹에서 데이터 유형을 선택합니다.
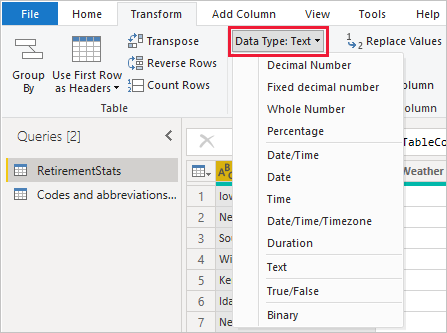
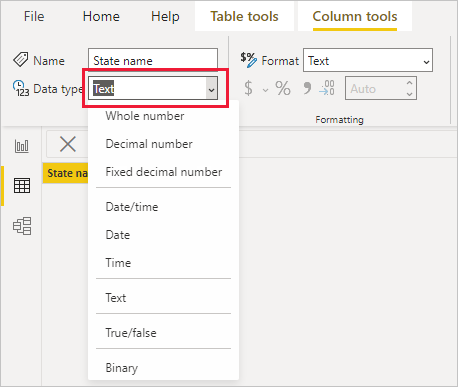
테이블 보기 또는 보고서 보기에서 열을 선택한 다음 리본 메뉴의 열 도구 탭에서 데이터 형식 옆의 드롭다운 화살표를 선택합니다.
파워 쿼리 편집기에서 데이터 형식 드롭다운 선택 영역에는 테이블 보기 또는 보고서 보기에 없는 두 가지 데이터 형식이 있습니다. 날짜/시간/표준 시간대 및 기간. 이러한 데이터 형식의 열을 Power BI 모델에 로드하면 날짜/시간/표준 시간대 열이 날짜/시간 데이터 형식으로 변환되고 기간 열이 10진수 데이터 형식으로 변환됩니다.
이진 데이터 형식은 파워 쿼리 편집기 외부에서 지원되지 않습니다. 파워 쿼리 편집기에서 Power BI 모델에 로드하기 전에 이진 파일을 다른 데이터 형식으로 변환하는 경우 이진 파일을 로드할 때 Binary 데이터 형식을 사용할 수 있습니다. 이진 선택은 레거시 이유로 테이블 보기 및 보고서 보기 메뉴에 있지만, 이진 열을 Power BI 모델에 로드하려고 하면 오류가 발생할 가능성이 있습니다.
숫자 형식
Power BI Desktop은 세 가지 숫자 유형인 10진수, 고정 10진수및 정수지원합니다.
TOM(테이블 형식 개체 모델) 열 DataType 속성을 사용하여 숫자 형식에 대한 DataType 열거형을 지정할 수 있습니다. Power BI에서 개체를 프로그래밍 방식으로 수정하는 방법에 대한 자세한 내용은 테이블 형식 개체 모델을 사용하여 Power BI 의미 체계 모델을 프로그래밍하십시오.
10진수
10진수 가장 일반적인 숫자 형식이며 소수 값과 정수를 사용하여 숫자를 처리할 수 있습니다.
10진수 형식이 나타낼 수 있는 가장 높은 정밀도는 15자리입니다. 소수 구분 기호는 숫자의 아무 곳이나 발생할 수 있습니다. 이 형식은 Excel에서 숫자를 저장하는 방법에 해당하며 TOM은 이 형식을 DataType.Double 열거형으로 지정합니다.
고정 10진수
고정 10진수 데이터 형식에는 소수 구분 기호의 고정 위치가 있습니다. 10진수 구분 기호는 항상 오른쪽에 4자리를 가지며 19자리의 중요도를 허용합니다. 고정 10진수 나타낼 수 있는 가장 큰 값은 양수 또는 음수 922,337,203,685,477.5807.
고정 10진수 형식은 반올림 시 오류가 발생할 수 있는 경우에 유용합니다. 소수 자릿수 값이 작은 숫자는 때때로 누적되어 숫자가 약간 부정확해질 수 있습니다. 고정 10진수 형식을 사용하면 소수 구분 기호 오른쪽의 네 자리 숫자 이후의 값을 잘라내어 이러한 종류의 오류를 방지할 수 있습니다.
이 데이터 형식은 SQL Server의 10진수(19,4)또는 Excel의 Analysis Services 및 파워 피벗의 Currency 데이터 형식에 해당합니다. TOM은 이 형식을 DataType.Decimal 열거형으로 지정합니다.
정수
정수은 64비트(8바이트) 정수 값을 나타냅니다. 정수형이기 때문에 정수는 소수점 오른쪽에 자릿수가 없습니다. 이 형식은 -9,223,372,036,854,775,807(-2^63+1사이의 양수 또는 음수 정수 19자리를 허용합니다. ) 및 9,223,372,036,854,775,806(2^63-2) 숫자 데이터 형식의 가능한 가장 큰 수를 나타낼 수 있습니다.
고정 소수점 형식과 마찬가지로 정수 형식은 반올림을 제어해야 할 때 유용할 수 있습니다. TOM은 정수 데이터 형식을 DataType.Int64 열거형으로 나타냅니다.
메모
Power BI Desktop 데이터 모델은 64비트 정수 값을 지원하지만 JavaScript 제한으로 인해 Power BI 시각적 개체가 안전하게 표현할 수 있는 가장 많은 수의 Power BI 시각적 개체는 9,007,199,254,740,991(2^53-1)입니다. 데이터 모델에 숫자가 더 큰 값이 있는 경우, 시각적 개체에 추가하기 전에 계산을 통해 크기를 줄일 수 있습니다.
숫자 형식 계산의 정확도
소수점 데이터 형식의 열 값은 부동 소수점 숫자의 IEEE 754 표준에 따라 대략적인 데이터 형식으로 저장됩니다. 근사 데이터 형식에는 정확한 숫자 값을 저장하는 대신 매우 가깝거나 둥근 근사치를 저장할 수 있으므로 내재된 정밀도 제한이 있습니다.
부동 소수점 값이 부동 소수점 자릿수를 안정적으로 정량화할 수 없는 경우 정밀도 손실 또는 부정확성이 발생할 수 있습니다. 일부 보고 시나리오에서는 부정확성이 예기치 않거나 부정확한 계산 결과로 나타날 수 있습니다.
10진수 데이터 형식 값 간의 같음 관련 비교 계산은 잠재적으로 예기치 않은 결과를 반환할 수 있습니다. 비교 연산자에는 =과 같음, >보다 큼, <미만, >=보다 크거나 같음 및 <=보다 작거나 같음이 포함됩니다.
이 문제는 DAX 식에서 RANKX 함수 사용하여 결과를 두 번 계산하여 약간 다른 숫자를 생성하는 경우 가장 명백합니다. 보고서 사용자는 두 숫자의 차이를 알 수 없지만 순위 결과는 눈에 띄게 부정확할 수 있습니다. 예기치 않은 결과를 방지하려면 열 데이터 형식을 10진수 에서 고정 10진수 또는 정수로 변경하거나, ROUND함수를 사용하여 강제 반올림을 수행할 수 있습니다. 소수점 오른쪽에 항상 네 자리가 있기 때문에 고정 소수점 숫자 데이터 형식은 더 높은 정밀도를 갖습니다.
10진수 데이터 형식의 열 값을 합산하는 계산은 예기치 않은 결과를 반환하는 경우가 거의 없습니다. 양수와 음수가 대량으로 포함된 열이 있을 때 이 결과가 나올 가능성이 가장 높습니다. 합계 결과는 열의 행에 걸쳐 값 분포의 영향을 받습니다.
필요한 계산에서 대부분의 음수를 합산하기 전에 양수의 대부분을 합산하면 처음에 큰 양의 부분 합계가 결과를 왜곡할 수 있습니다. 계산에서 균형 잡힌 양수와 음수를 추가하는 경우 쿼리는 더 정밀도를 유지하므로 더 정확한 결과를 반환합니다. 예기치 않은 결과를 방지하려면 열 데이터 형식을 10진수 에서 고정 소수점 또는 정수로 변경할 수 있습니다.
날짜/시간 형식
Power BI Desktop은 파워 쿼리 편집기에서 5가지 날짜/시간 데이터 형식을 지원합니다. 로드 중에 날짜/시간/표준 시간대 및 기간은 모두 Power BI Desktop 데이터 모델로 변환됩니다. 모델은 날짜/시간을 지원하며, 값을 날짜 또는 시간으로 별도로 서식을 지정할 수 있습니다.
날짜/시간 날짜 및 시간 값을 모두 나타냅니다. 기본 날짜/시간 값은 10진수 형식으로 저장되므로 두 형식 간에 변환할 수 있습니다. 시간 부분은 1/300초(3.33ms)의 전체 배수에 대한 분수로 저장됩니다. 데이터 형식은 1900년에서 9999년 사이의 날짜를 지원합니다.
날짜 시간 부분이 없는 날짜만 나타냅니다. 날짜는 소수 자릿수가 0인 날짜/시간 값으로 모델에 변환됩니다.
시간은 날짜 부분 없이 단순히 시간을 나타냅니다. 시간은 소수점 왼쪽에 숫자가 없는 날짜/시간 값으로 모델 내에서 변환됩니다.
날짜/시간/표준 시간대은 표준 시간대 오프셋이 있는 UTC 날짜/시간을 나타내며, 모델에 로드될 때 날짜/시간으로 변환됩니다. Power BI 모델은 사용자의 위치 또는 로캘에 따라 표준 시간대를 조정하지 않습니다. 미국의 모델에 로드된 09:00 값은 보고서를 열거나 볼 때마다 09:00으로 표시됩니다.
기간 길이를 나타내며 모델에 로드될 때 10진수 형식으로 변환됩니다. 10진수 타입으로, 날짜/시간 값에서 값을 올바르게 더하거나 뺄 수 있으며, 크기를 나타내는 시각화에서 쉽게 사용할 수 있습니다.
텍스트 형식
Text 데이터 형식은 텍스트 형식으로 표현되는 문자, 숫자 또는 날짜일 수 있는 유니코드 문자 데이터 문자열입니다. 문자열 길이의 실제 최대 제한은 Power BI의 기본 Power Query 엔진 및 텍스트 데이터 형식 길이에 대한 텍스트 제한에 따라 약 32,000개의 유니코드 문자입니다. 실제 최대 한도를 초과하는 텍스트 데이터 형식은 오류가 발생할 수 있습니다.
Power BI에서 텍스트 데이터를 저장하는 방식으로 인해 특정 상황에서 데이터가 다르게 표시될 수 있습니다. 다음 섹션에서는 파워 쿼리 편집기에서 데이터를 쿼리하고 Power BI에 로드하는 사이에 Text 데이터의 모양이 약간 변경될 수 있는 일반적인 상황을 설명합니다.
대/소문자 구분
Power BI에서 데이터를 저장하고 쿼리하는 엔진은 대/소문자를 구분하지 않으며, 서로 다른 대소문자를 동일한 값으로 처리합니다. "A"는 "a"와 같습니다. 그러나 파워 쿼리는 대/소문자를 구분하는데, 여기서 "A"는 "a"와 동일하지 않습니다. 대/소문자 구분의 차이는 Power BI에 로딩한 후 텍스트 데이터의 대소문자가 변경되는 상황으로 이어질 수 있습니다.
다음 예제에서는 주문 데이터를 보여줍니다. 각 주문에 대해 고유한 OrderNo 열과 주문 시 수동으로 입력한 수신자 이름을 보여 주는 수신자 열입니다. 파워 쿼리 편집기는 시스템에 입력한 주소 이름과 동일한
파워 쿼리에서 다양한 대문자가 있는 텍스트 데이터의 스크린샷 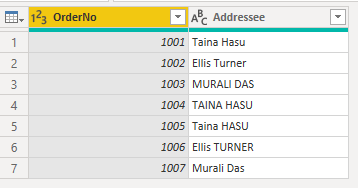
Power BI에서 데이터를 로드한 후 데이터 탭에서 중복된 이름의 대문자 표시가 원래 항목에서 대문자 변형 중 하나로 변경됩니다.
power BI에 로드한 후 대/소문자가 변경된 텍스트 데이터를 보여 주는 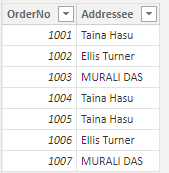
이 변경은 파워 쿼리 편집기가 대/소문자를 구분하므로 원본 시스템에 저장된 데이터를 정확하게 표시하기 때문에 발생합니다. Power BI에 데이터를 저장하는 엔진은 대/소문자를 구분하지 않으므로 문자의 소문자와 대문자 버전을 동일하게 처리합니다. Power BI 엔진에 로드된 파워 쿼리 데이터는 그에 따라 변경될 수 있습니다.
Power BI 엔진은 위쪽에서 시작하여 데이터를 로드할 때 각 행을 개별적으로 평가합니다. Addressee같은 각 텍스트 열에 대해 엔진은 데이터 압축을 통해 성능을 향상시키기 위해 고유한 값의 사전을 저장합니다. 엔진은 주소 열의 처음 세 값을 고유으로 보고 사전에 저장합니다. 그 후 엔진은 대/소문자를 구분하지 않으므로 이름을 동일하게 평가합니다.
엔진은 "Taina Hasu"라는 이름이 "TAINA HASU" 및 "Taina HASU"와 동일하다고 인식하여, 이 변형들을 저장하지 않고, 처음 저장한 변형만을 참조합니다. "MURALI DAS"라는 이름은 대문자로 나타납니다. 이는 엔진이 데이터를 위에서 아래로 로드할 때 처음으로 이름이 나타났기 때문입니다.
이 이미지는 평가 프로세스를 보여 줍니다.

앞의 예제에서 Power BI 엔진은 데이터의 첫 번째 행을 로드하고, 수신자 사전을 만들고, Taina Hasu를 추가했습니다. 또한 엔진은 로드하는 테이블의 Addressee 열에 해당 값에 대한 참조를 추가합니다. 대/소문자를 무시할 때 이러한 이름이 다른 이름과 동일하지 않으므로, 엔진은 두 번째 및 세 번째 행에 대해서도 동일한 작업을 수행합니다.
네 번째 행의 경우 엔진은 사전의 이름과 값을 비교하고 이름을 찾습니다. 엔진은 대/소문자를 구분하지 않으므로 "TAINA HASU"와 "Taina Hasu"는 동일합니다. 엔진은 사전에 새 이름을 추가하지 않고 기존 이름을 참조합니다. 나머지 행에도 동일한 프로세스가 발생합니다.
메모
Power BI에서 데이터를 저장하고 쿼리하는 엔진은 대/소문자를 구분하지 않으므로 대/소문자를 구분하는 원본을 사용하여 DirectQuery 모드에서 작업할 때 특별히 주의해야 합니다. Power BI는 원본이 중복 행을 제거했다고 가정합니다. Power BI는 대/소문자를 구분하지 않으므로 대/소문자만 다른 두 값을 중복 값으로 처리하지만 원본은 이러한 값으로 처리하지 않을 수 있습니다. 이러한 경우 최종 결과는 정의되지 않습니다.
이러한 상황을 방지하려면 대/소문자를 구분하는 데이터 원본에서 DirectQuery 모드를 사용하는 경우 원본 쿼리 또는 Power Query 편집기에서 대/소문자를 정규화하는 것이 좋습니다.
선행 및 후행 공백
Power BI 엔진은 텍스트 데이터를 따르는 후행 공백을 자동으로 트리밍하지만 데이터 앞에 오는 선행 공백은 제거하지 않습니다. 혼동을 방지하려면 선행 또는 후행 공백이 포함된 데이터를 사용하는 경우 Text.Trim 함수를 사용하여 텍스트의 시작 또는 끝에 있는 공백을 제거해야 합니다. 선행 공백을 제거하지 않으면 중복 값으로 인해 관계가 만들어지지 않거나 시각화에서 예기치 않은 결과를 반환할 수 있습니다.
다음 예제에서는 고객에 대한 데이터를 보여 줍니다. 고객의 이름이 포함된 이름 열과 각 항목에 대해 고유한 인덱스 열입니다. 이름은 명확성을 위해 따옴표 안에 나타납니다. 고객 이름은 네 번 반복되지만 매번 앞 공백과 후행 공백의 조합이 서로 다릅니다. 이러한 변형은 시간이 지남에 따라 수동 데이터 입력에서 발생할 수 있습니다.
| 행 | 선두 공백 | 후행 공간 | 이름 | 색인 | 텍스트 길이 |
|---|---|---|---|---|---|
| 1 | 아니요 | 아니요 | "딜런 윌리엄스" | 1 | 14 |
| 2 | 아니요 | 예 | "딜런 윌리엄스 " | 10 | 15 |
| 3 | 예 | 아니요 | "딜런 윌리엄스" | 20 | 15 |
| 4 | 예 | 예 | " 딜런 윌리엄스 " | 40 | 16 |
파워 쿼리 편집기에서 결과 데이터는 다음과 같이 표시됩니다.
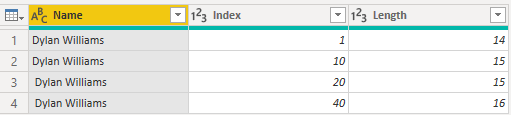
데이터를 로드한 후 Power BI의 테이블 탭으로 이동하면 이전과 동일한 수의 행이 있는 다음 이미지와 같은 테이블이 표시됩니다.
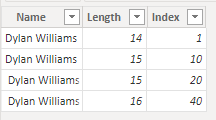
그러나 이 데이터를 기반으로 한 시각화는 두 개의 행만 반환합니다.

앞의 이미지에서 첫 번째 행은 인덱스 필드의 총 값 60을 가지므로, 시각적으로 첫 번째 행은 로드된 데이터의 마지막 두 행을 나타냅니다. 총 인덱스 값이 11 있는 두 번째 행은 처음 두 행을 나타냅니다. 시각화와 데이터 테이블 간의 행 수 차이는 엔진이 후행 공백은 자동으로 제거 또는 다듬지만, 선행 공백은 제거하지 않기 때문에 발생합니다. 따라서 엔진은 첫 번째 행과 두 번째 행, 세 번째 행과 네 번째 행을 동일하게 평가하고, 시각화는 이러한 결과를 반환합니다.
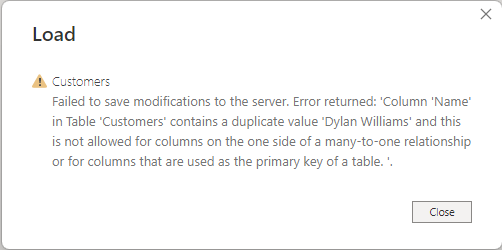
중복 값이 검색되므로 이 동작으로 인해 관계와 관련된 오류 메시지가 발생할 수도 있습니다. 예를 들어 관계의 구성에 따라 다음 이미지와 유사한 오류가 표시될 수 있습니다.
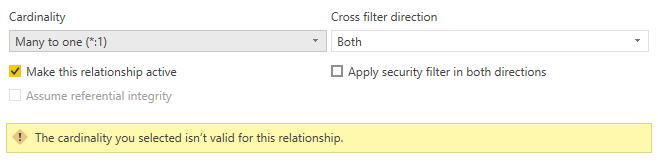
다른 경우에는 중복 값이 발견되어 다 대 일 또는 일대일 관계를 만들 수 없습니다.
선행 또는 후행 공백으로 인한 이러한 오류를 추적하여 파워 쿼리 편집기에서 공백을 제거할 수 있습니다. 이 작업은 Text.Trim또는 Format>Trim을 Transform아래에서 사용하는 방법으로 해결할 수 있습니다.
참/거짓 형식
True/false 데이터 형식은 True 또는 False부울 값입니다. 최상의 결과와 가장 일관된 결과를 위해 부울 true/false 정보가 포함된 열을 Power BI에 로드할 때 열의 형식을 True/False로 설정합니다.
Power BI는 특정 상황에서 데이터를 다르게 변환하고 표시합니다. 이 섹션에서는 부울 값을 변환하는 일반적인 사례와 Power BI에서 예기치 않은 결과를 생성하는 변환을 해결하는 방법을 설명합니다.
이 예제에서는 고객이 뉴스레터에 등록했는지 여부에 대한 데이터를 로드합니다. TRUE 값은 고객이 뉴스레터에 등록했음을 나타내고 FALSE 값은 고객이 등록하지 않았음을 나타냅니다.
그러나 Power BI 서비스에 보고서를 게시할 때 회보 등록 상태 열에는 TRUE 또는 FALSE값 대신 0 및 -1 표시됩니다. 다음 단계에서는 이 변환이 발생하는 방법과 이를 방지하는 방법을 설명합니다.
이 테이블에 대한 간소화된 쿼리는 다음 이미지에 표시됩니다.
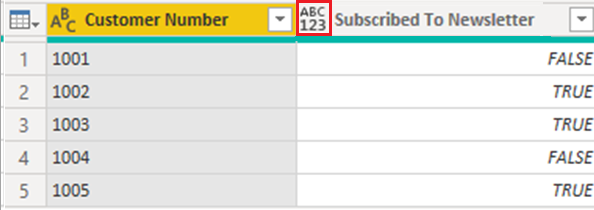
뉴스레터 구독 열의
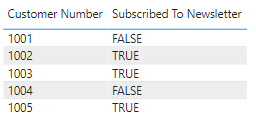
고객당 자세한 정보를 보여 주는 간단한 시각화를 추가하면 Power BI Desktop과 Power BI 서비스에 게시할 때 데이터가 예상대로 시각적 개체에 표시됩니다.
그러나 Power BI 서비스에서 의미 체계 모델을 새로 고치면, 시각적 개체의 회보 구독 열이 -1 및 0으로 표시되며, TRUE 또는 FALSE으로 표시되지 않습니다.
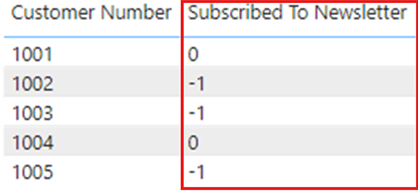
Power BI Desktop에서 보고서를 다시 게시하는 경우 회보 구독 열에 예상대로 TRUE 또는 FALSE 다시 표시되지만 Power BI 서비스에서 새로 고침이 발생하면 값이 다시 변경되어 -1 표시되고 0표시됩니다.
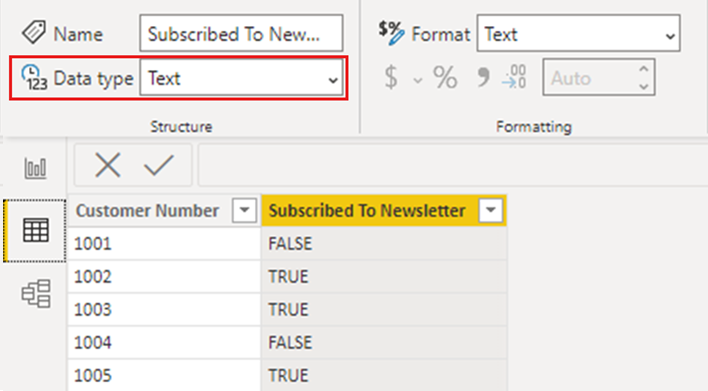
이 상황을 방지하는 해결 방법은 Power BI Desktop에서 모든 부울 열을 True/False 입력하고 보고서를 다시 게시하는 것입니다.
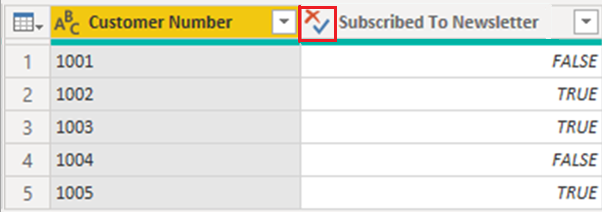
변경하면 시각화에 회보 구독 열의 값이 약간 다르게 표시됩니다. 표에 입력된 모든 대문자가 아닌 첫 번째 문자만 대문자로 표시됩니다. 이 변경은 열의 데이터 형식을 변경한 결과 중 하나입니다.
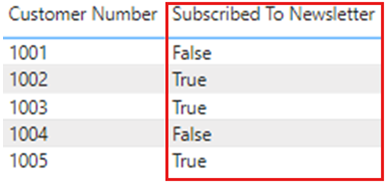
데이터 형식을 변경하고 Power BI 서비스에 다시 게시한 후 새로 고침이 발생하면, 보고서에 예상대로 참 또는 거짓값이 표시됩니다.
true/False 데이터 형식을 사용하는 true 또는 false 값을 보여 주는 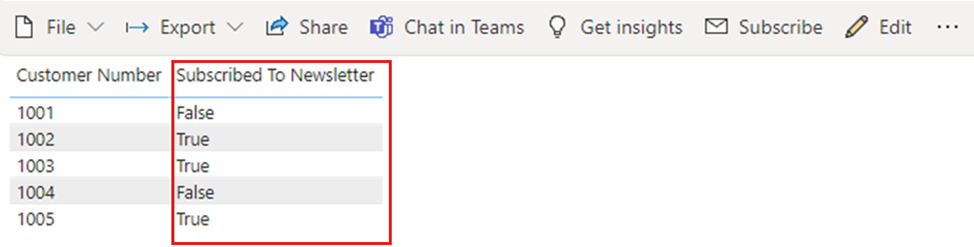
요약하자면 Power BI에서 부울 데이터로 작업하면서 열이 Power BI Desktop의 True/False 데이터 형식으로 설정되어 있는지 확인해야 합니다.
빈 형식
비어 있는 SQL null을 나타내고 대체하는 DAX 데이터 형식입니다. BLANK 함수를 사용하여 공백을 만들고 ISBLANK 논리 함수를 사용하여 공백을 테스트할 수 있습니다.
이진 형식
Binary 데이터 형식을 사용하여 모든 데이터를 이진 형식으로 나타낼 수 있습니다. 파워 쿼리 편집기에서 Power BI 모델에 로드하기 전에 이진 파일을 다른 데이터 형식으로 변환하는 경우 이 데이터 형식을 로드할 때 사용할 수 있습니다.
이진 열은 Power BI 데이터 모델에서 지원되지 않습니다. 이진 선택은 레거시 이유로 테이블 보기 및 보고서 보기 메뉴에 존재합니다. 그러나 Power BI 모델에 이진 열을 로드하려고 하면 오류가 발생할 수 있습니다.
메모
이진 열이 쿼리 단계의 출력에 있는 경우 게이트웨이를 통해 데이터를 새로 고치려고 하면 오류가 발생할 수 있습니다. 쿼리의 마지막 단계로 이진 열을 명시적으로 제거하는 것이 좋습니다.
테이블 형식
DAX는 집계 및 시간 인텔리전스 계산과 같은 많은 함수에서 Table 데이터 형식을 사용합니다. 일부 함수에는 테이블에 대한 참조가 필요합니다. 다른 함수는 다른 함수에 대한 입력으로 사용할 수 있는 테이블을 반환합니다.
테이블을 입력으로 필요로 하는 일부 함수에서는 테이블로 계산되는 식을 지정할 수 있습니다. 일부 함수에는 기본 테이블에 대한 참조가 필요합니다. 특정 함수의 요구 사항에 대한 자세한 내용은 DAX 함수 참조참조하세요.
암시적 및 명시적 데이터 형식 변환
각 DAX 함수에는 입력 및 출력으로 사용할 데이터 형식에 대한 특정 요구 사항이 있습니다. 예를 들어 일부 함수에는 일부 인수 및 다른 인수의 날짜에 대한 정수가 필요합니다. 다른 함수에는 텍스트 또는 테이블이 필요합니다.
인수로 지정한 열의 데이터가 함수에 필요한 데이터 형식과 호환되지 않으면 DAX에서 오류를 반환할 수 있습니다. 그러나 가능한 경우 DAX는 데이터를 필요한 데이터 형식으로 암시적으로 변환하려고 시도합니다.
예를 들어:
- 날짜를 문자열로 입력하는 경우 DAX는 문자열을 구문 분석하고 Windows 날짜 및 시간 형식 중 하나로 캐스팅하려고 합니다.
- 여러분은 TRUE + 1을 추가하고 결과로 2을 얻을 수 있습니다. 이는 DAX가 암시적으로 TRUE를 숫자 1로 변환하고, 1+1연산을 수행하기 때문입니다.
- 한 값이 텍스트("12")로 표시되고 다른 값이 숫자(12)로 표시된 두 열에 값을 추가하는 경우 DAX는 문자열을 숫자로 암시적으로 변환한 다음 숫자 결과에 대한 추가를 수행합니다. 식 = "22" + 22 는 44를 반환합니다.
- 두 숫자를 연결하려고 하면 DAX에서 문자열로 표시한 다음 연결합니다. 표현식 = 12 & 34는 "1234"을 반환합니다.
암시적 데이터 변환 테이블
연산자는 요청된 작업을 수행하기 전에 필요한 값을 캐스팅하여 DAX가 수행하는 변환 유형을 결정합니다. 다음 표에는 연산자가 나열되어 있으며, 교차하는 셀의 데이터 형식과 쌍을 이루는 각 데이터 형식에 대해 DAX가 수행하는 변환이 표시됩니다.
메모
이러한 테이블에는 Text 데이터 형식이 포함되지 않습니다. 숫자가 텍스트 형식으로 표현될 때 Power BI에서 숫자 형식을 확인하고 데이터를 숫자로 나타내려고 하는 경우도 있습니다.
더하기(+)
| 정수 | 통화 | 진짜 | 날짜/시간 | |
|---|---|---|---|---|
| 정수 | 정수 | 통화 | 진짜 | 날짜/시간 |
| 통화 | 통화 | 통화 | 진짜 | 날짜/시간 |
| REAL | 진짜 | 진짜 | 진짜 | 날짜/시간 |
| 날짜/시간 | 날짜/시간 | 날짜/시간 | 날짜/시간 | 날짜/시간 |
예를 들어 덧셈에서 통화 데이터와 함께 숫자형 실수가 사용되는 경우 DAX는 두 값을 모두 REAL로 변환하고 결과를 REAL로 출력합니다.
빼기(-)
다음 표에서 행 머리글은 피제수(왼쪽)이며 열 머리글은 뺄셈수(오른쪽)입니다.
| 정수 | 통화 | 진짜 | 날짜/시간 | |
|---|---|---|---|---|
| 정수 | 정수 | 통화 | 진짜 | 진짜 |
| 통화 | 통화 | 통화 | 진짜 | 진짜 |
| REAL | 진짜 | 진짜 | 진짜 | 진짜 |
| 날짜/시간 | 날짜/시간 | 날짜/시간 | 날짜/시간 | 날짜/시간 |
예를 들어 빼기 작업에서 다른 데이터 형식의 날짜를 사용하는 경우 DAX는 두 값을 모두 날짜로 변환하고 반환 값도 날짜입니다.
메모
데이터 모델은 단항 연산자(음수)를 지원하지만 이 연산자는 피연산자의 데이터 형식을 변경하지 않습니다.
곱하기(*)
| 정수 | 통화 | 레알 | 날짜/시간 | |
|---|---|---|---|---|
| 정수 | 정수 | 통화 | 진짜 | 정수 |
| 통화 | 통화 | 진짜 | 통화 | 통화 |
| REAL | 진짜 | 통화 | 레알 | 진짜 |
예를 들어 곱하기 연산이 정수를 실수와 결합하는 경우 DAX는 두 숫자를 모두 실수로 변환하고 반환 값도 REAL입니다.
나누기(/)
다음 표에서 행 머리글은 숫자이고 열 머리글은 분모입니다.
| 정수 | 통화 | 진짜 | 날짜/시간 | |
|---|---|---|---|---|
| 정수 | 진짜 | 통화 | 진짜 | 진짜 |
| 통화 | 통화 | 진짜 | 통화 | 레알 |
| REAL | 진짜 | 진짜 | 진짜 | 진짜 |
| 날짜/시간 | 진짜 | 진짜 | 진짜 | 진짜 |
예를 들어 나누기 연산이 정수를 통화 값과 결합하는 경우 DAX는 두 값을 모두 실수로 변환하고 결과는 실수입니다.
비교 연산자
비교 식에서 DAX는 문자열 값보다 큰 부울 값과 숫자 또는 날짜/시간 값보다 큰 문자열 값을 고려합니다. 숫자와 날짜/시간 값의 순위는 동일합니다.
DAX는 부울 또는 문자열 값에 대한 암시적 변환을 수행하지 않습니다. 공백 또는 빈 값은 비교되는 다른 값의 데이터 형식에 따라 0, ""또는 False로 변환됩니다.
다음과 같은 DAX 식이 이 동작을 보여 줍니다.
=IF(FALSE()>"true","Expression is true", "Expression is false")"표현식이 참"을 반환합니다.=IF("12">12,"Expression is true", "Expression is false")"표현식은 true"를 반환합니다.=IF("12"=12,"Expression is true", "Expression is false")"표현식이 false입니다"를 반환합니다.
DAX는 다음 표에 설명된 대로 숫자 또는 날짜/시간 형식에 대한 암시적 변환을 수행합니다.
| 비교 연산자 |
정수 | 통화 | 레알 | 날짜/시간 |
|---|---|---|---|---|
| 정수 | 정수 | 통화 | 진짜 | 진짜 |
| 통화 | 통화 | 통화 | 진짜 | 진짜 |
| REAL | 진짜 | 진짜 | 진짜 | 진짜 |
| 날짜/시간 | 진짜 | 진짜 | 진짜 | 날짜/시간 |
공백, 빈 문자열 및 0 값
DAX는 동일한 새 값 형식인 BLANK로 null, 빈 값, 빈 셀 또는 누락된 값을 나타냅니다. BLANK 함수를 사용하여 공백을 생성하거나 ISBLANK 함수를 사용하여 공백을 테스트할 수도 있습니다.
더하기 또는 연결과 같은 작업에서 공백을 처리하는 방법은 개별 함수에 따라 달라집니다. 다음 표에는 DAX 수식과 Microsoft Excel 수식에서 공백을 처리하는 방법의 차이점이 요약되어 있습니다.
| 표현 | DAX (독일 주가지수) | 엑셀 |
|---|---|---|
| 공백 + 공백 | 빈 | 0(0) |
| BLANK + 5 | 5 | 5 |
| BLANK * 5 | 빈 | 0(0) |
| 5/공백 | 무한대 | 오류 |
| 0/BLANK | NaN | 오류 |
| 빈 상태/빈 상태 | 빈칸 | 오류 |
| FALSE 또는 BLANK | 거짓 | 거짓 |
| FALSE 및 BLANK | 거짓 | 거짓 |
| TRUE 또는 BLANK | 진실 | 참 |
| 참 및 빈칸 | 거짓 | 참 |
| 빈칸 또는 빈칸 | 빈 | 오류 |
| 빈칸 및 빈칸 | 빈 | 오류 |
관련 콘텐츠
Power BI Desktop 및 데이터를 사용하여 모든 종류의 작업을 수행할 수 있습니다. Power BI 기능에 대한 자세한 내용은 다음 리소스를 참조하세요.
- Power BI Desktop이란?
- Power BI Desktop에서 쿼리 개요
- Power BI Desktop의 데이터 원본
- Power BI Desktop 셰이프 및 데이터 결합
- Power BI Desktop의 일반적인 쿼리 작업