자습서: 집계 함수 사용
적용 대상: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
집계 함수를 사용하면 여러 행의 데이터를 그룹화하고 요약 값으로 결합할 수 있습니다. 요약 값은 선택한 함수(예: 개수, 최대값 또는 평균 값)에 따라 달라집니다.
이 자습서에서는 다음 작업을 수행하는 방법을 알아봅니다.
이 자습서의 예제에서는 도움말 클러스터에서 공개적으로 사용할 수 있는 테이블을 사용합니다StormEvents. 사용자 고유의 데이터를 사용하여 탐색하려면 사용자 고유의 무료 클러스터를 만듭니다.
이 자습서의 예제에서는 Weather Analytics 샘플 데이터에서 공개적으로 사용할 수 있는 테이블을 사용합니다StormEvents.
이 자습서는 첫 번째 자습서 인 Learn common 연산자의 기초를 기반으로 합니다.
필수 조건
다음 쿼리를 실행하려면 샘플 데이터에 액세스할 수 있는 쿼리 환경이 필요합니다. 다음 중 하나를 사용할 수 있습니다.
- 도움말 클러스터에 로그인 할 Microsoft 계정 또는 Microsoft Entra 사용자 ID
- Microsoft 계정 또는 Microsoft Entra 사용자 ID
- Microsoft Fabric 사용 용량이 있는 패브릭 작업 영역
요약 연산자 사용
요약 연산자는 데이터에 대한 집계를 수행하는 데 필수적입니다. 연산자는 summarize 절에 by 따라 행을 그룹화한 다음 제공된 집계 함수를 사용하여 각 그룹을 단일 행으로 결합합니다.
count 집계 함수를 사용하여 summarize 상태별 이벤트 수를 찾습니다.
StormEvents
| summarize TotalStorms = count() by State
출력
| State(상태) | TotalStorms |
|---|---|
| TEXAS | 4701 |
| KANSAS | 3166 |
| 아이오와주 | 2337 |
| 일리노이주 | 2022 |
| MISSOURI | 2016 |
| ... | ... |
쿼리 결과 시각화
차트 또는 그래프에서 쿼리 결과를 시각화하면 데이터에서 패턴, 추세 및 이상값을 식별하는 데 도움이 될 수 있습니다. 렌더링 연산자를 사용하여 이 작업을 수행할 수 있습니다.
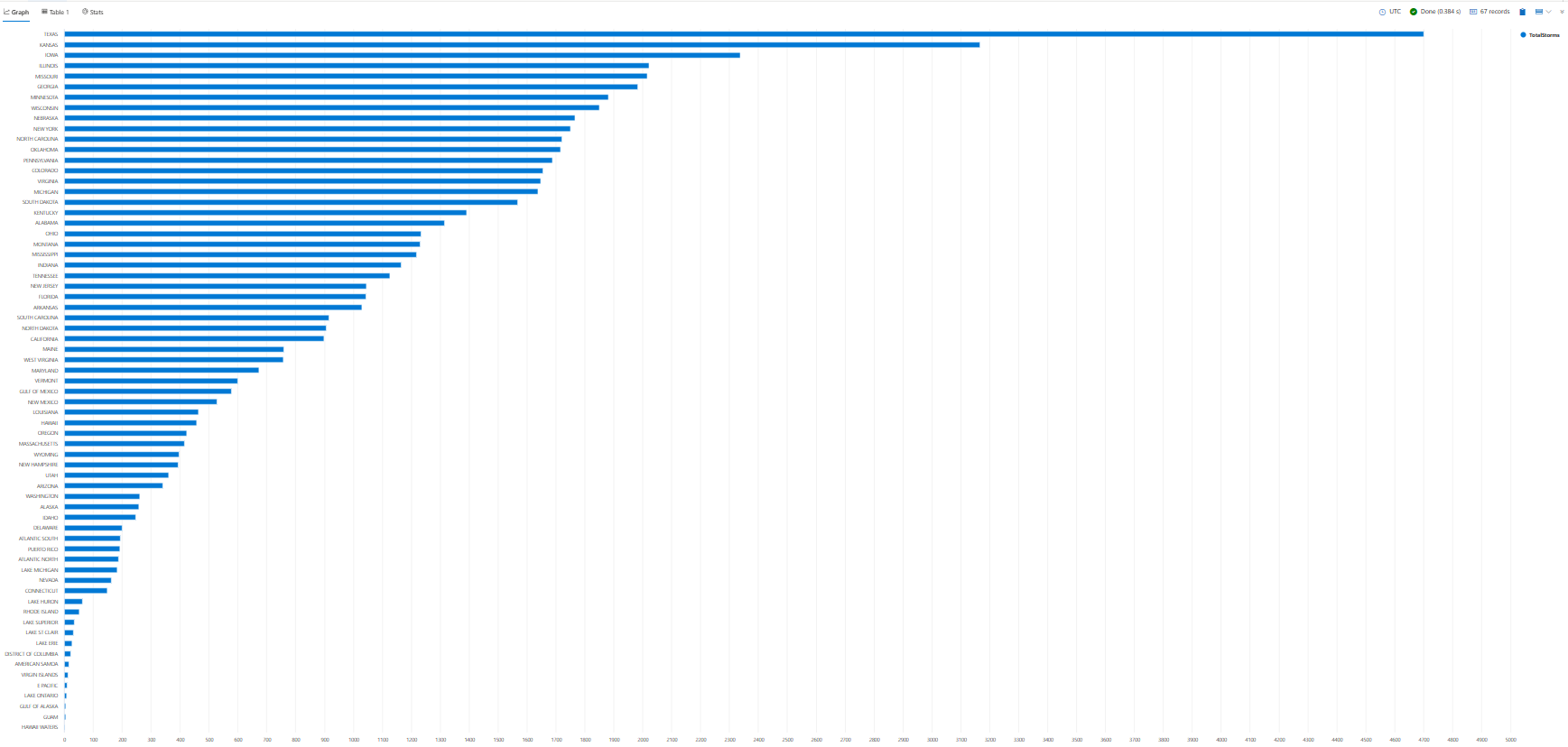
자습서 전체에서 결과를 표시하는 데 사용하는 render 방법의 예제를 볼 수 있습니다. 지금은 가로 막대형 차트에서 이전 쿼리의 결과를 확인하는 데 사용 render 하겠습니다.
StormEvents
| summarize TotalStorms = count() by State
| render barchart
조건부 행 개수
데이터를 분석할 때 countif()를 사용하여 특정 조건에 따라 행 수를 계산하여 지정된 조건을 충족하는 행 수를 파악합니다.
다음 쿼리는 손상을 초래한 폭풍 수를 계산하는 데 사용됩니다 countif() . 그런 다음 쿼리는 연산자를 top 사용하여 결과를 필터링하고 폭풍으로 인한 작물 피해가 가장 많은 상태를 표시합니다.
StormEvents
| summarize StormsWithCropDamage = countif(DamageCrops > 0) by State
| top 5 by StormsWithCropDamage
출력
| State(상태) | StormsWithCropDamage |
|---|---|
| 아이오와주 | 359 |
| 네브래스카주 | 201 |
| 미시시피 | 105 |
| 노스캐롤라이나주 | 82 |
| MISSOURI | 78 |
데이터를 bin으로 그룹화
숫자 또는 시간 값으로 집계하려면 먼저 bin() 함수를 사용하여 데이터를 bin으로 그룹화하려고 합니다. 사용하면 bin() 값이 특정 범위 내에서 분산되는 방식을 이해하고 서로 다른 기간을 비교하는 데 도움이 될 수 있습니다.
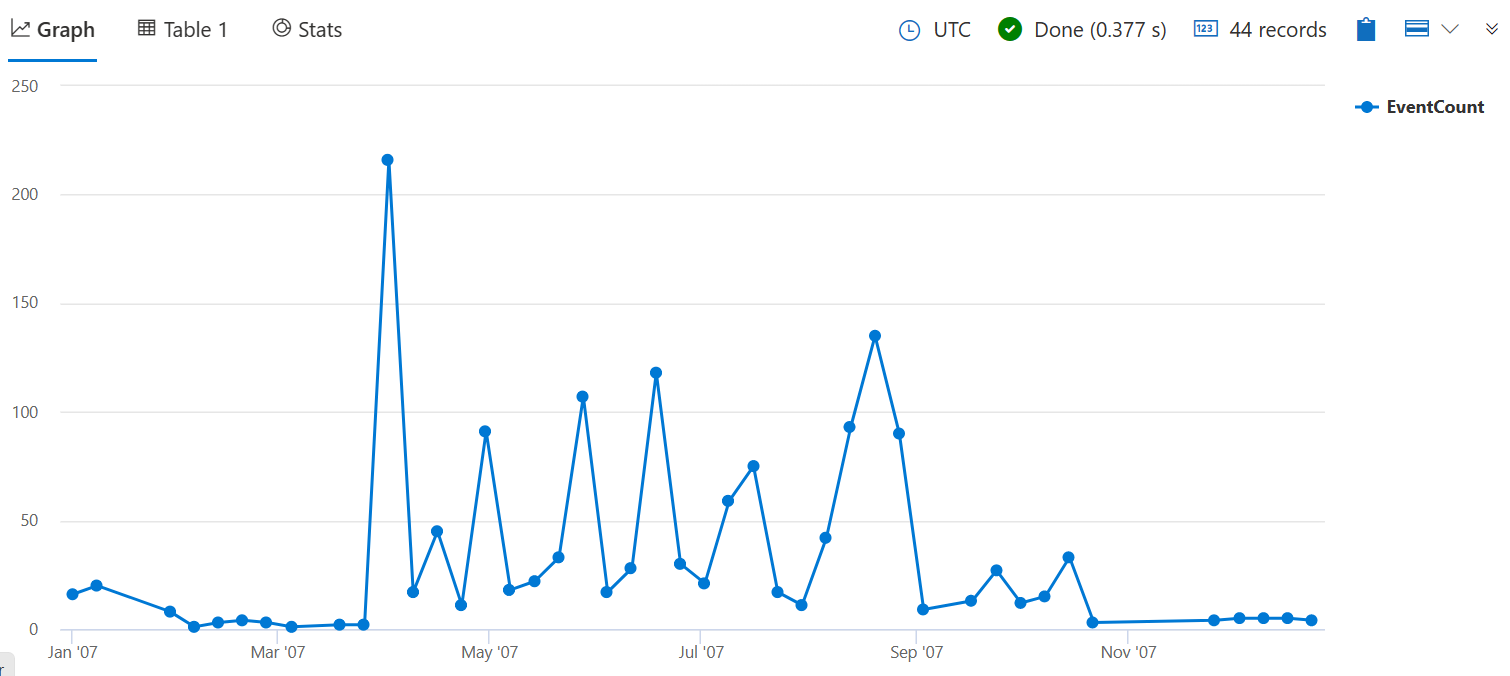
다음 쿼리는 2007년 매주 작물 손상을 일으킨 폭풍의 수를 계산합니다. 함수에 유효한 시간 범위 값이 필요하므로 인수는 7d 1주일을 나타냅니다.
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize EventCount = count() by bin(StartTime, 7d)
출력
| StartTime | EventCount |
|---|---|
| 2007-01-01T00:00:00Z | 16 |
| 2007-01-08T00:00:00Z | 20 |
| 2007-01-29T00:00:00Z | 8 |
| 2007-02-05T00:00:00Z | 1 |
| 2007-02-12T00:00:00Z | 3 |
| ... | ... |
쿼리의 끝에 추가하여 | render timechart 결과를 시각화합니다.
참고 항목
bin() 는 다른 프로그래밍 언어의 floor() 함수와 비슷합니다. 모든 값을 사용자가 제공하는 가장 가까운 모듈러스의 배수로 줄이고 행을 그룹에 할당할 수 있습니다 summarize .
최소, 최대, 평균 및 합계 계산
자르기 손상을 일으키는 폭풍 유형에 대해 자세히 알아보려면 각 이벤트 유형에 대한 min(), max()및 avg() 자르기 피해를 계산한 다음 평균 피해를 기준으로 결과를 정렬합니다.
단일 summarize 연산자에서 여러 집계 함수를 사용하여 여러 계산 열을 생성할 수 있습니다.
StormEvents
| where DamageCrops > 0
| summarize
MaxCropDamage=max(DamageCrops),
MinCropDamage=min(DamageCrops),
AvgCropDamage=avg(DamageCrops)
by EventType
| sort by AvgCropDamage
출력
| EventType | MaxCropDamage | MinCropDamage | AvgCropDamage |
|---|---|---|---|
| 서리/결빙 | 568600000 | 3000 | 9106087.5954198465 |
| Wildfire | 21000000 | 10000 | 7268333.333333333 |
| 가뭄 | 700000000 | 2000 | 6763977.8761061952 |
| 홍수 | 500000000 | 1000 | 4844925.23364486 |
| 뇌우를 동반한 바람 | 22000000 | 100 | 920328.36538461538 |
| ... | ... | ... | ... |
이전 쿼리의 결과는 Frost/Freeze 이벤트가 평균적으로 가장 많은 자르기 손상을 초래했음을 나타냅니다. 그러나 bin() 쿼리는 작물 손상을 입은 이벤트가 대부분 여름철에 일어난 것으로 나타났습니다.
sum()을 사용하여 이전 bin() 쿼리에서 수행한 count() 것처럼 일부 손상을 초래한 이벤트의 양 대신 손상된 작물의 총 수를 확인합니다.
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize CropDamage = sum(DamageCrops) by bin(StartTime, 7d)
| render timechart
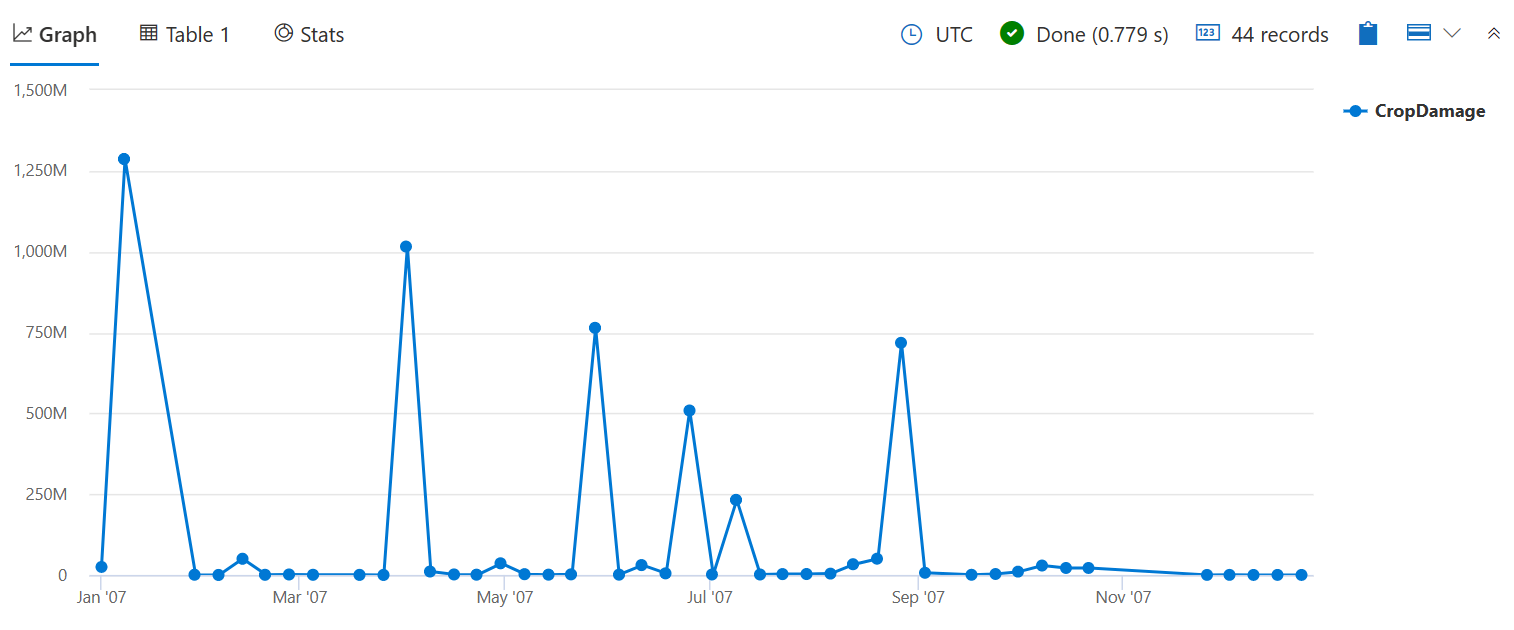
이제 1 월에 작물 손상의 피크를 볼 수 있습니다.
팁
조건부 개수 행 섹션에서 수행한 것처럼 minif(), maxif(), avgif()및 sumif()를 사용하여 조건부 집계를 수행합니다.
백분율 계산
백분율을 계산하면 데이터 내에서 다양한 값의 분포 및 비율을 이해하는 데 도움이 될 수 있습니다. 이 섹션에서는 KQL(Kusto 쿼리 언어)을 사용하여 백분율을 계산하는 두 가지 일반적인 방법을 설명합니다.
두 열을 기준으로 백분율 계산
count() 및 countif를 사용하여 각 상태에서 작물 손상을 일으킨 폭풍 이벤트의 백분율을 찾습니다. 먼저 각 주의 총 폭풍 수를 계산합니다. 그런 다음 각 주에서 작물 손상을 일으킨 폭풍의 수를 계산합니다.
그런 다음 확장 하여 작물 피해가 있는 폭풍의 수를 총 폭풍 수로 나누고 100을 곱하여 두 열 사이의 백분율을 계산합니다.
10진수 결과를 얻으려면 나누기를 수행하기 전에 todouble() 함수를 사용하여 정수 값 중 하나 이상을 double로 변환합니다.
StormEvents
| summarize
TotalStormsInState = count(),
StormsWithCropDamage = countif(DamageCrops > 0)
by State
| extend PercentWithCropDamage =
round((todouble(StormsWithCropDamage) / TotalStormsInState * 100), 2)
| sort by StormsWithCropDamage
출력
| State(상태) | TotalStormsInState | StormsWithCropDamage | PercentWithCropDamage |
|---|---|---|---|
| 아이오와주 | 2337 | 359 | 15.36 |
| 네브래스카주 | 1766 | 201 | 11.38 |
| 미시시피 | 1,218 | 105 | 8.62 |
| 노스캐롤라이나주 | 1721 | 82 | 4.76 |
| MISSOURI | 2016 | 78 | 3.87 |
| ... | ... | ... | ... |
참고 항목
백분율을 계산할 때 나누기의 정수 값 중 하나 이상을 todouble() 또는 toreal()로 변환합니다. 이렇게 하면 정수 나누기로 인해 잘린 결과가 표시되지 않습니다. 자세한 내용은 산술 연산에 대한 형식 규칙을 참조 하세요.
테이블 크기에 따라 백분율 계산
이벤트 유형별 폭풍 수를 데이터베이스의 총 폭풍 수와 비교하려면 먼저 데이터베이스의 총 폭풍 수를 변수로 저장합니다. Let 문은 쿼리 내에서 변수를 정의하는 데 사용됩니다.
테이블 형식 식 문은 테이블 형식 결과를 반환하므로 toscalar() 함수를 사용하여 함수의 count() 테이블 형식 결과를 스칼라 값으로 변환합니다. 그런 다음 백분율 계산에 숫자 값을 사용할 수 있습니다.
let TotalStorms = toscalar(StormEvents | summarize count());
StormEvents
| summarize EventCount = count() by EventType
| project EventType, EventCount, Percentage = todouble(EventCount) / TotalStorms * 100.0
출력
| EventType | EventCount | 백분율 |
|---|---|---|
| 뇌우를 동반한 바람 | 13015 | 22.034673077574237 |
| Hail | 12711 | 21.519994582331627 |
| Flash Flood | 3688 | 6.2438627975485055 |
| 가뭄 | 3616 | 6.1219652592015716 |
| 겨울 날씨 | 3349 | 5.669928554498358 |
| ... | ... | ... |
고유 값 추출
make_set()를 사용하여 테이블의 행 선택을 고유한 값 배열로 전환합니다.
다음 쿼리는 각 상태에서 사망을 일으키는 이벤트 유형의 배열을 만드는 데 사용됩니다 make_set() . 그런 다음 결과 테이블은 각 배열의 Storm 형식 수를 기준으로 정렬됩니다.
StormEvents
| where DeathsDirect > 0 or DeathsIndirect > 0
| summarize StormTypesWithDeaths = make_set(EventType) by State
| project State, StormTypesWithDeaths
| sort by array_length(StormTypesWithDeaths)
출력
| State(상태) | StormTypesWithDeaths |
|---|---|
| 캘리포니아 | ["뇌우 바람","높은 서핑","차가운 / 바람 냉각","강한 바람","립 전류","열","과도한 열","산불","먼지 폭풍","천문학 썰물","조밀 한 안개","겨울 날씨"] |
| TEXAS | ["플래시 홍수","뇌우 바람","토네이도","번개","홍수","얼음 폭풍","겨울 날씨","립 전류","과도한 열","조밀 한 안개","허리케인 (태풍)","추위 / 바람 냉각"] |
| OKLAHOMA | ["플래시 홍수","토네이도","추위/바람 냉각","겨울 폭풍","폭설","과도한 열","열","얼음 폭풍","겨울 날씨","조밀 한 안개"] |
| NEW YORK | ["홍수","번개","뇌우 바람","플래시 홍수","겨울 날씨","얼음 폭풍","극단적 인 추위 / 바람 추위","겨울 폭풍","폭설"] |
| KANSAS | ["뇌우 바람","폭우","토네이도","홍수","플래시 홍수","번개","폭설","겨울 날씨","블리자드"] |
| ... | ... |
조건별 데이터 버킷
case() 함수는 지정된 조건에 따라 데이터를 버킷으로 그룹화합니다. 이 함수는 충족된 첫 번째 조건자의 해당 결과 식을 반환하고, 조건자가 충족되지 않으면 final else 식을 반환합니다.
이 예제에서는 시민이 입은 폭풍 관련 부상 수에 따라 상태를 그룹화합니다.
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| sort by State asc
출력
| State(상태) | InjuriesCount | InjuriesBucket |
|---|---|---|
| ALABAMA | 494 | 대형 |
| 알래스카 | 0 | 부상 없음 |
| AMERICAN SAMOA | 0 | 부상 없음 |
| ARIZONA | 6 | 적은 |
| ARKANSAS | 54 | 대형 |
| 대서양 북부 | 15 | 중간 |
| ... | ... | ... |
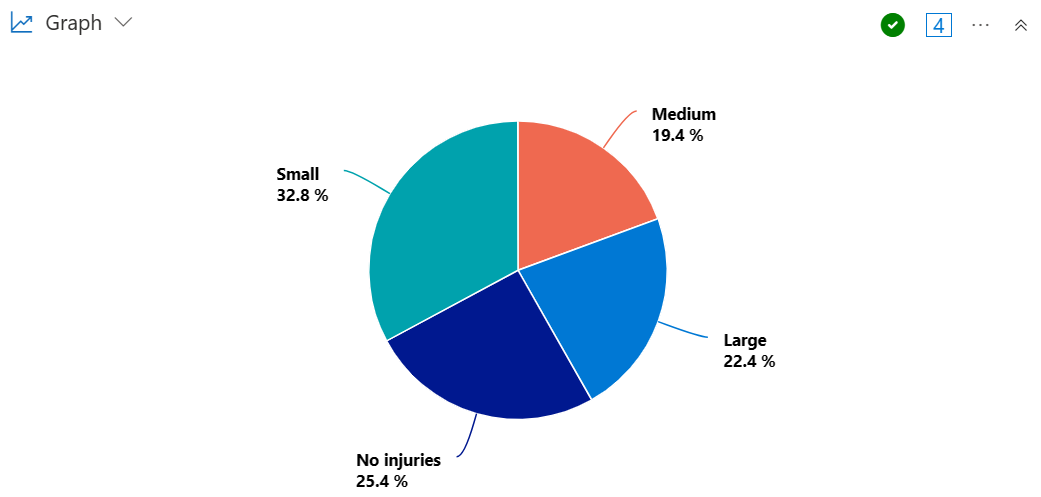
원형 차트를 만들어 큰, 중간 또는 적은 수의 부상을 초래한 폭풍을 경험한 상태의 비율을 시각화합니다.
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| summarize InjuryBucketByState=count() by InjuriesBucket
| render piechart
슬라이딩 윈도우에 대한 집계 수행
다음 예제에서는 슬라이딩 윈도우를 사용하여 열을 요약하는 방법을 보여 줍니다.
이 쿼리는 7일의 슬라이딩 윈도우를 사용하여 토네이도, 홍수 및 산불의 최소, 최대 및 평균 재산 피해를 계산합니다. 결과 집합의 각 레코드는 이전 7일을 집계하고 결과에는 분석 기간의 일별 레코드가 포함됩니다.
다음은 쿼리에 대한 단계별 설명입니다.
- 각 레코드를 기준으로 1일로 비우기
windowStart - bin 값에 7일을 추가하여 각 레코드에 대한 범위의 끝을 설정합니다. 값이 범위를
windowStartwindowEnd벗어나면 값을 적절하게 조정합니다. - 레코드의 현재 날짜부터 시작하여 각 레코드에 대해 7일의 배열을 만듭니다.
- 각 레코드를 1일 간격으로 7개의 레코드로 복제하려면 mv-expand을 사용하여 3단계에서 배열을 확장 합니다.
- 매일 집계를 수행합니다. 4단계로 인해 이 단계는 실제로 이전 7일을 요약합니다.
- 7일간의 조회 기간이 없기 때문에 최종 결과에서 처음 7일을 제외합니다.
let windowStart = datetime(2007-07-01);
let windowEnd = windowStart + 13d;
StormEvents
| where EventType in ("Tornado", "Flood", "Wildfire")
| extend bin = bin_at(startofday(StartTime), 1d, windowStart) // 1
| extend endRange = iff(bin + 7d > windowEnd, windowEnd,
iff(bin + 7d - 1d < windowStart, windowStart,
iff(bin + 7d - 1d < bin, bin, bin + 7d - 1d))) // 2
| extend range = range(bin, endRange, 1d) // 3
| mv-expand range to typeof(datetime) // 4
| summarize min(DamageProperty), max(DamageProperty), round(avg(DamageProperty)) by Timestamp=bin_at(range, 1d, windowStart), EventType // 5
| where Timestamp >= windowStart + 7d; // 6
출력
다음 결과 테이블은 잘립니다. 전체 출력을 보려면 쿼리를 실행합니다.
| Timestamp | EventType | min_DamageProperty | max_DamageProperty | avg_DamageProperty |
|---|---|---|---|---|
| 2007-07-08T00:00:00Z | 토네이도 | 0 | 30000 | 6905 |
| 2007-07-08T00:00:00Z | 홍수 | 0 | 200000 | 9261 |
| 2007-07-08T00:00:00Z | Wildfire | 0 | 200000 | 14033 |
| 2007-07-09T00:00:00Z | 토네이도 | 0 | 100000 | 14783 |
| 2007-07-09T00:00:00Z | 홍수 | 0 | 200000 | 12529 |
| 2007-07-09T00:00:00Z | Wildfire | 0 | 200000 | 14033 |
| 2007-07-10T00:00:00Z | 토네이도 | 0 | 100000 | 31400 |
| 2007-07-10T00:00:00Z | 홍수 | 0 | 200000 | 12,263 |
| 2007-07-10T00:00:00Z | Wildfire | 0 | 200000 | 11694 |
| ... | ... | ... |
다음 단계
이제 일반적인 쿼리 연산자 및 집계 함수에 익숙해졌으므로 다음 자습서를 진행하여 여러 테이블의 데이터를 조인하는 방법을 알아봅니다.