텍스트 작업
텍스트 작업을 사용하면 데스크톱 흐름에서 텍스트 값을 처리, 조작 및 변환할 수 있습니다.
텍스트 값 목록을 병합하고 단일 값을 만들려면 텍스트 결합 작업을 사용합니다. 작업을 수행하려면 목록과 구분 기호를 지정해야 합니다.
단일 텍스트 값을 목록으로 분할하려면 텍스트 분할 작업을 배포하고 텍스트 값과 구분 기호를 지정하여 목록 항목을 구분합니다.
텍스트의 하위 텍스트를 바꾸려면 텍스트 바꾸기 작업을 사용합니다. 다음 예에서는 Product Characteristics라는 텍스트를 Characteristics로 바꿉니다.
텍스트 구문 분석 작업으로 다른 텍스트 내의 텍스트 값을 검색합니다.
일부 텍스트 작업에서는 정규식을 사용할 수 있습니다. 예를 들어 텍스트 구문 분석 작업에서 정규 표현식임을 활성화하여 정규 표현식으로 지정된 텍스트를 검색할 수 있습니다. 정규식에 대한 자세한 내용을 보려면 정규식 언어 - 빠른 참조로 이동하세요.
또한 작업이 일치하는 모든 텍스트의 위치 목록을 반환하도록 하려면 첫 번째 항목만을 비활성화할 수 있습니다.
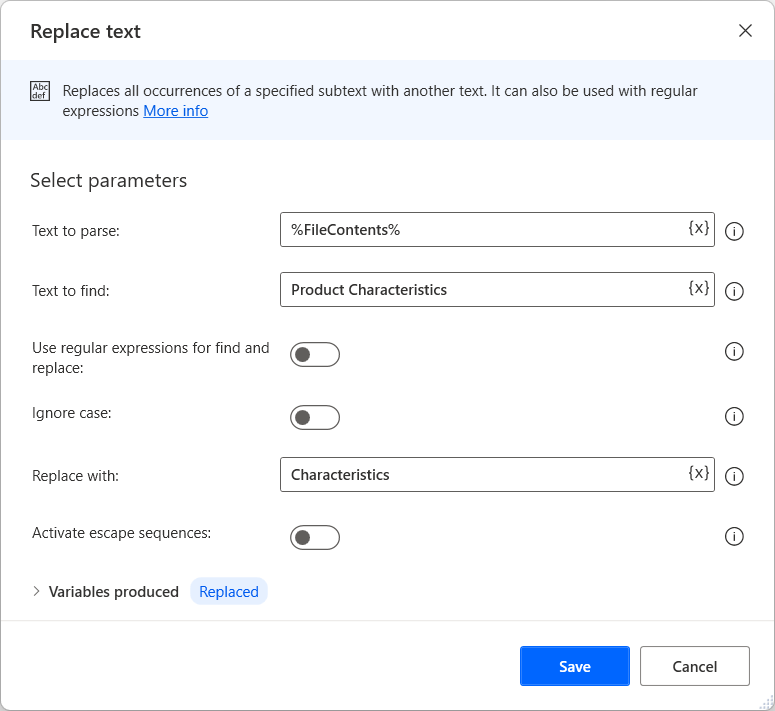
다음 예에서는 대문자로 시작하는 재고에서 감지된 항목의 모든 단어를 검색합니다. 일치라는 이름의 생성된 목록은 항목 및 재고 값을 저장합니다. 위치 목록은 값이 발견된 위치(1 및 18)를 저장합니다.
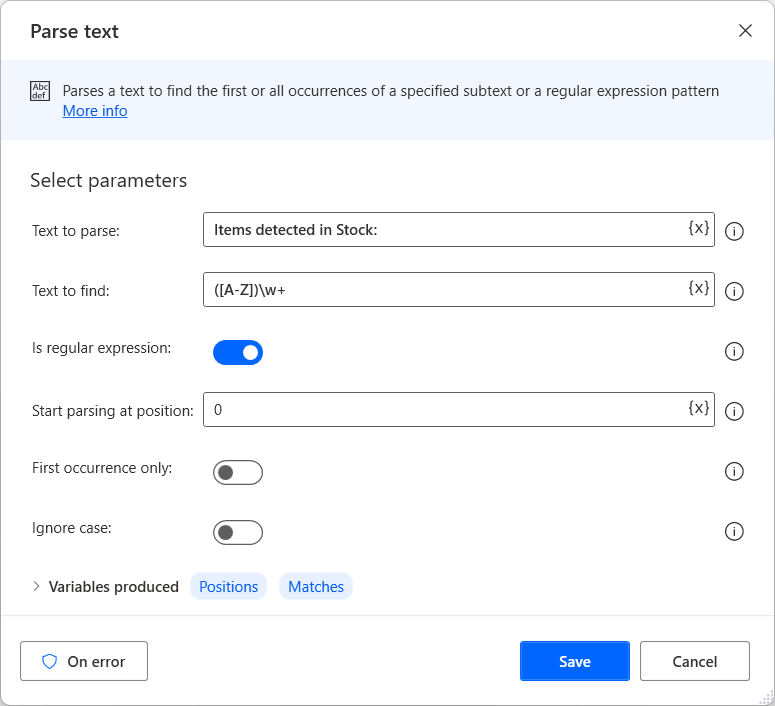
텍스트에서 검색하는 것 외에도 Power Automate을 사용하면 텍스트 자르기 작업을 사용하여 텍스트에서 텍스트 값을 자를 수 있습니다. 지정된 문자 또는 문자열 마커에서 처음 발생하는 플래그를 사용하여 자를 텍스트를 정의할 수 있습니다. 지정된 텍스트 플래그 앞, 뒤 또는 사이에서 값을 자를 수 있습니다.
CroppedText 변수는 자른 텍스트를 저장하는 반면 IsFlagFound 변수를 사용하여 액션이 설정된 플래그를 찾았는지 확인할 수 있습니다.
숫자가 숫자 값으로 저장되도록 하려면 텍스트를 숫자로 변환 동작을 사용합니다. 역변환을 수행하려면 숫자를 텍스트로 변환을 사용합니다.
마찬가지로 텍스트를 날짜/시간으로 변환 및 날짜/시간을 텍스트로 변환 작업을 사용하여 날짜 형식이 올바른지 확인할 수 있습니다.
텍스트에서 엔터티 인식 작업 사용
데스크톱 흐름을 사용하면 텍스트의 엔터티 인식 작업을 통해 숫자, 날짜 및 측정 단위와 같은 자연어 텍스트에서 다양한 엔터티를 추출할 수 있습니다.
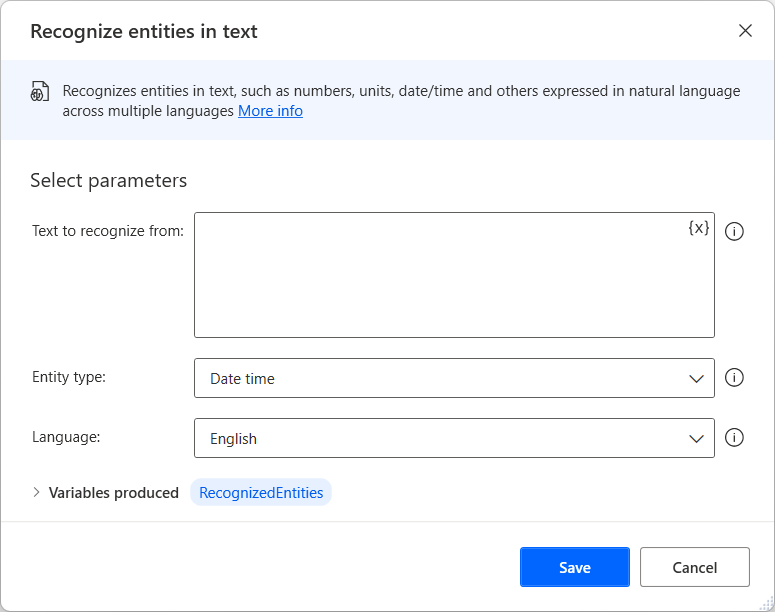
텍스트에서 엔터티 인식 작업은 텍스트 또는 텍스트를 포함하는 변수를 가져오고 결과를 포함하는 데이터 테이블을 반환합니다. 각 엔터티는 구조에 따라 다른 결과를 반환하지만 모든 데이터 테이블에는 입력 텍스트의 엔터티 부분을 저장하는 원본 텍스트 필드가 있습니다.
다음 테이블은 텍스트의 엔터티 인식 작업이 인식할 수 있는 엔터티의 다양한 예를 보여줍니다.
| 엔터티 | 입력 텍스트 | 반환된 값 |
|---|---|---|
| 날짜 시간 | 2019년 1월 4일에 돌아갑니다. | 값: 1/4/2019 12:00:00 AM 원본 텍스트: 04th Jan 2019 |
| 날짜 시간 | 오늘 저녁 7시에 회의 일정 잡기 | 값:9/30/2021 7:00:00 PM 원본 텍스트: tonight at 7pm |
| 차원 | 몸무게 200파운드 | 값: 200 단위: 파운드 원본 텍스트: 200 lbs |
| 차원 | 트위스터가 약 10마일 길이의 지역을 휩쓸었음 | 값: 10 단위: 마일 원본 텍스트: ten miles |
| Temperature | 외부 온도는 섭씨 40도입니다 | 값: 40 단위: C 원본 텍스트: 40 deg celsius |
| 통화 | 이자 소득은 분기에 27% 감소한 $254,000,000를 기록했습니다 | 값: 254000000 단위: 달러 원본 텍스트: $ 254 million |
| 숫자 범위 | 이 숫자는 20보다 크고 35보다 작거나 같음 | 시작: 20 끝: 35 원본 텍스트: larger than 20 and less or equal than 35 |
| 숫자 범위 | 5~10 | 시작: 5 끝: 10 원본 텍스트: From 5 to 10 |
| 숫자 범위 | 4.565보다 작음 | 시작: 0 끝: 4.565 원본 텍스트: Less than 4.565 |
| 숫자 | 다스 | 값: 12 원본 텍스트: A dozen |
| 숫자 | 3분의 2 | 값: 0.666666666666667 원본 텍스트: Two thirds |
| 서수 | 나는 처음 두 권의 책을 좋아한다. | 값: 1 원본 텍스트: first |
| 서수 | 11번째 | 값: 11 원본 텍스트: Eleventh |
| 백분율 | 100퍼센트 | 값: 100 원본 텍스트: 100 percent |
| 전화번호 | 전화: +1 209-555-0100 | 값: +1 209-555-0100 원본 텍스트: +1 209-555-0100 |
| felix@contoso.com | 값:felix@contoso.com 원본 텍스트:felix@contoso.com |
|
| IP 주소 | 내 PC IP 주소는 1.1.1.1입니다. | 값: 1.1.1.1 원본 텍스트: 1.1.1.1 |
| 멘션 | @앨리스 | 값:@Alice 원본 텍스트:@Alice |
| 해시태그 | #뉴스 | 값: #News 원본 텍스트: #News |
| URL | www.microsoft.com | 값:www.microsoft.com 원본 텍스트:www.microsoft.com |
| GUID | 123e4567-e89b-12d3-a456-426655440000 | 값: 123e4567-e89b-12d3-a456-426655440000 원본 텍스트: 123e4567-e89b-12d3-a456-426655440000 |
| 인용된 텍스트 | "값" 필드에 값을 입력합니다. | 값: "값" 원본 텍스트: "value" |
노트
텍스트의 엔터티 인식 작업은 14개의 다른 언어를 지원합니다. 그러나 일부 엔터티는 특정 언어에 대해 사용하지 못할 수 있습니다. 언어 제한에 대한 자세한 내용을 확인하려면 Microsoft Recognizers 텍스트 - 여러 문화권에서 지원되는 엔터티로 이동하세요.
텍스트에 줄 추가
텍스트 값에 텍스트 줄 바꿈을 추가합니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| Original text | 아니요 | 텍스트 값 | 원본 텍스트 | |
| Line to append | 네 | 텍스트 값 | 줄 바꿈으로 추가할 텍스트 |
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| Result | 텍스트 값 | 새 텍스트 |
예외
이 작업에는 예외가 포함되지 않습니다.
하위 텍스트 가져오기
텍스트 값에서 하위 텍스트를 검색합니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| Original text | 아니요 | 텍스트 값 | 텍스트의 섹션을 검색할 텍스트 | |
| Start index | 해당 없음 | 텍스트 시작, 문자 위치 | 문자 위치 | 텍스트 검색에 대해서 시작 포인트를 찾을 방법 지정 |
| Character position | 아니요 | 숫자 값 | 검색할 첫 번째 문자의 위치입니다. 이 값은 0부터 시작하는 인덱스이며 첫 번째 문자를 0부터 계산합니다. | |
| Length | 해당 없음 | 텍스트 끝, 문자 수 | Number of chars | 하위 텍스트가 텍스트 끝까지 계속되거나 문자의 특정 수만 포함할지 지정 |
| Number of chars | 아니요 | 숫자 값 | 검색할 문자 수 |
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| Subtext | 텍스트 값 | 검색된 하위 텍스트 |
예외
| 예외 | 설명 |
|---|---|
| 시작 색인 또는 길이가 범위를 넘었음 | 시작 색인 또는 길이가 범위를 넘었음을 나타냄 |
텍스트 자르기
주어진 텍스트에서 지정된 텍스트 플래그 이전, 이후 또는 사이에 발생하는 텍스트 값을 검색합니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| Original text | 아니요 | 텍스트 값 | 텍스트의 섹션을 검색할 텍스트 | |
| Mode | 사용 불가 | 지정된 플래그 앞의 텍스트 가져오기, 지정된 플래그 뒤의 텍스트 가져오기, 지정된 두 플래그 사이의 텍스트 가져오기 | 지정한 플래그 앞에 텍스트 가져오기 | 플래그 앞, 뒤 또는 사이에, 검색할지 여부를 지정합니다. |
| 시작 플래그 | 아니요 | 텍스트 값 | 검색된 텍스트는 이 플래그 뒤에 있습니다. 플래그는 모든 문자 또는 텍스트일 수 있습니다 | |
| 종료 플래그 | 아니요 | 텍스트 값 | 검색된 텍스트는 이 플래그 앞에 있습니다. 플래그는 모든 문자 또는 텍스트일 수 있습니다 | |
| Ignore case | 사용 불가 | 부울 값 | False | 대/소문자 구분 또는 대/소문자 구분 안 함 일치를 사용해 플래그를 찾을지 지정 |
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| CroppedText | 텍스트 값 | 새로운 잘린 텍스트 |
| IsFlagFound | 부울 값 | 플래그가 찾을 수 있는지를 나타냅니다 |
예외
이 작업에는 예외가 포함되지 않습니다.
텍스트 채우기
기존 텍스트의 왼쪽 또는 오른쪽에 문자를 추가하여 고정된 길이 텍스트를 만듭니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| Text to pad | 예 | 텍스트 값 | 늘일 텍스트 | |
| Pad | 해당 없음 | 왼쪽, 오른쪽 | 왼쪽 | 기존 텍스트의 왼쪽 또는 오른쪽에 문자를 추가할지 지정 |
| Text for padding | 예 | 텍스트 값 | 원본 텍스트를 늘이기 위해 문자 또는 텍스트가 추가됨 | |
| Total length | 예 | 숫자 값 | 10 | 마지막으로 채워진 텍스트의 총 문자 길이입니다. 최종 텍스트가 지정된 길이가 될 때까지 채울 텍스트가 반복하여 추가됩니다. |
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| PaddedText | 텍스트 값 | 채워진 새 텍스트 |
예외
이 작업에는 예외가 포함되지 않습니다.
텍스트 자르기
기존 텍스트의 시작 또는 끝에서 공백 문자의 모든 항목(예: 공백, 탭, 또는 줄 바꿈)을 삭제합니다.
텍스트 자르기 작업은 텍스트 값을 입력으로 받고 자르기 대상 매개 변수에 따라 텍스트 출력을 생성합니다. 자르기 대상 매개 변수에서 사용 가능한 옵션은 다음과 같습니다.
- 처음의 공백 문자
- 끝의 공백 문자
- 처음과 끝의 공백 문자
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| Text to trim | 예 | 텍스트 값 | 자를 텍스트 | |
| What to trim | 해당 없음 | 처음부터 공백 문자, 끝부터 공백 문자, 시작과 끝부터 공백 문자 | 처음과 끝의 공백 문자 | 공백 문자가 삭제될지 여부 지정 |
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| TrimmedText | 텍스트 값 | 자른 새 텍스트 |
예외
이 작업에는 예외가 포함되지 않습니다.
역방향 텍스트
텍스트 문자열에서 문자 순서를 뒤집습니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| 뒤집을 목록 | 아니요 | 텍스트 값 | 뒤집을 텍스트 |
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| ReversedText | 텍스트 값 | 반전된 새 텍스트 |
예외
이 작업에는 예외가 포함되지 않습니다.
텍스트 대/소문자 변경
텍스트의 대/소문자를 대문자, 소문자, 제목 대/소문자 또는 문장 대/소문자로 변경합니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| Text to convert | 예 | 텍스트 값 | 변환할 텍스트 | |
| Convert to | 해당 없음 | 대문자, 소문자, 타이틀 케이스, 센텐스 케이스 | 대문자 | 사용할 텍스트 대/소문자 스타일 지정 |
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| TextWithNewCase | 텍스트 값 | 새 변환된 텍스트 |
예외
이 작업에는 예외가 포함되지 않습니다.
텍스트를 숫자로 변환
숫자의 텍스트 표현을 숫자 값을 포함하는 변수로 변환합니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| Text to convert | 아니요 | 텍스트 값 | 숫자 값 변수로 변환할 숫자만 포함된 텍스트 변수입니다. 공백은 무시되지만 숫자가 아닌 텍스트는 예외를 발생시킵니다. |
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| TextAsNumber | 숫자 값 | 새 숫자 값 |
예외
| 예외 | 설명 |
|---|---|
| 제공된 텍스트 값이 유효한 숫자로 변환될 수 없음 | 제공된 텍스트 값이 유효한 숫자로 변환될 수 없음을 나타냄 |
숫자를 텍스트로 변환
지정된 형식을 이용해 숫자를 텍스트로 변환합니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| Number to convert | 아니요 | 숫자 값 | 텍스트로 변환할 숫자 값 | |
| Decimal places | 예 | 숫자 값 | 2 | 자르기 전에 포함될 소수 자릿수입니다. 이런 식으로 텍스트를 채우기 위해 끝에 0을 추가할 수도 있습니다. |
| Use thousands separator | 해당 없음 | 부울 값 | True | 천 단위 구분 기호로 구두점을 사용할지 여부 지정 |
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| FormattedNumber | 텍스트 값 | 텍스트로서의 서식이 지정된 숫자 |
예외
이 작업에는 예외가 포함되지 않습니다.
텍스트를 날짜/시간으로 변환
날짜 또는 시간 값의 텍스트 표현을 날짜/시간 값으로 변환합니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| Text to convert | 아니요 | 텍스트 값 | 날짜/시간 값으로 변환할 텍스트입니다. 이 텍스트는 인식할 수 있는 날짜/시간 값 형식이어야 합니다. | |
| Date is represented in custom format | 해당 없음 | 부울 값 | False | 변환할 텍스트가 날짜와 시간 표현을 비표준 또는 비식별 형식으로 포함할지 지정 |
| Custom format | 아니요 | 텍스트 값 | 날짜가 텍스트에 저장되는 형식입니다. 사용자 지정 형식은 예를 들어 날짜의 경우 yyyyMMdd, 시간의 경우 hhmmss로 표현할 수 있습니다. |
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| TextAsDateTime | 날짜/시간 | 날짜/시간 값 |
예외
| 예외 | 설명 |
|---|---|
| 제공된 텍스트 값이 유효한 날짜/시간으로 변환될 수 없음 | 제공된 텍스트 값이 유효한 날짜/시간으로 변환될 수 없음을 나타냄 |
날짜/시간을 텍스트로 변환
지정된 사용자 지정 형식을 이용해 날짜/시간 값을 텍스트로 변환합니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| Datetime to convert | 아니요 | 날짜/시간 | 텍스트로 변환할 날짜/시간 값 | |
| Format to use | 해당 없음 | 표준, 사용자 지정 | 표준 | 표준 날짜/시간 또는 사용자 지정 날짜/시간 사용 여부 지정 |
| Custom Format | 아니요 | 텍스트 값 | 날짜/시간 값을 표시할 사용자 지정 형식입니다. 날짜/시간은 날짜의 경우 MM/dd/yyyy, 시간의 경우 hh:mm:sstt로 표현할 수 있습니다 | |
| Standard format | 해당 없음 | 짧은 날짜, 긴 날짜, 짧은 시간, 긴 시간, 전체 날짜/시간(짧은 시간), 전체 날짜/시간(긴 시간), 일반 날짜/시간(짧은 시간), 일반 날짜/시간(긴 시간), 정렬 가능한 날짜/시간 | 간단한 날짜 | 작업이 날짜/시간 값을 표시하는 데 사용하는 표준 날짜/시간 형식 |
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| FormattedDateTime | 텍스트 값 | 텍스트 값으로 서식이 지정된 날짜/시간 |
예외
이 작업에는 예외가 포함되지 않습니다.
임의의 텍스트 만들기
임의의 문자로 구성된 지정된 길이의 텍스트를 생성합니다. 이 작업은 암호 생성에 유용할 수 있습니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| Use uppercase letters (A-Z) | 해당 없음 | 부울 값 | True | 생성된 텍스트에 대문자를 포함할지 여부 지정 |
| Use lowercase letters (a-z) | 해당 없음 | 부울 값 | True | 생성된 텍스트에 소문자를 포함할지 여부 지정 |
| Use digits (0-9) | 해당 없음 | 부울 값 | True | 생성된 텍스트에 숫자를 포함할지 여부 지정 |
| 기호 사용( , . <> ? ! + - _ # $ ^ ) | 사용 불가 | 부울 값 | 참 | 생성된 텍스트에 기호를 포함할지 여부 지정 |
| Minimum length | 예 | 숫자 값 | 6 | 임의 텍스트의 최소 길이입니다. 텍스트의 특정 길이의 경우 최소 및 최대 값을 이 숫자로 설정합니다 |
| Maximum length | 예 | 숫자 값 | 10 | 임의 텍스트의 최대 길이입니다. 텍스트의 특정 길이의 경우 최소 및 최대 값을 이 숫자로 설정합니다 |
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| RandomText | 텍스트 값 | 생성된 임의의 텍스트 |
예외
이 작업에는 예외가 포함되지 않습니다.
텍스트 참가
지정된 구분 기호로 항목을 구분하여 목록을 텍스트 값으로 변환합니다.
목록의 모든 내용을 단일 텍스트 값으로 결합하려면 텍스트 결합 작업을 사용하세요. 결합할 목록 지정 속성에서 사용할 각 목록을 지정하여 시작합니다. 목록 항목을 구분하는 구분 기호 속성 드롭다운 목록에서 해당 항목을 선택하여 결합된 텍스트에서 목록 항목을 구분하는 구분 기호를 선택할 수 있습니다.
- 없음은 목록의 모든 항목을 구분 기호로 구분하지 않고 결합하여 단일 결합 리터럴을 만듭니다.
- 표준을 사용하면 표준 구분 기호 속성 드롭다운 목록에서 해당 옵션을 선택하여 구분 기호를 공백, 탭 또는 새 줄로 설정할 수 있습니다. 시간 속성을 수정하여 각 목록 항목 사이에 구분 기호가 표시되는 횟수를 선택할 수도 있습니다.
- 사용자 지정을 사용하면 자신만의 구분 기호를 설정할 수 있습니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| Specify the list to join | 아니요 | 텍스트 값 목록 | 텍스트로 변환할 줄 | |
| Delimiter to separate list items | 해당 없음 | 없음, 표준, 사용자 지정 | 아니요 | 구분 기호 없이 또는 표준 구분 기호나 사용자 지정 구분 기호를 사용할지 지정 |
| Custom delimiter | 아니요 | 텍스트 값 | 구분 기호로 사용할 문자 | |
| Standard delimiter | 해당 없음 | 공백, 탭, 새 줄 | 스페이스 | 사용할 구분 기호 지정 |
| Times | 예 | 숫자 값 | 1 | 지정된 구분 기호를 몇 번 사용할지 지정 |
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| JoinedText | 텍스트 값 | 새 분리된 텍스트 |
예외
이 작업에는 예외가 포함되지 않습니다.
텍스트 나누기
지정된 구분 기호 또는 정규식으로 구분되는 텍스트의 하위 문자열을 포함하는 목록을 만듭니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| The text to split | 아니요 | 텍스트 값 | 나눌 텍스트 | |
| Delimiter type | 해당 없음 | 표준, 사용자 지정 | 표준 | 사용된 구분 기호가 표준인지 사용자 지정 형식인지 지정 |
| Custom delimiter | 아니요 | 텍스트 값 | 구분 기호로 사용된 문자 | |
| Standard delimiter | 해당 없음 | 공백, 탭, 새 줄 | 스페이스 | 사용된 구분 기호 |
| Times | 네 | 숫자 값 | 1 | 구분 기호가 사용되는 횟수 지정 |
| Is regular expression | 사용 불가 | 부울 값 | False | 구분 기호가 정규 식인지 여부를 지정합니다. 정규 식은 구분 기호에 대한 가능성 범위를 만듭니다. 예를 들어 '\d'는 구분 기호가 임의의 숫자일 수 있음을 의미합니다. |
노트
Power Automate의 정규식 엔진은 .NET입니다. 정규식에 대한 자세한 내용을 보려면 정규식 언어 - 빠른 참조로 이동하세요.
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| TextList | 텍스트 값 목록 | 새 목록 |
예외
| 예외 | 설명 |
|---|---|
| 제공된 정규식이 잘못됨 | 제공된 정규식이 잘못되었음을 나타냄 |
텍스트 구문 분석
지정된 하위 텍스트 또는 정규식 패턴의 첫 번째 또는 모든 항목을 찾기 위해 텍스트 구문을 분석합니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| Text to Parse | 아니요 | 텍스트 값 | 구문 분석할 텍스트 | |
| Text to Find | 아니요 | 텍스트 값 | 검색할 하위 텍스트 또는 정규식 | |
| Is regular expression | 해당 없음 | 부울 값 | False | 하위 텍스트가 정규 식인지 여부를 지정합니다. 예를 들어 \d는 하위 텍스트가 임의의 숫자일 수 있음을 의미합니다. |
| Start Parsing at Position | 아니요 | 숫자 값 | '찾을 텍스트'를 찾기 시작할 위치입니다. 첫 번째 위치는 0이므로 처음부터 시작하려면 0을 사용하십시오. | |
| First occurrence only | 해당 없음 | 부울 값 | True | 첫 번째 항목만 또는 '찾을 텍스트'의 모든 항목을 찾을지 여부 지정 |
| Ignore case | 해당 없음 | 부울 값 | False | 대/소문자 구분 또는 대/소문자 구분 안 함 일치를 사용해 지정된 텍스트를 찾을지 지정 |
노트
Power Automate의 정규식 엔진은 .NET입니다. 정규식에 대한 자세한 내용을 보려면 정규식 언어 - 빠른 참조로 이동하세요.
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| Position | 숫자 값 | '구문 분석할 텍스트'에서 '찾을 텍스트'의 위치입니다. 원본 텍스트에서 텍스트를 찾을 수 없는 경우 이 변수는 값 -1을 유지합니다. |
| Positions | 숫자 값 목록 | '구문 분석할 텍스트'에서 '찾을 텍스트'의 위치입니다. 원본 텍스트에서 텍스트를 찾을 수 없는 경우 이 변수는 값 -1을 유지합니다. |
| Match | 텍스트 값 | 주어진 정규식과 일치하는 결과 |
| Matches | 텍스트 값 목록 | 주어진 정규식과 일치하는 결과 |
예외
| 예외 | 설명 |
|---|---|
| 제공된 정규식이 잘못됨 | 제공된 정규식이 잘못되었음을 나타냄 |
텍스트 대체
지정된 하위 텍스트의 모든 항목을 다른 텍스트로 바꿉니다. 정규식과 함께 사용할 수도 있습니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| Text to parse | 아니요 | 텍스트 값 | 구문 분석할 텍스트 | |
| Text to find | 아니요 | 텍스트 값 | 검색할 하위 텍스트 또는 정규식 | |
| Use regular expressions for find and replace | 해당 없음 | 부울 값 | False | 하위 텍스트가 정규 식인지 여부를 지정합니다. 정규 식은 하위 텍스트에 대한 가능성 범위를 만듭니다. 예를 들어 '\d'는 하위 텍스트가 임의의 숫자일 수 있음을 의미합니다. |
| Ignore case | 해당 없음 | 부울 값 | False | 대/소문자 구분 또는 대/소문자 구분 안 함 일치를 사용해 대체할 하위 텍스트를 찾을지 지정 |
| Replace with | 아니요 | 텍스트 값 | 찾은 텍스트를 대체할 텍스트 또는 정규식 | |
| Activate escape sequences | 해당 없음 | 부울 값 | False | 특수 시퀀스 사용 여부를 지정합니다. 예를 들어 대체 텍스트의 '\t'은 탭으로 해석됩니다 |
노트
Power Automate의 정규식 엔진은 .NET입니다. 정규식에 대한 자세한 내용을 보려면 정규식 언어 - 빠른 참조로 이동하세요.
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| Replaced | 텍스트 값 | 업데이트된 새 텍스트 |
예외
이 작업에는 예외가 포함되지 않습니다.
정규식에 대한 텍스트 이스케이프
문자를 이스케이프 코드로 대체해 문자의 최소 집합(, *, +, ?, |, {, [, (,), ^, $,., #, 공백)을 이스케이프합니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| Text to escape | 아니요 | 텍스트 값 | 이스케이프할 텍스트 |
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| EscapedText | 텍스트 값 | 이스케이프된 텍스트 |
예외
이 작업에는 예외가 포함되지 않습니다.
텍스트의 엔터티 인식
여러 언어에서 숫자, 단위, 날짜/시간 및 기타 자연어 표현 등 텍스트의 엔터티를 인식합니다.
입력 매개 변수
| 인수 | 선택 항목 | 수락 | 기본값 | Description |
|---|---|---|---|---|
| 인식할 텍스트 | 아니요 | 텍스트 값 | 엔터티를 인식할 텍스트 | |
| 엔터티 유형 | 사용 불가 | 날짜 시간, 차원, 온도, 통화, 숫자 범위, 숫자, 서수, 백분율, 전화번호, 이메일, IP 주소, 멘션, 해시태그, URL, GUID, 인용문 | 날짜 시간 | 인식할 엔터티 유형(날짜/시간, 이메일, URL 등) |
| 언어 | 사용 불가 | 영어, 중국어(간체), 스페인어, 스페인어(멕시코), 포르투갈어, 프랑스어, 독일어, 이탈리아어, 일본어, 네덜란드어, 한국어, 스웨덴어, 터키어, 힌디어 | 영어 | 텍스트의 언어 지정 |
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
| RecognizedEntities | 데이터 테이블 | 인식된 엔터티 |
예외
이 작업에는 예외가 포함되지 않습니다.
HTML 콘텐츠 만들기
서식 있는 HTML 콘텐츠를 생성하여 변수에 저장합니다.
이 작업을 통해 사용자는 형식화되고 직관적인 방식으로 HTML 콘텐츠를 생성할 수 있으며 이는 텍스트 변수에 저장됩니다. 그러면 HTML 형식이 필요한 다음 작업에서 이 변수를 사용할 수 있습니다.
이 기능은 주로 'Body' 입력 매개 변수와 관련하여 이메일 전송 작업 '이메일 보내기', 'Exchange 이메일 메시지 보내기' 및 'Outlook을 통해 이메일 메시지 보내기'를 제공합니다. 특히, 생성된 변수는 Body는 HTML 옵션이 활성화된 동안 흐름 후반부에 이어지는 이메일 전송 작업의 'Body' 매개 변수에서 있는 그대로 사용될 수 있습니다.
입력 매개 변수
입력 매개 변수는 내장된 HTML 편집기를 통해 구성됩니다.
HTML 편집기의 초기 보기에서는 렌더링된 HTML 콘텐츠를 즉시 편집할 수 있으며, 링크, 이미지(로컬 경로 또는 URL을 통해) 및 테이블, 동적 콘텐츠에 대한 변수를 삽입하는 기능을 포함하여 맨 위에 있는 도구 모음을 통해 서식 지정 옵션 집합을 제공합니다.
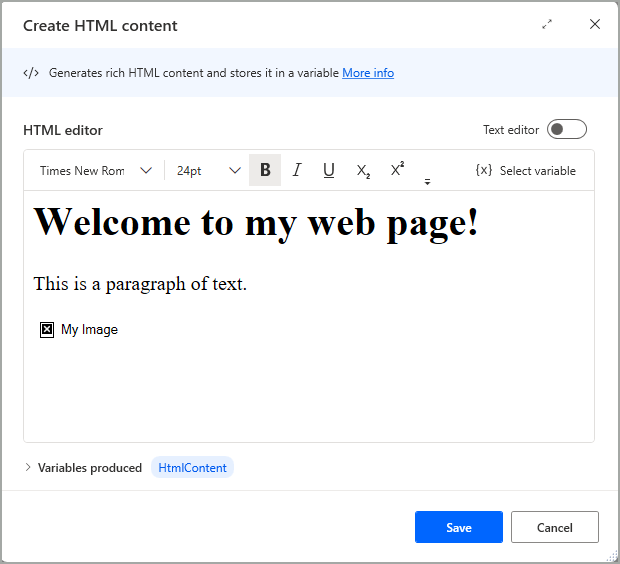
텍스트 편집기 옵션을 활성화하면 해당 요소 태그를 포함하여 HTML 언어를 사용할 수 있는 보기로 전환됩니다.
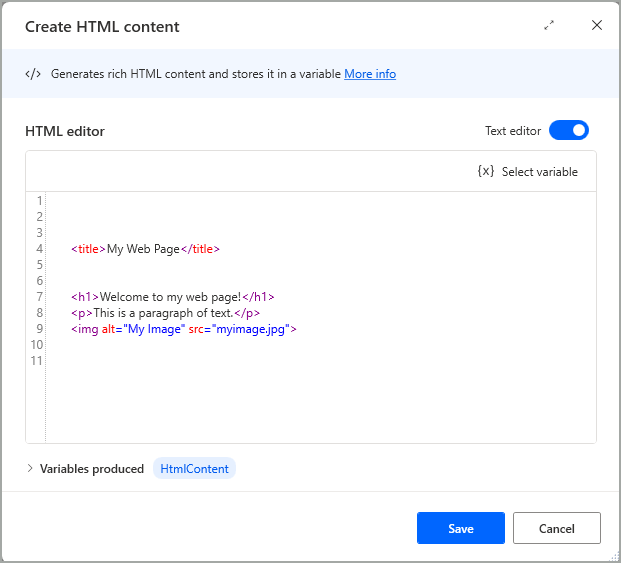
<head> 및 <body> 요소는 HTML 콘텐츠를 렌더링하기 위해 텍스트 편집기에 필요하지 않습니다.
변수 생성됨
| 인수 | Type | Description |
|---|---|---|
HtmlContent |
텍스트 값 | HTML 코드 |
예외
이 작업에는 예외가 포함되지 않습니다.