Transparency note: Content Understanding
What is a Transparency Note?
An AI system includes not only the technology, but also the people who will use it, the people who will be affected by it, and the environment in which it is deployed. Creating a system that is fit for its intended purpose requires an understanding of how the technology works, what its capabilities and limitations are, and how to achieve the best performance. Microsoft’s Transparency Notes are intended to help you understand how our AI technology works, the choices system owners can make that influence system performance and behavior, and the importance of thinking about the whole system, including the technology, the people, and the environment. You can use Transparency Notes when developing or deploying your own system or share them with the people who will use or be affected by your system.
Microsoft's Transparency Notes are part of a broader effort at Microsoft to put our AI Principles into practice. To find out more, see the Microsoft AI principles.
The basics of Azure AI Content Understanding
Introduction
Azure AI Content Understanding ingests unstructured content in any modality such as documents, images, videos, and audio to produce structured outputs from prebuilt or user-defined schemas to best represent task specific scenarios from the content. This output can then be consumed by downstream applications, such as saving it in a database, sending the output to a customer-developed system for reasoning with LLMs (i.e, Retrieval Augmented Generation or RAG), building specific AI/ML models on the data, or used in workflows to automate business processes. Content Understanding will expand the scope of Azure AI Document Intelligence and leverage capabilities from Azure Open AI Service, Azure AI Speech, and Azure AI Vision to support single-modal and multimodal scenarios.
Key terms
| Term | Definition |
|---|---|
| Classify | This is a type of field kind. The field will classify a value from the input data using the field name. An example would be classifying whether the image has defect, or a face has glasses on or not. |
| Confidence value | All Content Understanding output returns confidence values in the range between 0 and 1 for all extracted words and key-value mappings. This value represents the estimate percentage of how many times it correctly extracts the word out of 100 or correctly maps the key-value pairs. For example, a word that's estimated to be extracted correctly 82% of the time results in a confidence value of 0.82. |
| Diarization | Diarization distinguishes between individual speakers in each audio recording by assigning a temporary, anonymous label to each speaker (e.g., GUEST1, GUEST2, GUEST3, etc.) to denote which speaker is speaking in the audio file. All Content Understanding APIs that support transcription also support diarization. |
| Extract | This is a type of field kind. The field will directly extract a value from input data. An example would be extracting dates from invoices or signatures from documents. |
| Face detection | Finds human faces in an image and returns bounding boxes indicating where the faces are Face detection models alone do not find individually identifying features, only a bounding box marking the entire face. For all the faces detected, Face ID is assigned based on embeddings. Please refer to the Face detection concept documentation for more information. |
| Face grouping | After the faces are detected, the identified faces are filtered into local groups. If a person is detected more than once, more observed face instances are created for this person. Please refer to [Face grouping documentation](/azure/ai-services/computer-vision/overview-identity" \l "group-faces) for more information. |
| Generate | This is a type of field kind. The field will generate a value from parent field content. An example would be generating scene description from videos or summarizing from a call audio. |
| Schema | Schema is the term we use for field names and descriptions that customers need to provide for us to extract values from the input. Content Understanding provides a set of prebuilt schemas to fit your scenarios. Depending on the scenario, Content Understanding has a pre-defined list of fields that will be filled out based on the input. You can use these prebuilt schemas to get started on your project faster without having to define the fields yourself. |
| Transcription | Content Understanding’s automated speech-to-text output feature, sometimes called machine transcription or automated speech recognition (ASR). Transcription uses Azure AI Speech and is fully automated. All Content Understanding APIs that support transcription also support diarization. |
Capabilities
System behavior
Azure AI Content Understanding is a cloud-based Azure AI service that uses a variety of AI/ML models (such as those available through Azure OpenAI Service, Azure Face Service, and Azure Speech) to extract, classify and generate fields from a customer’s input file. Content Understanding does not support integrating any models that customers bring in.
Content Understanding first extracts the content into a structured output. It then uses a large language model (LLM) to generate fields and assign confidence scores to applicable fields.
Currently, Content Understanding can ingest data of the following types: document, image, text, video, and audio. Depending on the type of data the user uploads, Content Understanding will automatically suggest common prebuilt schemas users can get started with. Users also have the choice to customize the schema themselves, allowing for a fuller data ingestion capability. In the case where user uploads harmful content, Content Understanding will issue a warning in the output to let the users know that the input file contains harmful content, but it will still output the fields.
The goal of the service is to provide a normalized, task specific representation of the input data to enable extractive and generative scenarios for customers while providing a consistent experience across modalities. Note that Content Understanding is not intended to support ungrounded inferencing, and it will only generate output based on the information and context given by the users.
Note
Face blurring
For inputs to GPT-4 Turbo with Vision and GPT-4o that contain images or videos of people, the system will first blur faces prior to processing to return the requested results. Blurring helps protect the privacy of the individuals and groups involved. Blurring shouldn't affect the quality of your completions, but you might see the system refer to the blurring of faces in some instances.
Important
Any identification of an individual is neither the result of facial recognition nor the generation and comparison of facial templates. The identification is a result of training the model to associate images of an individual with the same name through image tagging, whereby the model returns the name with any subsequent image inputs of that individual. The model can also take contextual cues other than the face, which is how the model can still associate the image with an individual even if the face is blurred. For example, if the image contains a photo of a popular athlete wearing their team’s jersey and their specific number, the model can still detect the individual based on the contextual cues.
Limited Access to Azure AI Content Understanding
The Face grouping feature in Content Understanding is a Limited Access service and registration is required for access to it. For more information, see Microsoft’s Limited Access Policy and access the Face API registration. Certain features are only available to Microsoft managed customers and approved partners, and only for certain use cases selected at the time of registration. Note that facial detection, facial attributes, and facial redaction use cases do not require registration.
Note
On June 11, 2020, Microsoft announced that it will not sell facial recognition technology to police departments in the United States until strong regulation, grounded in human rights, has been enacted. As such, customers may not use facial recognition features or functionality included in Azure Services—such as Face, Video Indexer, or Content Understanding—if a customer is, or is allowing use of such services by or for, a police department in the United States.
Use cases
Intended uses
Here are some examples of when you might use Content Understanding.
- Tax process automation: You can utilize Content Understanding’s document extraction feature to extract fields from tax forms. Regardless of different templates, you will be able to extract key data from tax forms to generate a unified view of information that results in tax process automation.
- Call center post-call analytics: Businesses can generate insights from call recordings. Audio input will be transformed into text transcription output, which can be used to extract valuable insights that leads to improved call center efficiency and customer experience.
- Marketing Automation and DAM (Digital Asset Management): To build a media asset management solution, you can use Content Understanding to extract fields defined in schema from images and videos to extract insights to enhance the relevance of targeted advertising.
- Content search and discovery with RAG (Retrieval Augmented Generation): Customers who need to search and discover content of any modality (such as text, images, audio, video, or mixed media,) based on their content, metadata, or features can use the structured output from Content Understanding to enable downstream RAG scenarios.
- Content or media summarization: For example, a media company could use Content Understanding to generate a summary and highlights of the sports event.
- Chart and graph understanding: Financial forms or academic journals that contain charts and graphs are usually hard to understand when only the text is being extracted. Content Understanding solves the problem by interpreting the charts and graphs in the context of the given document or image itself, and users can easily extract information they want such as the type of chart or graph, summary, and overall meaning.
Considerations when choosing other use cases
Please consider the following factors when you choose a use case:
- Avoid scenarios where use or misuse could result in physical or psychological harm. For example, using Content Understanding to diagnose patients or prescribe medications can cause significant harm.
Caution
Content Understanding is not designed, intended, or made available as a medical device, and is not designed or intended to be a substitute for professional medical advice, diagnosis, treatment, or judgment, and should not be used to replace or substitute professional medical advice, diagnosis, treatment, or judgment.
- Not suitable for biometric identification or verification. For example, Content Understanding was not designed or intended for the unique identification or verification of individuals based on their facial geometry, voice patterns, or other physical, physiological, or behavioral characteristics.
Important
If you are using Microsoft products or services to process Biometric Data, you are responsible for: (i) providing notice to data subjects, including with respect to retention periods and destruction; (ii) obtaining consent from data subjects; and (iii) deleting the Biometric Data, all as appropriate and required under applicable Data Protection Requirements. "Biometric Data" will have the meaning set forth in Article 4 of the GDPR and, if applicable, equivalent terms in other data protection requirements. For related information, see Data and Privacy for Face.
- Avoid use for tracking people in real world contexts. Examples include using Content Understanding for surveillance of individuals in real world contexts or using Content Understanding to verify that individuals pictured in separate locations are the same person. This recommendation does not apply to using Context Understanding for creative purposes, like to find different scenes of a move with the same actor.
- Avoid scenarios where use or misuse of the system could have a consequential impact on life opportunities or legal status. Examples include scenarios where the use of Content Understanding could affect an individual's legal status, legal rights, or their access to credit, education, employment, healthcare, housing, insurance, social welfare benefits, services, opportunities, or the terms on which they're provided. Consider incorporating meaningful human review and oversight to help reduce the risk of harmful outcomes.
- Carefully consider use cases in high stakes domains or industry. Examples include but are not limited to healthcare, medicine, finance, or legal.
- Avoid use for task-monitoring systems that can interfere with privacy. Content Understanding’s underlying AI models were not designed to monitor individual patterns to infer intimate personal information, such as an individual's sexual or political orientation.
- Avoid scenarios in which use, or misuse of the system could spread false narratives about sensitive topics or people. Examples include the creation and distribution of misinformation about highly sensitive events or generation of information about real people in circumstances that reflect a false narrative.
- Carefully consider the supported locales and languages: Content Understanding model has different supported locales and languages. For example, within English language itself, there are different locales such as US, UK and Australia, which has differences in how the time is formatted, as well as spellings for some words. Be sure to carefully check the officially supported locales and languages for each modality.
- Avoid use where a human in the loop or secondary verification method is not available. Fail-safe mechanisms (e.g., a secondary method being available to the end user if the technology fails) help prevent denial of essential services or other harms due to errors in output.
- Not suitable for scenarios where up-to-date, factually accurate information is crucial unless you have human reviewers or are using the models to search your own documents and have verified suitability for your scenario. Content Understanding does not have information about events that occur after its training date, likely has missing knowledge about some topics, and might not always produce factually accurate information.
- Conversation transcription with speaker recognition: Content Understanding is not designed to provide diarization with speaker recognition, and it cannot be used to identify individuals. In other words, speakers will be presented as Guest1, Guest2, Guest3, and so on, in the transcription. These will be randomly assigned and may not be used to identify individual speakers in the conversation. For each conversation transcription, the assignment of Guest1, Guest2, Guest3, and so on, will be random.
- Legal and regulatory considerations. Organizations need to evaluate potential specific legal and regulatory obligations when using Content Understanding. Content Understanding is not appropriate for use in every industry or scenario. Always use Content Understanding in accordance with the applicable terms of service and the relevant codes of conduct, including the Generative AI Code of Conduct.
- Legal and regulatory considerations: Organizations need to evaluate potential specific legal and regulatory obligations when using any AI services and solutions, which may not be appropriate for use in every industry or scenario. Additionally, AI services or solutions are not designed for and may not be used in ways prohibited in applicable terms of service and relevant codes of conduct.
Limitations
Technical limitations, operational factors, and ranges
As with all AI systems, there are some limitations to Content Understanding that customers should be aware of.
If highly disturbing input files are uploaded to Content Understanding, it can return harmful and offensive content as part of the results. To mitigate this unintended result, we recommend that you control access to the system and educate the people who will use it about appropriate use.
Face grouping
Faces are blurred before the image or video is sent to the model for analysis thus inference on faces, such as emotion, won’t work in either image or video. Only video modality supports face grouping which only provides groups of similar faces without any additional analysis.
Important
Face grouping feature in Content Understanding is limited based on eligibility and usage criteria. in order to support our Responsible AI principles. Face service is only available to Microsoft managed customers and partners. Use the Face Recognition intake form to apply for access. For more information, see the Face limited access page.
Document
Document extraction capability is heavily dependent on the way you name the fields and description of the fields. Also, the product forces grounding – anchoring outputs in the text of the input documents – and will not return answers if they cannot be grounded. Therefore, in some cases, the value of the field may be missing. Due to the nature of the grounded extraction, the system will return content from the document even if the document is incorrect or the content is not visible to the human eye. Documents should also have a reasonable resolution, where the text is not too blurry for the Layout model to recognize.
Video
Content Understanding is not intended to replace the full viewing experience of videos, especially for content where details and nuances are crucial. It's also not designed for summarizing highly sensitive or confidential videos where context and privacy are paramount.
- Video quality: Always upload high-quality video and audio content. The recommended maximum frame size is HD and frame rate is 30 FPS. A frame should contain no more than 10 people. When outputting frames from videos to AI models, only send around one frame per second. Processing 10 or more frames might delay the AI result. At least 1 minute of spontaneous conversational speech is required to perform analysis. Detecting non-speech audio signals like sound effects and singing is not supported.
- Lower accuracy of the generated insights might occur when faces recorded by cameras that are high-mounted, down-angled or with a wide field of view (FOV) may have fewer pixels.
- Detectors may misclassify objects in videos that are in an overhead view as they were trained with a frontal view of objects.
- Non-English languages: Content Understanding was primarily tested and optimized for the English language. When applied to non-English languages, the accuracy and quality of the summaries may vary. To mitigate this limitation, users employing the feature for non-English languages should verify the generated summaries for accuracy and completeness.
- Videos with multiple languages: If a video incorporates speech in multiple languages, the Textual Video Summary may struggle to accurately recognize all the languages featured in the video content. Users should be aware of this potential limitation when utilizing the Textual Video Summarization feature for multilingual videos.
- Highly specialized or technical videos: Video Summary AI models are trained on a wide variety of videos, including news, movies, and other general content. If the video is highly specialized or technical, the model might not be able to accurately extract the summary of the video.
- Videos with poor audio quality nor (optical character recognition) OCR: Textual Video Summary AI models rely on audio and other insights to extract the summary from the video, or on OCR to extract the text appearing on screen. If the audio quality is poor and there's no identified text, the model might not be able to accurately extract the summary from the video.
- Videos with low lighting or fast motion: Videos that are shot in low lighting or have fast motion might be difficult for the model to process the insights, resulting in poor performance.
- Videos with uncommon accents or dialects: AI models are trained on a wide variety of speech, including different accents and dialects. However, if the video contains speech with an accent or dialect that isn't well represented in the training data, the model might struggle to accurately extract the transcript from the video.
Audio
For audio files, you may need to specify a locale for each audio input. The locale must match the actual language that's spoken in an input voice. Content Understanding supports automatic language detection as well for some use cases. For more information, see the list of supported locales.
- Acoustic quality: Speech to text–enabled applications and devices may use a wide variety of microphone types and specifications. Unified speech models have been trained on various voice audio device scenarios, such as telephones, mobile phones, and speaker devices. Voice quality might be degraded by the way a user speaks into a microphone, even if they use a high-quality microphone. For example, if a speaker is located far from the microphone, the input quality may be too low. A speaker who is too close to the microphone could also cause audio quality deterioration. These cases, as well as any cases where it causes the audio file quality to be degraded can adversely affect the accuracy of speech to text.
- Non-speech noise: If an input audio contains a certain level of noise, accuracy is affected. Noise that comes from audio devices that are used to make a recording, or audio input itself might contain noise, such as background or environmental noise.
- Overlapped speech: There might be multiple speakers within range of an audio input device, and they might speak at the same time. Audio files that have other speakers voice recorded in the background while the main speaker is recording also results in overlapped speech file. In addition, although there is no limitation on the numbers of speakers in the conversation, the system performs better when the number of speakers is under 30.
- Vocabularies: If a word that doesn't exist in a model appears in the audio, the result is an error in transcription.
- Accents: Even within one locale, such as in English - United States (en-US), many people have different accents. Very specific accents might also lead to an error in transcription.
- Mismatched languages or locales: If you specified English - United States (en-US) for an audio input, but a speaker spoke in Swedish, for example, accuracy would be reduced.
- Insertion errors: At times, the model can produce insertion errors in the presence of noise or soft background speech.
Image
- Object Recognition: Recognition of certain ambiguous products may not be accurate if it cannot be recognized by the model. Abstract concepts that do not correspond to the image, for example, gender and emotion, may not be recognized as well.
System performance
Performance metrics differ for each modality within Content Understanding. Each modality will have different industry standards for measuring AI performance.
One common metric we provide in Content Understanding across all modality is the confidence score for the fields. As of now, only fields kind of “extract” and “generate” will have confidence scores.
A distinctive feature of Content Understanding is its support for grounding and confidence scores, currently available only for the document modality but planned for future expansion. Grounding in documents includes page numbers and bounding boxes for extracted values, aiding the user experience by highlighting locations for human review and correction. Confidence scores, ranging from 0 to 1, estimate the accuracy of extracted values based on analyzed or training documents, with higher scores indicating greater confidence. For guidelines on using confidence scores, refer to the Evaluation section of Content Understanding.
Below are general performance metrics you can utilize for each modality:
Document
Accuracy
Text is composed of lines and words at the foundational level and entities such as names, prices, amounts, company names, and products at the document understanding level.
Word-level accuracy
A measure of accuracy for OCR is word error rate (WER), or how many words were incorrectly output in the extracted results. The lower the WER, the higher the accuracy.
WER is defined as:
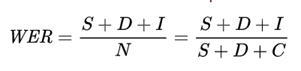
Where:
| Term | Definition | Example |
|---|---|---|
| S | Count of incorrect words ("substituted") in the output. | "Velvet" gets extracted as "Veivet" because "l" is detected as "i." |
| D | Count of missing (“deleted”) words in the output. | For the text "Company Name: Microsoft," Microsoft isn't extracted because it's handwritten or hard to read. |
| I | Count of nonexistent ("inserted") words in the output. | "Department" gets incorrectly segmented into three words as "Dep artm ent." In this case, the result is one deleted word and three inserted words. |
| C | Count of correctly extracted words in the output. | All words that are correctly extracted. |
| N | Count of total words in the reference (N=S+D+C) excluding I because those words were missing from the original reference and were incorrectly predicted as present. | Consider an image with the sentence, "Microsoft, headquartered in Redmond, WA announced a new product called Velvet for finance departments." Assume the OCR output is " , headquartered in Redmond, WA announced a new product called Veivet for finance dep artm ents." In this case, S (Velvet) = 1, D (Microsoft) = 1, I (dep artm ents) = 3, C (11), and N = S + D + C = 13. Therefore, WER = (S + D + I) / N = 5 / 13 = 0.38 or 38% (out of 100). |
Document and entity-level accuracy At the document level, for example, in the case of an invoice or receipt, an error of only one character in the entire document might be rated insignificant. if that error is in the text that represents the paid amount, the entire invoice or receipt might get flagged as incorrect.
Another metric is entity error rate (EER). It's the percentage of incorrectly extracted entities, such as names, prices, amounts, and phone numbers, out of the total number of the corresponding entities in one or more documents. For example, for a total of 30 words representing 10 names, 2 incorrect words out of 30 equals 0.06 (6%) WER. But if that results in 2 names out of 10 as incorrect, the Name EER is 0.20 (20%), which is much higher than the WER.
Measuring both WER and EER is a useful exercise to get a full perspective on document understanding accuracy.
Video
Accuracy of video analysis depends on several factors including camera placement and the interpretation of the system’s output. The accuracy should be assessed by how closely the mode’s field value results align with the actual content of the video. For instance, when a user looks for entities within a video, it is expected to return a full list of entities found in the video. To evaluate accuracy, specific test datasets, representative of various real-world scenarios and conditions, are used. These datasets include a wide range of video content types and user interaction scenarios.
| Term | Definition |
|---|---|
| True Positive | The system-generated output correctly corresponds to a real event. |
| True Negative | The system correctly does not generate an event when a real event has not occurred. |
| False Positive | The system incorrectly generates/extracts/classifies an output when no real event has occurred. |
| False Negative | The system incorrectly fails to generate an output when a real event has occurred. |
Audio
System performance is measured by these key factors:
- Word error rate (WER)
- Token error rate (TER)
- Runtime latency
A model is considered better only when it shows significant improvements (such as a 5% relative WER improvement) in all scenarios (like transcription of conversation speech, call center transcription, dictation, and voice assistant) while being in line with the resource usage and response latency goals.
For diarization, we measure the quality by using word diarization error rate (WDER). The lower the WDER, the better the quality of diarization.
Image
The accuracy of image analysis is a measure of how well the outputs correspond to actual visual content that is present in images. To measure accuracy for image analysis, you might evaluate the image with your ground-truth data and compare the output of the AI model. By comparing the ground truth with AI-generated results, you can classify events into two kinds of correct ("true") results and two kinds of incorrect ("false") results:
| Term | Definition |
|---|---|
| True Positive | The system-generated output correctly corresponds to ground-truth data. For example, the system correctly tags an image of a dog as a dog. |
| True Negative | The system correctly does not generate results that are not present in the ground-truth data. For example, the system correctly does not tag an image as a dog when no dog is present in the image. |
| False Positive | The system incorrectly generates an output that is absent in the ground-truth data. For example, the system tags an image of a cat as a dog. |
| False Negative | The system fails to generate results that are present in the ground-truth data. For example, the system fails to tag an image of a dog that was present in the image. |
These event categories are used to calculate precision and recall:
| Term | Definition |
|---|---|
| Precision | A measure of the correctness of the extracted content. From an image that contains multiple objects, you find out how many of those objects were correctly extracted. |
| Recall | A measure of the overall content extracted. From an image that contains multiple objects, you find out how many objects were detected overall, without regard to their correctness. |
The precision and recall definitions imply that, in certain cases, it can be hard to optimize for both precision and recall at the same time. Depending on your scenario, you might need to prioritize one over the other. For example, if you are developing a solution to detect only the most accurate tags or labels in the content, such as to display image search results, you would optimize for higher precision. But if you're trying to tag all possible visual content in the images for indexing or internal cataloging, you would optimize for higher recall.
Best practices for improving system performance
In most cases, improving system performance is heavily dependent on the user providing data that is reasonably understandable for Content Understanding to extract values from.
Make sure that the fields generated from the content are relevant to your downstream intended uses. For example, if you want to search for "dogs playing in the backyard," make sure that your field output includes these concepts and update the schema definition like field name and descriptions of the fields to correct it if it does not.
For images, see the following documentation for specific input requirements. Images should have reasonable quality, light exposure and contrast.
For audio, mismatching locales reduces accuracy, so it is important to match input locales to the speakers in the file. Use audio files with reasonable acoustic conditions and avoid files with background noise, side speech, distance to microphone and speaking styles that may adversely affect the accuracy.
Taking into consideration the limitations of each modality with regards to currently supported inputs, languages and locales, and scenarios will also help improve system performance.
For document extraction, however, there are ways to improve the analyzer quality, which is to update or correct the field label results as needed with each document that you are adding to the dataset. Document extraction feature supports in-context learning, so more dataset and accurate field labels will lead to a better system performance in general. For filled-in forms, it is also recommended to use examples that have all the fields filled in and use real-world values that you expect to see for each field.
Evaluation of Content Understanding
Evaluation methods
To create Content Understanding, we prepared datasets that target common customer use cases. These are independently prepared by Microsoft, and we do not use customer data sent to our services for any training or evaluation purposes.
Content Understanding's effectiveness will depend on the specific applications it's used for. Customers should perform their own tests to guarantee the best results.
For example, in document extraction, the service assigns a confidence value from 0 to 1 for each word and field. Running a pilot can help customers determine confidence value ranges and extraction quality. They can then set thresholds, like sending results with confidence values of 0.80 or higher for straight-through processing, and those below for human review.
Evaluation results
To ensure service performance, we regularly conduct evaluations and error analysis, using the results to enhance our offerings. Many of these evaluations are tailored to customer scenarios and help determine constraints like field numbers and training data sizes. These constraints are documented for customer reference. Due to numerous possible scenarios, we can't test everything. For instance, we frequently test financial domains but have less coverage in medical fields.
Fairness considerations
One important dimension to consider when using AI systems, is how well the system performs for different groups of people. Research has shown that without conscious effort focused on improving performance for all groups, AI systems can exhibit varying levels of performance across different demographic factors such as race, ethnicity, gender, and age.
As part of our evaluation of Azure AI Content Understanding, we have conducted an analysis to assess potential fairness harms. We have examined the system's performance across different demographic groups, aiming to identify any disparities or differences that may exist and could potentially impact fairness.
In some cases, there may be remaining performance disparities. It is important to note that these disparities may exceed the target, and we are actively working to address and minimize any potential biases or performance gaps and seek diverse perspectives from a variety of backgrounds.
Regarding representational harms, such as stereotyping, demeaning, or erasing outputs, we acknowledge the risks associated with these issues. While our evaluation process aims to mitigate such risks, we encourage users to consider their specific use cases carefully and implement additional mitigations as appropriate. Having a human in the loop can provide an extra layer of oversight to address any potential biases or unintended consequences.
We are committed to continuously improving our fairness evaluations to gain a deeper understanding of the system's performance across various demographic groups and potential fairness concerns. The evaluation process is ongoing, and we are actively working to enhance fairness and inclusivity and mitigate any identified disparities. You can find more fairness testing related to speech in this documentation.
Evaluating and integrating Image Analysis for your use
When integrating Content Understanding for your use case, knowing that Content Understanding is subject to the Microsoft Generative AI Services Code of Conduct, and Code of Conduct for Azure AI Vision Face will ensure a successful integration.
When you’re getting ready to integrate Content Understanding to your product or features, the following activities help to set you up for success:
- Understand what it can do: Fully assess the potential of Content Understanding to understand its capabilities and limitations. Understand how it will perform in your scenario and context. For example, if you're using audio content extraction, test with real-world recordings from your business processes to analyze and benchmark the results against your existing process metrics.
- Respect an individual's right to privacy: Only collect data and information from individuals from whom you have obtained consent, and for lawful and justifiable purposes.
- Legal and regulatory considerations. Organizations need to evaluate potential specific legal and regulatory obligations when using Content Understanding. Content Understanding is not appropriate for use in every industry or scenario. Always use Content Understanding in accordance with the applicable terms of service and the Microsoft Generative AI Services Code of Conduct.
- Human-in-the-loop: Keep a human in the loop, and include human oversight as a consistent pattern area to explore. This means ensuring constant human oversight of the AI-powered product or feature and to maintain the role of humans in decision-making. Ensure that you can have real-time human intervention in the solution to prevent harm. A human in the loop enables you to manage situations when Content Understanding does not perform as required.
- Security: Ensure your solution is secure and that it has adequate controls to preserve the integrity of your content and prevent unauthorized access.
Learn more about responsible AI
- Microsoft AI principles
- Microsoft responsible AI resources
- Microsoft Azure Learning courses on responsible AI
Learn more about Content Understanding
- Azure OpenAI overview
- Azure AI Document Intelligence overview
- Azure AI Speech overview
- Azure AI Vision overview
- Azure AI Face service overview
- Azure AI Video Indexer overview
Additional transparency notes for underlying services
- Azure OpenAI
- Azure AI Document Intelligence
- Azure AI Speech
- Azure AI Vision
- Azure AI Face
- Azure AI Video Indexer