다국어 문서에서 OCR 수행
광학 문자 인식(OCR)을 사용하면 이미지나 화면에서 텍스트를 찾아 추출할 수 있습니다.
대부분의 시나리오에서는 특정 언어로 된 텍스트를 처리해야 하지만 소스가 다국어인 경우가 있습니다.
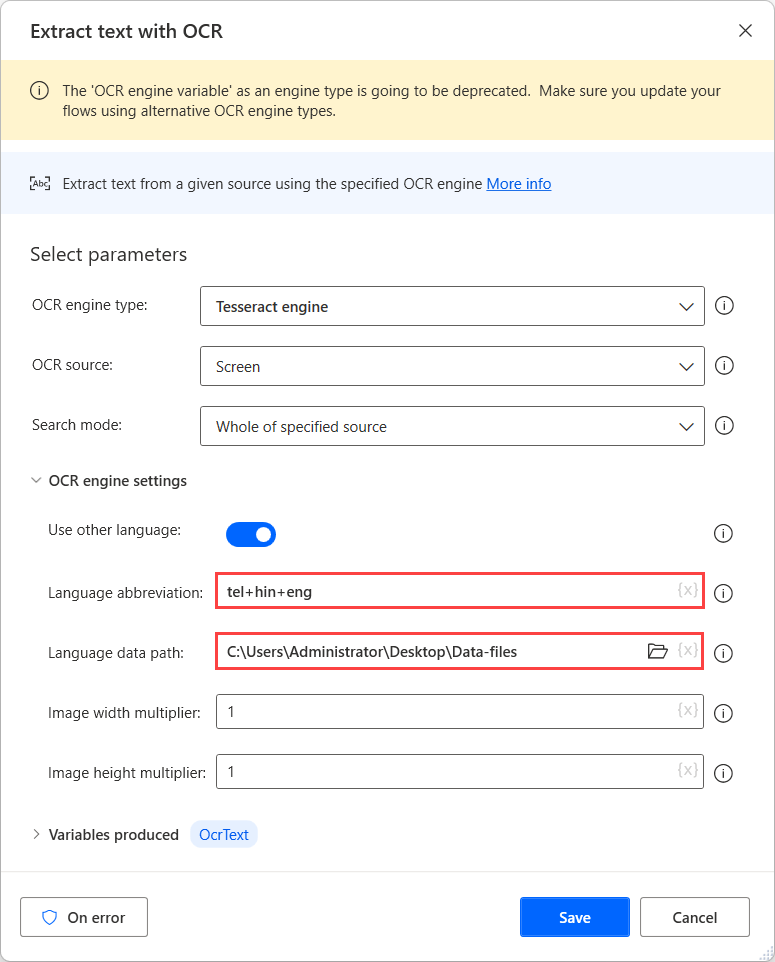
이러한 소스에서 OCR을 수행하려면 해당 OCR 작업에서 Tesseract 엔진을 사용하고 엔진 설정에서 다른 언어 사용 옵션을 활성화합니다.
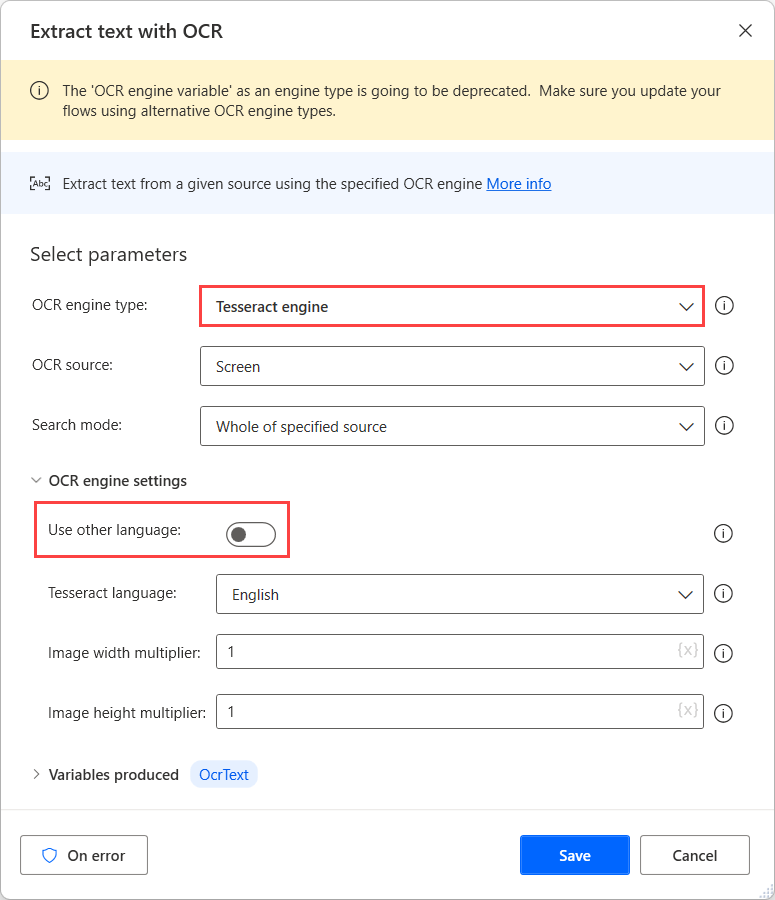
다른 언어 사용 옵션이 활성화되면 작업은 언어 약어 및 언어 데이터 경로 필드의 두 가지 추가 설정을 표시합니다.
언어 약어 필드는 OCR 중에 찾을 언어를 엔진에 나타냅니다. 언어 데이터 경로 필드에는 OCR 엔진 학습에 사용되는 언어 데이터 파일(.traineddata)이 포함됩니다.
필요한 언어에 대한 데이터 파일을 다운로드한 후 공통 폴더로 이동하여 동일한 경로에서 사용할 수 있도록 합니다.
다음으로 언어 데이터 경로 필드에서 생성된 폴더를 선택하고 언어 약어 필드에 해당 언어 코드를 입력합니다. 언어 코드를 구분하려면 더하기 문자(+)를 사용합니다.
노트
언어 데이터 파일의 소스에서 사용 가능한 모든 언어 코드를 찾을 수 있습니다. 다음 예에서 사용된 코드는 텔루구어, 힌디어 및 영어를 나타냅니다.